의료는 본질적으로 멀티모달(multimodal) 입니다. 환자를 진료, 진단하고 질병을 치료하기 위해서는 언어, 이미지, 유전체 등 다양한 모달리티의 데이터를 해석하고, 다양한 모달리티를 통해서 환자 및 다른 의료진과 커뮤니케이션 할 수 있어야 합니다. 하지만 지금까지 인공지능은 주로 하나의 모달리티에 대해서만 개발되어 왔습니다.
하지만 여러 기술적 발전에 따라서, 멀티모달 인공지능의 개발이 시도되고 있는데요. 이를 (하나의 모달리티에 대해 speicalized 된 인공지능에 대비해서) 소위 제너럴리스트 인공지능(generalist AI) 라고 부릅니다. 최근에 여러 분야에서 generalist AI 를 개발하려는 시도들이 시작되고 있는데 (대표적인 것이 구글의 PaLM-E), 의료 분야에서도 generalist AI에 대한 개념 최근 제안되기 시작했습니다.
제너럴리스트 의료 인공지능의 조건
작년 4월에는 네이쳐에서 ‘Foundation Models for generalist medical artificial intelligence‘ 라는 제목의 perspective article이 소개되었는데요. (제가 생성형 의료 인공지능 강의를 할 때, 항상 소개해드리는 중요 논문 중의 하나입니다. 이 분야에 관심이 있으시면 꼭 읽어보셔야 합니다.) 이 아티클에서는 GMAI (generalist medical AI)가 갖춰야 할 세 가지 조건을 제시합니다.
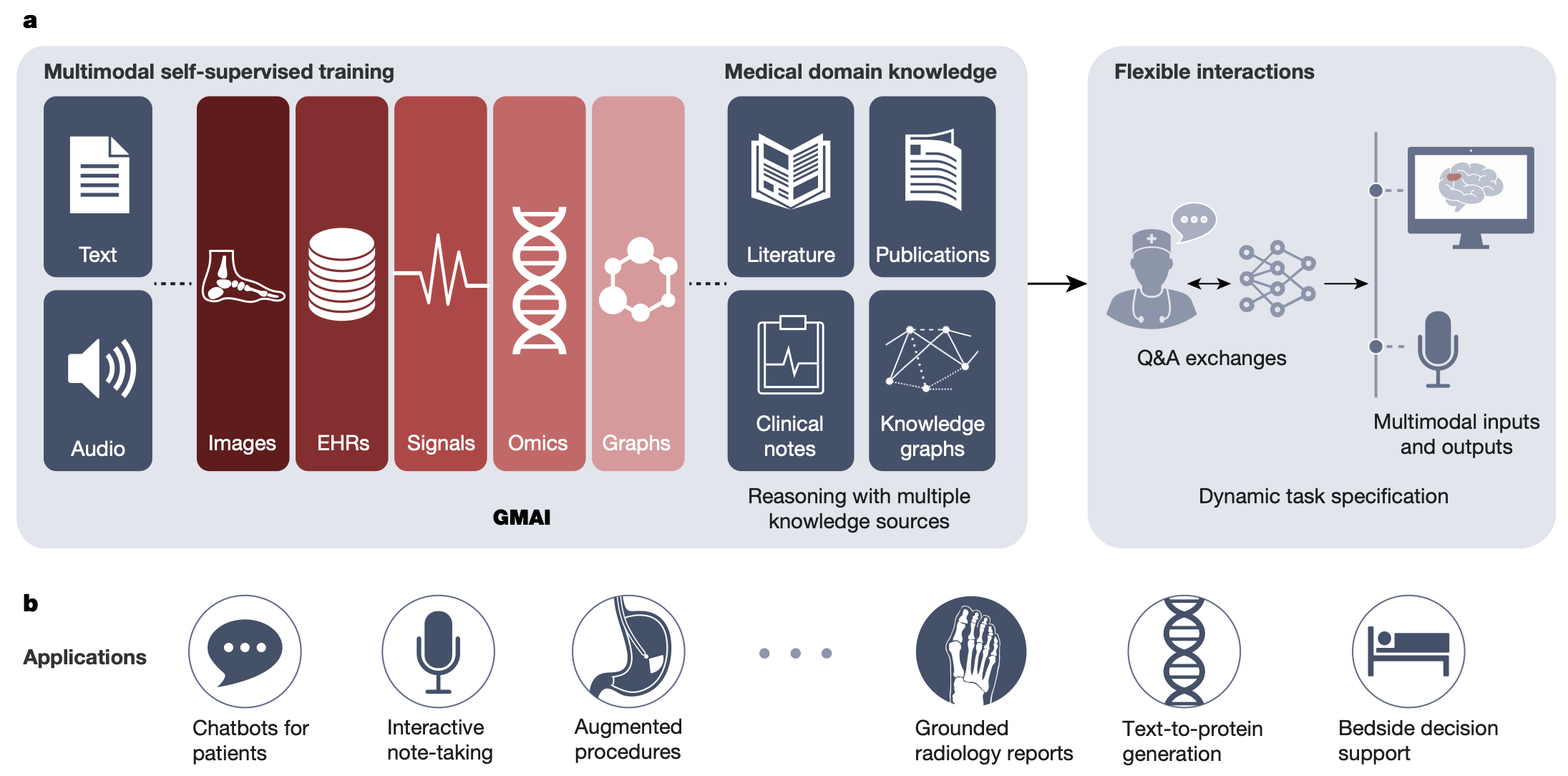
1. Dynamic Task Specification: 처음 보는 문제를, zero-shot이나 few-shot으로 모델의 retraining 없이 해결할 수 있어야 하며, 이 과정이 평이한 영어로 설명하는 정도로 쉬워야 한다.
2. Multimodal, Flexible Combination of Inputs & Outputs: 다양한 조합의 데이터 모달리티를 인풋으로 받아들이고, 아웃풋으로 내어놓을 수 있어야 한다. 예를 들어, 이미지, 텍스트, 음성, 그래프, lab results 등.
