구글의 두번째 의료 LLM(Large Language Model)인 Med-PaLM2 에 대한 논문을 리뷰합니다. 지난번 리뷰했던 Med-PaLM 논문에 이은 후속 연구 입니다. Med-PaLM 논문은 arxiv에 작년 12월에 서브밋되었고 (Nature에는 7월에 출판), Med-PaLM2 논문은 arxiv에 지난 5월에 업로드 되었습니다. 이 논문은 아직 peer-reviewed journal 에는 출판되지 않았습니다.
결론적으로 Med-PaLM2는 이전 Med-PaLM에 비해서 더 강력한 퍼포먼스를 보여주며, 많은 경우에는 인간 의사와 비교할만하거나 더 좋은 성과를 보여줍니다. 전반적으로 이전 논문과 논조와 구조가 비슷하지만 (그래서 더 빠르게 읽을 수 있었습니다), 더 다양하고 정교한 evaluation framework 를 제시하고 있습니다.
평가 방법도 더 다양하고, 평가 기준도 더 다양해져서, 다각도로, 특히 실제 의료 현장에서 필요한/중요한 측면들에서 Med-PaLM2 성능의 강력함을 잘 보여주고 있습니다. 특히 이번에는 의료 활용을 위해 민감할 수 있는 측면에 대한 추가적인 robustness 검증과, 의료 전문가들 뿐만이 아니라 비전문가 ‘일반인’ 들에게 이러한 서비스가 어떻게 받아들여질 것인지에 대한 검증이 포함되어 있어서 의미심장합니다.
모델 개발 관련
먼저 Med-PaLM2 이 어떻게 개선되었는지 살펴보겠습니다. 일단 기본 베이스가 되는 LLM자체가 PaLM에서 PaLM2로 업그레이드 되었습니다. 여기에 지난 논문처럼 instruction finetuning, few-shot, COT, self-consistency 등의 기법을 활용하였습니다. (논문 전체적으로 지난 논문의 기법이 많이 인용됩니다. ‘이건 지난 논문에서 한 방식 그대로 했어’, ‘똑같은 프롬프트 썼어’ 하고 퉁 치고 많이 넘어갑니다ㅋㅋ)
