최근에 Nature Medicine에 실린 흥미로운 논문입니다. 의사들이 진료할 때 의학적인 텍스트에 담겨 있는 정보를 추출하고, 이러한 텍스트를 요약하는 것은 중요하고도 많은 시간과 노력이 들어가는 과업인데요. 이러한 clinical text summarization을 (사람) 의료 전문가보다, LLM이 유의미하게 더 잘 한다는 것을 보여주고 있는 논문입니다.
논문의 초반부에는 여러 LLM 중에서 clinical text summarization을 가장 잘 하는 모델과 그 조건을 찾기 위한 내용이 나옵니다. 몇가지 프롬프트와 temperature 등을 메디컬 텍스트에 대해서 기계적으로 테스트하고 (BLEU, ROUGE-L, BERTScore 등의 자연어 처리 분야에서 결과물의 퀄리티를 판단하기 위한 지표를 씁니다),
또한 FLAN-T5, FLAN-UL2, Llama-2, Vicuna, Alpaca, GPT-3.5, GPT-4 등 총 8개 LLM에 대해서 QLoRA, In-context Learning 두 가지 방식을 써서, Radiology Report, Progress Notes, Patient Health Quesitions, Patient-doctor dialogue 의 네 가지 과업에 대해서 테스트하여서, 가장 성능이 좋은 모델을 찾습니다.
이 과정이 상당히 자세하게 서술되어 있는데, 결과적으로는 ‘너는 의료 전문가야’ 하고 역할을 주고, temperature는 낮게 하고, in-context learning으로 GPT-4를 쓰는 것이 가장 성능이 좋아서, 이 조건으로 연구를 진행했다는 다소 맥빠진(?) 중간 결론입니다.
여튼, 본격적으로 GPT-4를 활용해서 Radiology Report, Patients Question, Progress Note를 요약하는 과업에 대한 퍼포먼스를 테스트하였습니다. 총 10명의 의료진이 블라인드로 GPT-4와 의료 전문가가 생성한 요약문을 랜덤하게 100개를 평가해서, 어느 결과물이 어떻게 더 나은지를 판단하였습니다.