3. Medical Domain Knowledge: 의학 지식을 체계적이고 정확하게 표현해야 하며, 처음 접하는 의학적 과업을 추론할 수 있어야 한다. 그 결과를 정확한 의학적 언어로 설명해야 한다.
하지만, 결정적으로 이 Nature 아티클에서는 generalist medical AI 에 대한 ‘개념’만 제시했을 뿐, 실질적인 구현을 하지는 않았습니다. 저는 사실 여기에 나오는 개념이 SF 영화에 나오는 정도의 이야기이고, 구현하기까지는 꽤 오래 걸릴 줄 알았습니다만.. 몇개월 뒤에 구글이 이런 제너럴리스트 의료 인공지능의 효시가 되는 논문을 공개합니다.
제너럴리스트 의료 인공지능의 첫번째 사례: Med-PaLM M
이 ‘제너럴리스트 의료 인공지능을 향하여’ (‘Toward Generalist Biomedical AI’)라는 제목의 논문은 구글이 개발한 멀티모달 의료 인공지능인 Med-PaLM M을 소개하고 있습니다. 원래 이 논문은 2023년 7월에 arxiv에 초안이 먼저 공개되었다가, 지난 2024년 2월에 ENJM AI에 비로소 정식으로 출판되었습니다.
저는 작년에 아카이브의 논문을 읽었을 때, 최종적으로 이 논문이 어디에 출판될지 궁금했는데, 결국 ENJM AI를 택했네요. (초안이 7월에 아카이브에 올라왔다가, 정식 논문으로 반년이나(?) 지난 이후에 출판되었다는 것도 주목할만 합니다. 최근 인공지능 분야에서 6개월의 시간차는 정말 어마어마한 것이기 때문입니다.)
이 논문은 ‘의료’ 분야에서 제너럴리스트 인공지능(generalist AI)의 유의미한 성과를 보여준 첫번째 시도라고 할 수 있습니다. 바로 ‘generalist medical AI’인 Med-PaLM M을 소개하고 있기 때문입니다. 기존의 ‘일반적인’ 멀티모달 AI인 PaLM-E를 의료 분야에 대해서 파인튜닝하여 만든 것이 Med-PaLM M 입니다. (참고로, 의료에 특화된 거대 언어 모델(LLM)인 Med-PaLM1, 2는 PaLM -> Flan-PaLM -> Med-PaLM 1 -> Med-PaLM 2로 발전된 반면, 이름은 비슷하지만 Med-PaLM M은 PaLM + ViT -> PaLM-E -> Med-PaLM M 으로 전혀 다른 발전 경로를 거칩니다.)