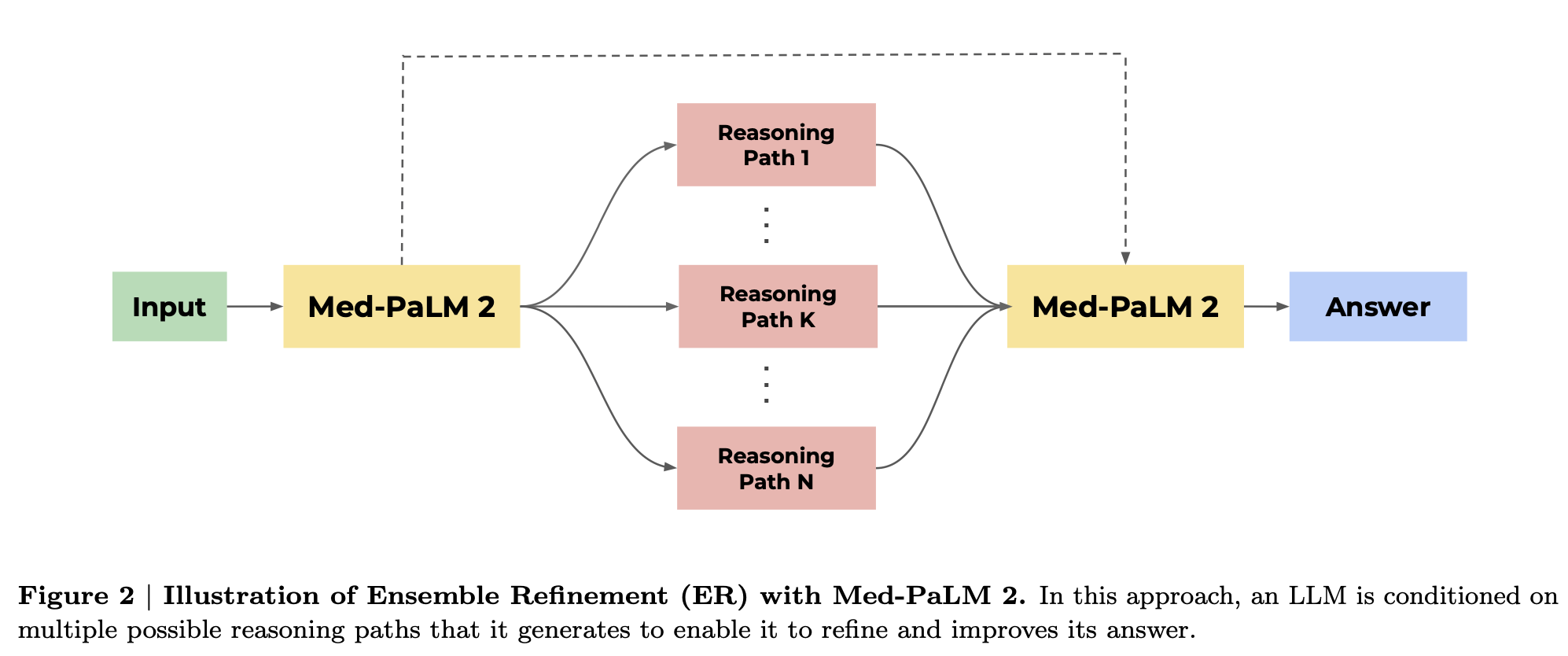
특히, 이번에 새롭게 추가되어 강조되고 있는 기법은 Ensenble refinement (ER) 입니다. (제가 제대로 이해했다면) self-consistency에서 확장된 기법으로 보았는데.. 기본적으로 Med-PaLM2을 여러번 돌려서 여러 버전의 답을 얻고, 이 여러 버전의 답을 다시 Med-PaLM2에 여러번 넣어서 다수결로 최종 답을 결정하는 방식입니다.
기본적으로 LLM에서는 같은 프롬프트에 대해서도 돌릴 때마다 약간씩 다른 답을 내어놓게 되며, 의료라는 것도 본질적으로 하나의 문제 해결방식만 존재하지는 않습니다. 이런 점을 반영한 방식이라고 이해했습니다. 더 나아가, 이렇게 여러번 돌려서 생성된 다양한 답을 다시 LLM에 넣어서 최종 답을 결정하게 하고, 이 방식 자체도 여러번 진행한 것입니다. 논문에서는 첫 단계를 11번, 두번째 단계를 33번 돌렸습니다. (결과적으로 ER로 얻은 답이, few-shot, COT+SC에 비해서 대부분 더 성능이 좋습니다.)
검증 방식
검증 방식은 지난 논문과 비슷한 방식을 쓰지만, 새로운 것들이 많이 추가되었습니다. 일단 객관식 질문에 답을 맞추느냐에 더해서, long-form 질문-답변에 대해서도 의사 뿐만 아니라, ‘일반인 (lay-person)’도 평가를 합니다. 이 부분이 신선한데요. 이런 의료 LLM의 사용자는 궁극적으로 의료 전문가 뿐만 아니라, 의료 전문 지식이 부족한 일반인들도 포함될 것이므로 (이 논문의 저자는 구글입니다), 일반인의 입장에서는 이를 어떻게 평가하는지도 포함하였다고 할 수 있습니다. (물론 평가 기준은 덜 전문적인 잣대로 평가되었고요.)