참고로, 대조군으로 사용된 인간 의료 전문가의 텍스트 요약은 이 논문에서 따로 만들지는 않았고, MIMIC-CXR, MIMIC-III (Radiology Report), MeQSum (Patients Question), ProbSum (Progress Notes) 등의 기존의 데이터셋을 활용하였습니다.
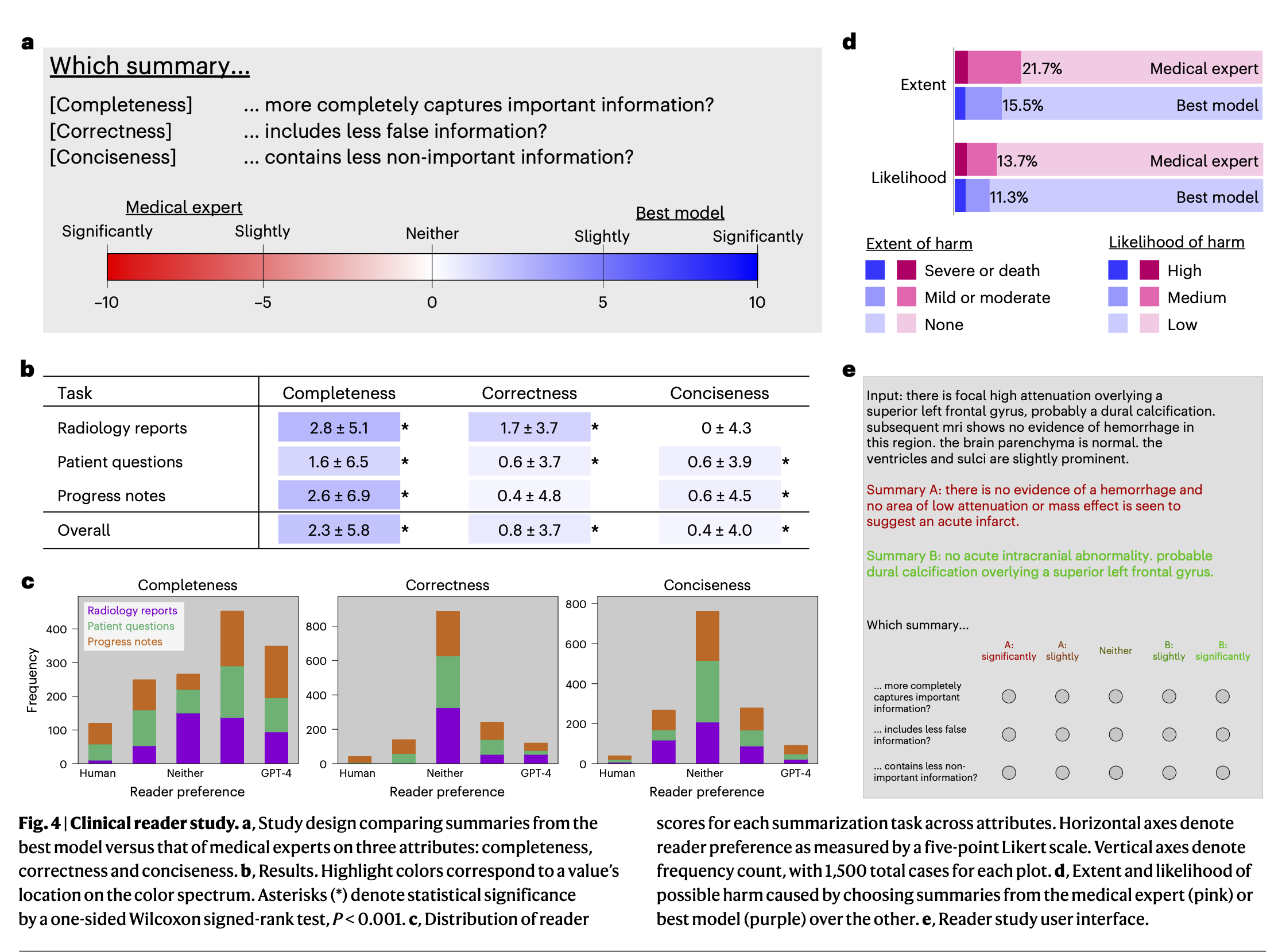
그 결과, GPT-4의 clinical text summarization 성능이 인간 의료 전문가들을 거의 모든 지표에서 유의미하게 더 좋게 나왔습니다. 요약문의 퀄리티는 completeness, correctness, conciseness 세 가지 측면에서 10점 척도로 판단하였는데요. 세 종류의 데이터셋에 대해서, 이 세 측면의 지표가 일부를 제외하면 모두 유의미하게 GPT-4가 더 우수하다고 나옵니다.
즉, GPT-4가 인간 의료 전문가에 비해서 의료 텍스트를 요약할 때 중요한 정보를 덜 빼먹으면서도(completeness), 틀린 정보를 덜 포함시키고(correctness), 동시에 덜 중요한 정보를 적게 포함(conciseness)한다는 것입니다.
Preference 를 테스트 (둘 중에 누가 더 좋냐)를 하였을 때에도 GPT-4가 인간 전문가 대비 더 우수하거나, 적어도 비열등하다고 나오고요. 흥미롭게도 이런 요약문에 잘못된 정보가 포함됨으로 인한 위해도의 정도 (extent of harm), 위해도 가능성 (likelihood of harm)을 평가해본 결과 둘 다 사람이 더 높게 나왔습니다.
LLM의 고질적인 문제이자, 의료 현장에 접목을 주저하게 만드는 할루시네이션(fabricated information)에 대해서도 이 논문에서는 조금 더 세부적으로 분석했는데요. 1) 애매한 정보를 잘못 해석했거나, 2)기존에 있는 정보를 잘못 수정했거나, 3)아예 없는 정보를 새로 만들어낸, 세 가지 유형으로 분류해서 분석했는데요. 이 세 가지의 오류가 GPT의 경우 6%, 2%, 5%, 나온 반면, 인간 전문가에게서는 9%, 4%, 12%의 경우에 나왔습니다. 본문에 보면 ‘LLM 뿐만이 아니라, 사람도 할루시네이션을 저지른다’ 라는 흥미로운 표현이 포함되어 있기도 합니다.