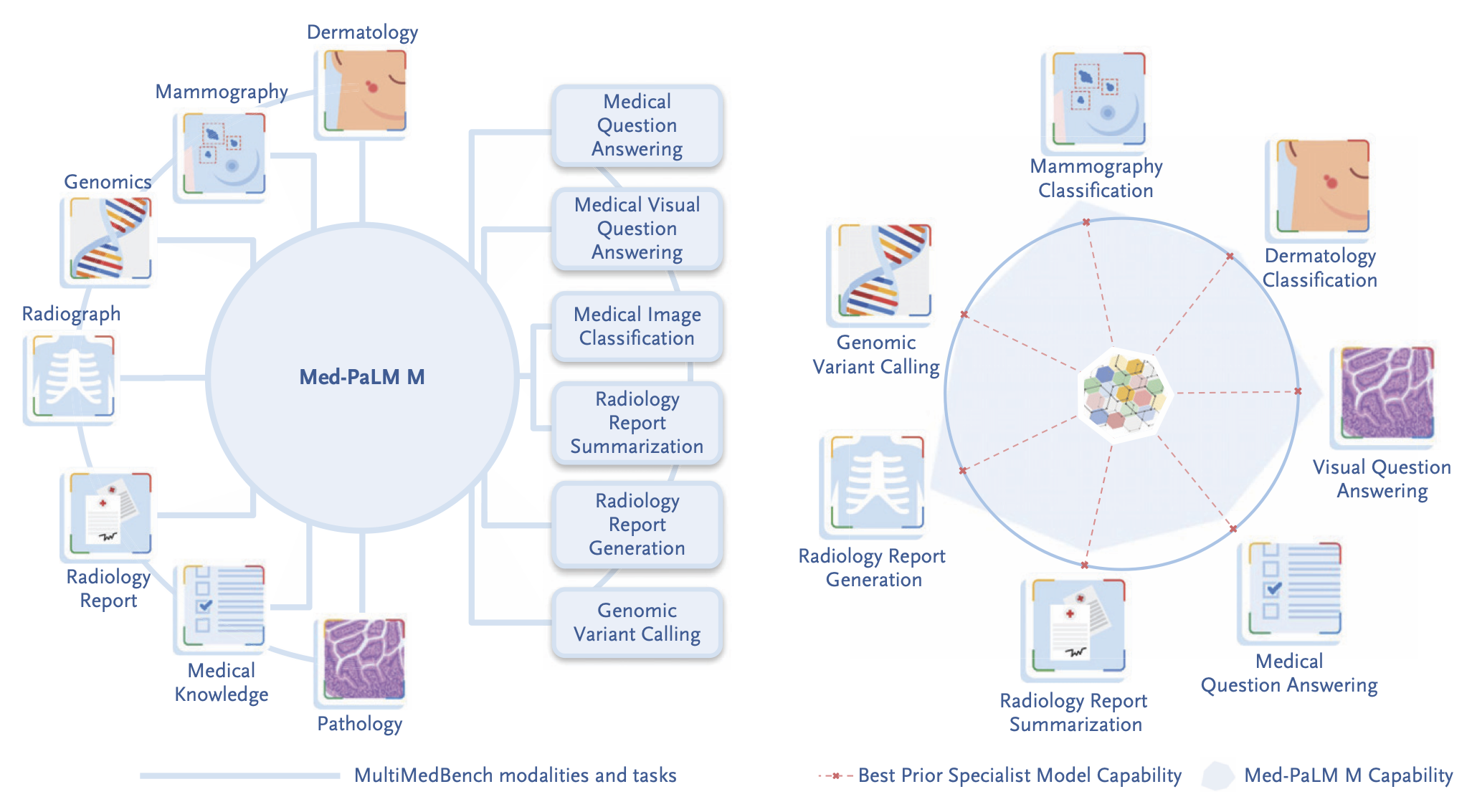
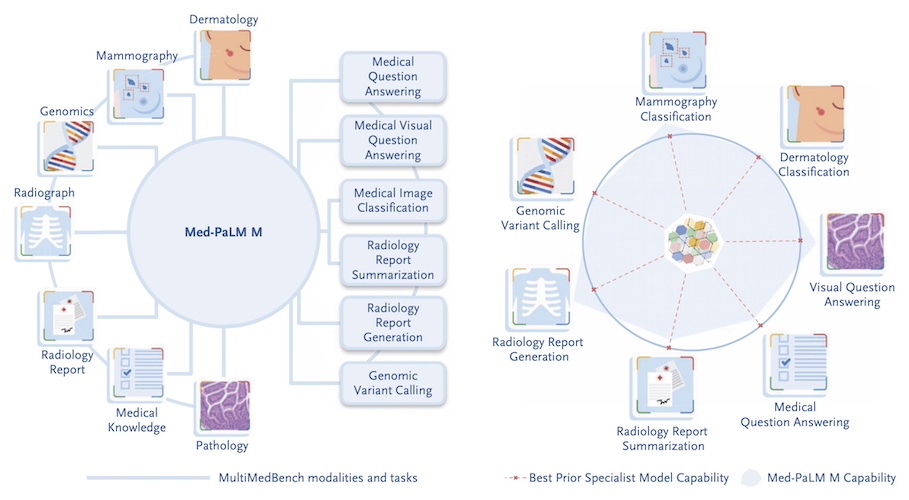
이 Med-PaLM M에 대해서 가장 중요한 점은 하나의 모델을 만들어서, 추가로 파인튜닝하지 않고 (동일한 model weight)에 기반해서, 영상의학과, 피부과, 병리과 등 다양한 진료과에 걸친 14가지의 다양한 의학적인 과업을 다양한 모달리티에 걸쳐서 수행할 수 있었다는 것입니다. 이렇게 하나의 거대한 파운데이션 모델에 기반해서, 모델의 추가적인 파인튜닝이나 재학습 없이 다양한 의료 과업을 수행할 수 있었다는 것은 결국 ‘제너럴리스트 의료 인공지능’의 초기 모델이라고 할 수 있습니다.