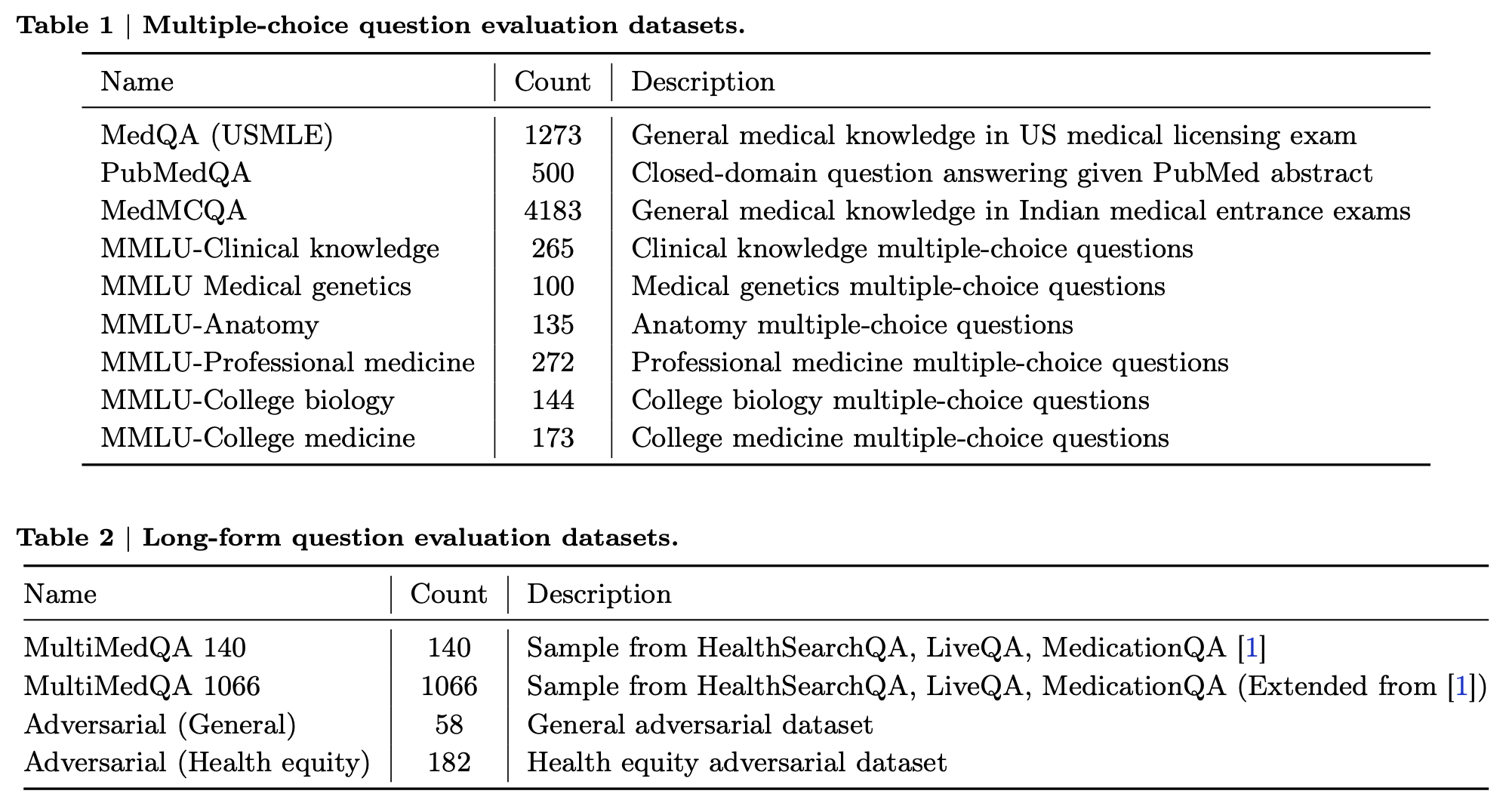
또 한 가지 흥미로운 점은 의도적으로 ‘적대적인 질문 (adversarial questions)’ 데이터셋을 만들어서 평가했다는 점입니다. 적대적인 질문 데이터셋은 또 두 가지로 나뉩니다. 한가지는 일반적인 적대적 질문으로, 약물, 알콜, 정신 건강, 비만, covid-19, 자살, 그리고 잘못된 의학정보, 의학 격차, 인종 등의 민감한 내용이 포함된 질문들이다. 다른 한 가지는 의료 형평성 (health equity)에 특화된 데이터셋으로 의료 접근성 (보험, 병원 접근성), 의료의 질, 사회/환경 팩터 (업무/거주 환경, 교통, 음식) 등등 민감한 내용들이 포함됩니다.
지난 논문에서도 의료 특화 LLM에서 의학적인 정확성을 담보하기 위해서 여러 노력들이 들어갔는데, 이번 논문에는 이런 부분을 특히 많이 신경쓴 티가 역력합니다. 특히 이런 기술이 일반 대중에게 서비스될 때를 가정하여 많은 테스트가 이뤄진 것으로 보입니다. 의료 비전문가 일반인을 평가자로 포함시킨 것도 그러하고, 의도적으로 ‘적대적인 질문’ 세트를 만들어서 의료 내적/외적으로 사용자에게 위해 가능성을 내포하고 있지 않은가를 테스트한 것도 그러합니다.
퍼포먼스
객관식 질문-답변 데이터셋에 대해서 Med-PaLM2는 지난 Med-PaLM과 Flan-PaLM에 비해서 더 좋은 성능을 보여줍니다. 이 부분에서는 GPT-4와의 비교도 있는데 (지난 논문에 GPT 이야기는 아예 없었던 것과는 다릅니다), 약간 맥빠질 수도 있겠지만 GPT-4의 성능이 (적어도 이 측정 기준에 대해서는) Med-PaLM2와 비슷하거나 더 좋은 것을 알 수 있습니다. (달리 말하면, 현존 최강의 GPT-4에 버금가는 퍼포먼스를 Med-PaLM2가 보여준다는 것이 오히려 더 고무적이라 해야 할지..)