의학적 텍스트에서 중요한 정보를 찾아내고, 요약하는 것은 의료 전문가들의 업무 부담과 번아웃을 줄이기 위해서 중요한 역할을 할 수 있습니다. 현재의 LLM이 완벽하다고는 할 수는 없지만, 적어도 인간 의료 전문가에 비해서는 더 나은 결과를 보여주기 때문에 유의미한 기여를 할 수 있을 것으로도 보입니다.
디스커션에 나오듯이, 이 논문에서는 프롬프트를 아주 간략하게 설정하였는데, 더 세부적인 프롬프트 엔지니어링과 hyperparameter 세팅을 통해서 더 나은 결과를 보여줄 수도 있고, 현실에서는 더 나아가서 이런 결과물을 human operator나, 다른 LLM (클로드?), 혹은 모델 앙상블로 체크하여서 결과물을 더 좋게 만들 수도 있습니다.
한가지 궁금했던 점은, 이 논문에 대조군으로 쓰였던 ‘인간의 요약문’의 퀄리티가 어느 정도로 보장되는지 (일반적인 의료 전문가의 수준을 반영하고 있는지)에 대해서는 크게 언급이 없다는 점입니다. MIMIC-CXR과 같은 기존의 데이터셋의 요약문을 그대로 가져다 쓰는데, 논문의 방법론적으로는 문제 없지만, 현장의 상황을 얼마나 반영하는 것인지에 대한 궁금증이 들기도 했습니다.
An interesting paper recently published in Nature Medicine shows that LLMs are significantly better at clinical text summarization than (human) medical professionals, as they extract the information contained in medical texts and summarize these texts, which is an important and time-consuming task for doctors in their practice.
The first part of the paper is devoted to finding the best model and conditions for clinical text summarization among different LLMs. Authors mechanically test several prompts and temperatures on medical texts.
Authors also use QLoRA and In-context Learning for 8 LLMs (FLAN-T5, FLAN-UL2, Llama-2, Vicuna, Alpaca, GPT-3.5, GPT-4) and test them on 4 tasks (Radiology Report, Progress Notes, Patient Health Questions, Patient-doctor dialog) to find the best performing model.
The process is described in considerable detail, with the somewhat hasty (?) interim conclusion that GPT-4 with “you’re a medical professional” roles, low temperature, and in-context learning performed best.
Authors tested the performance of GPT-4 on the task of summarizing a Radiology Report, Patients Question, and Progress Note. A total of 10 medical professionals blindly evaluated 100 randomized summaries of GPT-4 and human-generated summaries to determine which was better and how.
The results showed that GPT-4 significantly outperformed human medical experts in clinical text summarization on almost all metrics. The quality of the summaries was judged on a 10-point scale of completeness, correctness, and conciseness. For all three datasets, GPT-4 significantly outperformed human medical experts on all but one of these metrics.
In other words, GPT-4 leaves out less important information (completeness), includes less incorrect information (correctness), and simultaneously includes less important information (conciseness) when summarizing medical text compared to human medical experts.
Even when tested for preference (which is better), GPT-4 is better, or at least non-inferior, to human experts. Interestingly, when assessing the extent of harm and likelihood of harm caused by the inclusion of incorrect information in these summaries, both are higher for humans.
The paper also analyzed fabricated information, which is a common problem in LLMs and can make people hesitant to enter the medical field, in more detail, categorizing it into three types: 1) misinterpretation of ambiguous information, 2) modification of existing information, and 3) creation of new information where none existed. These three types of errors were made by GPTs 6%, 2%, and 5% of the time, compared to 9%, 4%, and 12% of the time by human experts. The text also contains an interesting statement: ‘It’s not just LLMs who commit hallucination, people do it too’.
Finding and summarizing important information in medical texts can play an important role in reducing workload and burnout among healthcare professionals. While current LLMs are far from perfect, they show better results, at least compared to human healthcare professionals, so it seems that they can make a significant contribution.
As shown in the discussion, the prompts are very simple in this paper, and more detailed prompt engineering and hyperparameterization could lead to better results, and in practice, these results could be further improved by checking them against a human operator, another LLM (Claude?), or an ensemble of models.
One thing I’m curious about is that the paper doesn’t say much about the quality of the “human summaries” used as controls (whether they reflect the quality of a typical medical professional). The abstracts were taken from existing datasets such as MIMIC-CXR, which is fine methodologically, but it made me wonder how representative they are of the real world.
(Translated Korean to English by DeepL)
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.