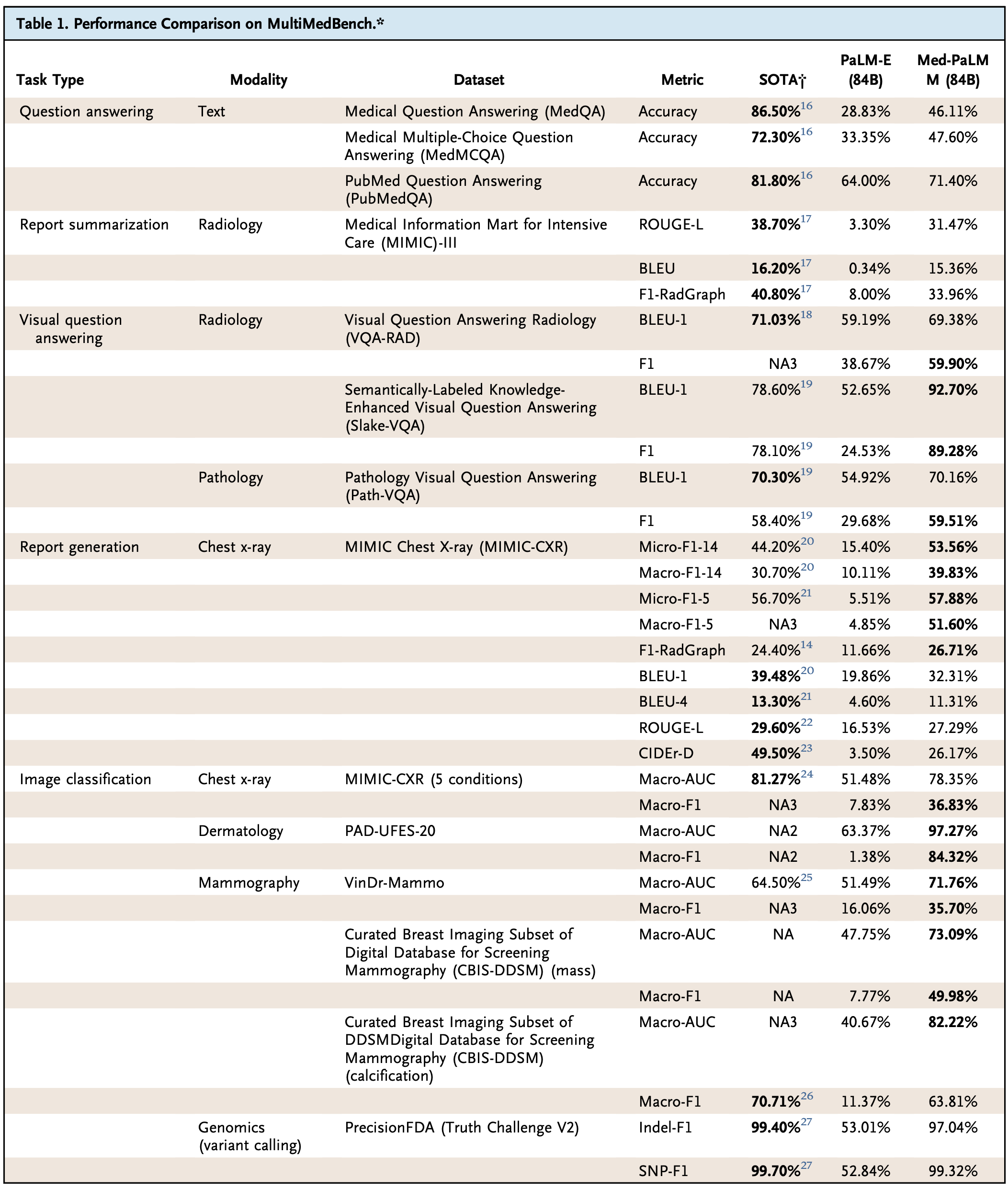
예를 들어, 의학 질문에 답하기, 유방촬영술 및 피부과 (mammography/dermatology) 이미지 분류, 영상의학 레포트 생성/요약, 영상의학 및 병리 이미지를 보고 질문에 답하기 및 심지어는 유전 변이 발굴(genomic variant calling) 에 이르기까지 다양한 과업을 few-shot, one-shot 심지어는 zero-shot으로 해냅니다. 예전에는 이런 개별 과업에 대해서 각각 개별 인공지능을 만들었지만, 이 논문에서는 ‘하나’의 인공지능으로 해결했다는 것이지요. 심지어, 놀랍게도 이런 과업 대부분에 대해서 Med-PaLM M는 개별 문제에 대한 인공지능 중에 가장 좋은 state-of-the-art (SOTA) 인공지능과 비슷하거나 더 나은 결과를 보입니다. (아래 표 참고)
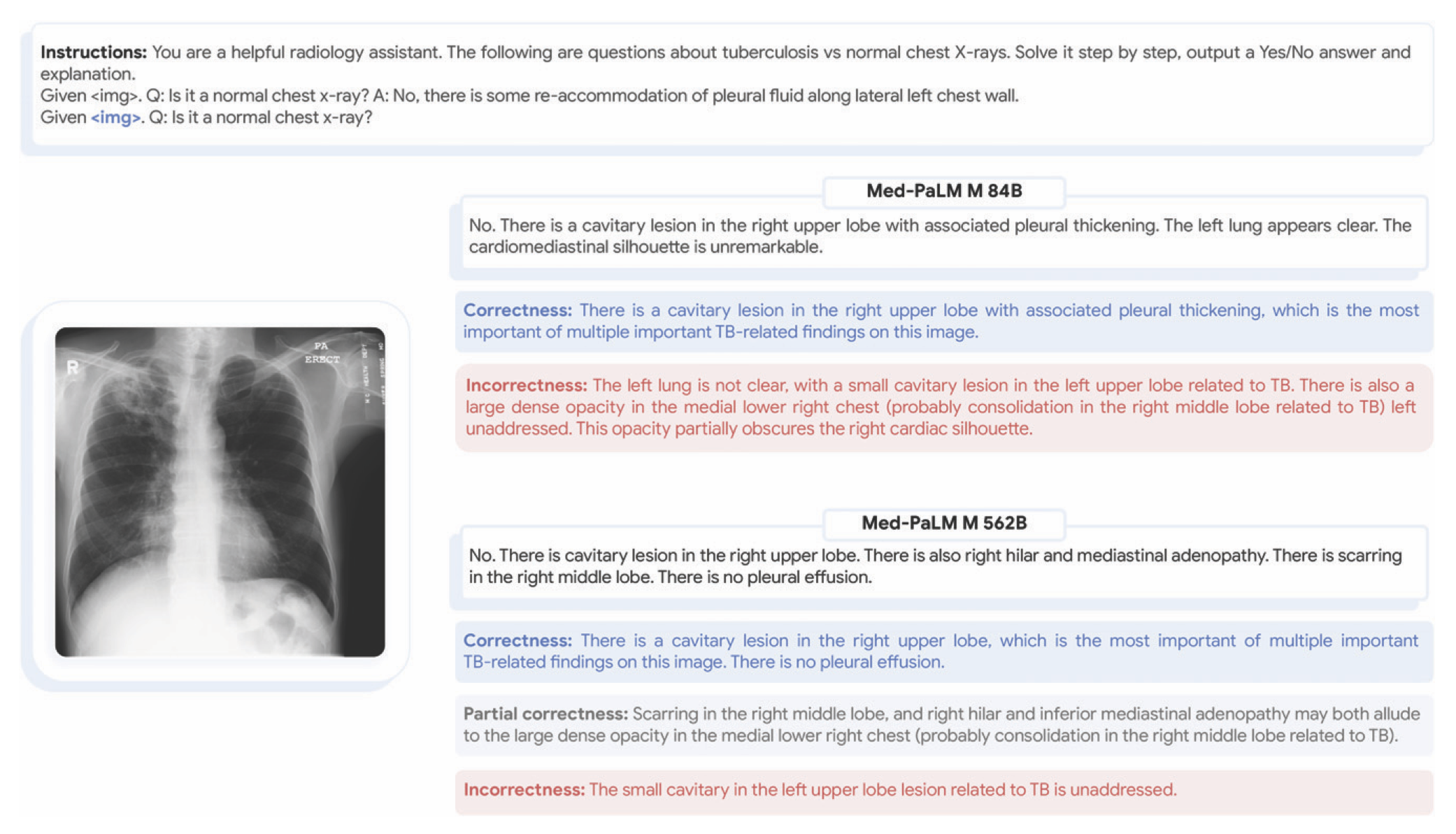
더 나아가서, Med-PaLM M은 학습 과정에서 한번도 보지 못했던 종류의 질병에 대해서도 zero-shot으로 해석해내는 emergent ability(창발)도 보여줍니다. 흉부 엑스레이에서 TB를 detection 해내는 것을 따로 트레이닝 받지 않았으나, 이 문제에 대해서 SOTA에 거의 근접한 수준의 정확성을 보여줬던 것이지요.
또한, 흉부 엑스레이 이미지를 (질병을 특정하지 않고) ‘이상 소견을 이야기 해보라’는 과업을 zero-shot, chain-of-thought(COT)로 테스트해보면 아직은 개선할 점이 많기는 하지만, 그래도 괜찮은 emergent ability를 보여줍니다. (이 분석은 정량적 분석은 없고, 정성적으로만 분석했습니다.)
마지막으로는 Med-PaLM M의 radiology report generation의 퍼포먼스를 인간 영상의학과 의사의 레포트와 비교해보기도 했습니다. 246개의 흉부 엑스레이 영상에 대해서 Med-PaLM M의 세가지 스케일의 모델 (12B, 84B, 562B)이 만든 레포트와 인간 의사의 레퍼런스를 4명의 영상의학과 전문의가 평가한 결과. 약 40% 정도에 대해서는 Med-PaLM M의 레포트를 인간 의사의 레포트보다 더 선호하였습니다.
한계점과 의의
논문에서는 이 연구의 여러 한계와 숙제 또한 언급합니다. 대표적으로 이런 generalist AI를 만들기 위해서는 그에 걸맞는 벤치마크 데이터셋이 있어야 학습을 하는데, 이 부분이 매우 제한적이었다고 이야기 합니다. 연구진들은 자체적으로 MultiMedBench라는 데이터셋을 큐레이션하는 것부터 이 연구를 시작하였는데, 이 데이터셋도 모달리티와 태스크의 다양성, 규모 측면에서 제약이 없지 않았다고 이야기 합니다.
또한 멀티모달 인공지능의 스케일링이 챌린징하다는 것도 제한점으로 지적됩니다. 기존의 LLM에서는 스케일을 키우면 퍼포먼스가 대폭 향상되던 것과는 달리, 이번 Med-PaLM M에서는 이런 효과가 제한적으로 나타납니다. 세가지 스케일(12B, 84B, 562B)의 모델을 비교하였을 때, 562B 보다는 84B의 퍼포먼스가 비슷하거나, 더 잘 나오는 경우가 많았습니다. 이는 vision encoder의 병목현상 때문일 가능성이 높다고 설명하고 있습니다. (84B와 562B 모델로 커질 때 언어 모델만 커지고, vision encoder로는 동일한 22B ViT를 사용.)
그리고 또 한가지 숙제는 Med-PaLM M의 여러 과업에서의 성능을 SOTA 인공지능과 비교할 때의 지표에 관한 것입니다. 이 논문에서는 성능 평가를 위해서 ROUGE, BLEU, F1 같은 기계적인 지표를 주로 사용하고 있습니다.
사실 생성형 인공지능의 성능을 어떻게 평가할 것인지는 아주 어려운 문제입니다. 최근에 식약처를 포함한 많은 규제기관에서도 실제로 고민하고 있는 문제입니다. 거대 언어 모델(LLM)의 경우도 어렵고, 이것이 멀티모달 인공지능으로 확장되면 문제가 더 어려워집니다. 챗봇 형태의 언어모델의 경우에도 성능을 평가하기 위한 지표는 기본적으로 외적 지표(extrinsic metric)과 내적 지표(intrinsic metric)으로 나뉩니다.
내적 지표의 경우, 모델이 생성한 문장을 정답과 비교하여 단순한 언어의 표면적 유사성 등을 기계적으로 측정하게 됩니다. 예를 들어, 기계 번역에 널리 사용되는 BLEU (Bilingual Evaluation Understudy) 메트릭은 모델이 생성한 텍스트가 정답과 얼마나 유사한지 (예를 들어, 서로 일치하는 단어가 몇개나 되는지 등)을 계산합니다. 이런 지표는 자동적으로 계산할 수 있기 때문에 간단하고 정량적인 평가가 가능하지만, 표면적인 언어의 유사성만 보기 때문에 의료 분야 생성형 인공지능을 이것만으로 평가하는 것은 적절하지 않습니다. 이번 연구에서 14개나 되는 과업을 평가하다보니 이런 기계적인 지표를 활용했다는 점은 고려해야겠습니다만, 더 세부적인 성능 평가를 위해서는 더 많은 연구가 필요할 것 같습니다.
이 연구의 가장 큰 의미는 앞서 설명한대로, 제너럴리스트 의료 인공지능의 첫번째 시도라는 점입니다. 모델의 변화 없이 14가지 의학적 태스크에 대해서 꽤 괜찮은 성능을 보였다는 점은, 앞으로 의학에서의 인공지능 개발 및 활용에 대해서 중요한 의미를 가질 것으로 보입니다. (specialist AI 와 generalist AI의 경쟁 혹은 협력 등등)
요즘 의료 분야의 인공지능 논문을 볼 때마다, SF 영화를 보는 것 같다는 느낌을 많이 받는데, 이 논문을 보면서도 여러 놀라움, 흥분, 두려움(?) 등이 함께 들었습니다. 최근 구글은 이 Med-PaLM M 이후에, Gemini 모델에 기반한 Med-Gemini 의 멀티모달 성능에 대해서도 공개한 바 있는데요. 다음에 기회가 되면 이 Med-Gemini 도 다뤄보도록 하겠습니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.