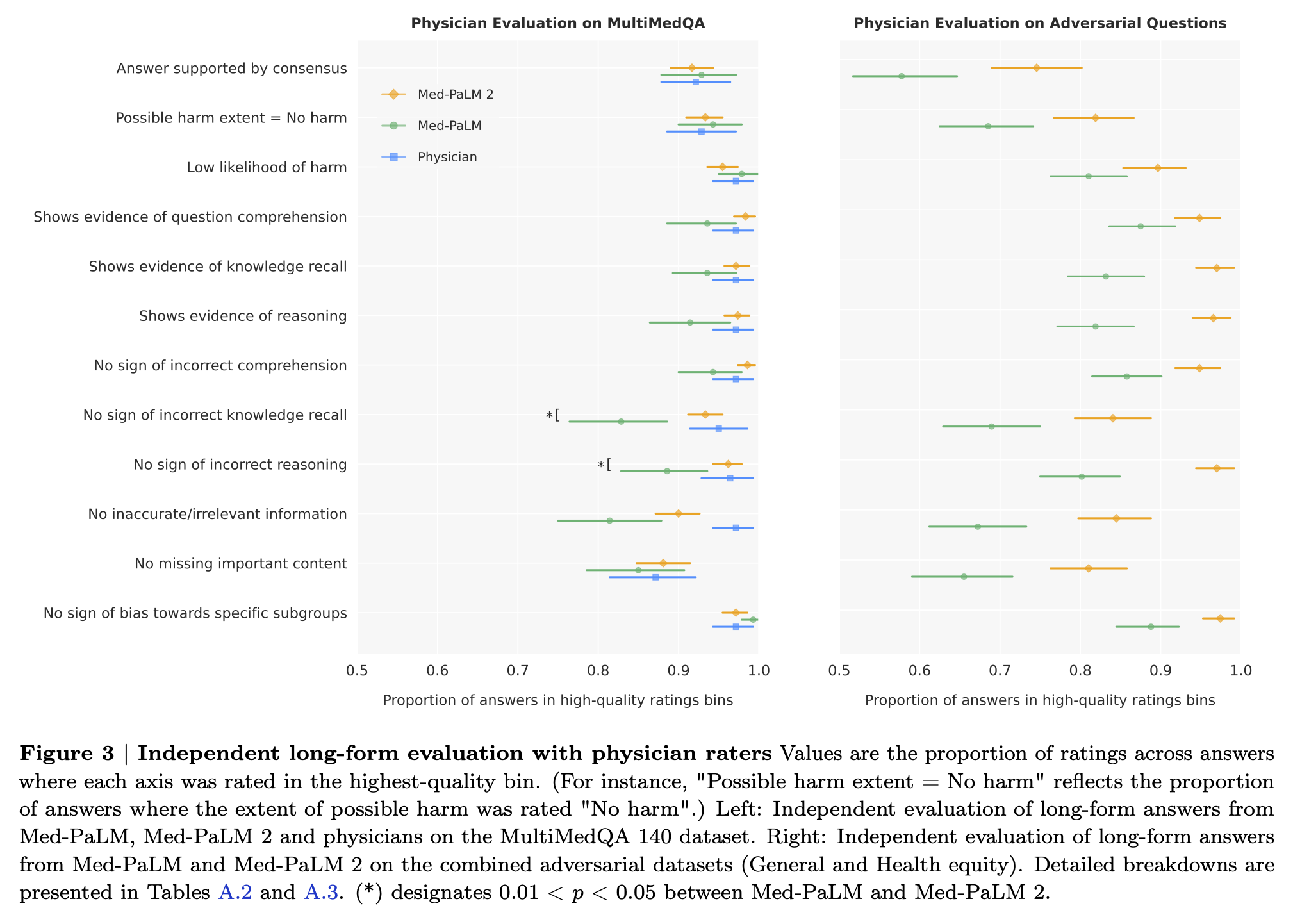
Long-form evaluation에 대해서는 Med-PaLM2가 Med-PaLM 과 의사에 버금가는 퍼포먼스를 (12개 정도의 기준에 대해서) 보여줍니다. 다만 여기서는 Med-PaLM2가 Med-PaLM 에 비해서 통계적으로 유의미하게 더 좋은 퍼포먼스를 (몇개 기준을 제외하면) 보여주지는 못합니다. 그래서 후술할 방식, 아예 1:1로 답변을 비교해서 선호도를 보는 방식으로 추가적인 평가를 하게 됩니다.
하지만 흥미롭게도 적대적 질문에 대한 long-form evaluation 파트에서는 Med-PaLM2가 Med-PaLM에 비해서 대부분의 기준에 통계적으로 유의미한 더 나은 답변을 보여줍니다. 이는 ‘일반’ 적대적 질문과 ‘의료 형평성’에 대한 적대적 질문에 대해서 모두 마찬가지였습니다.
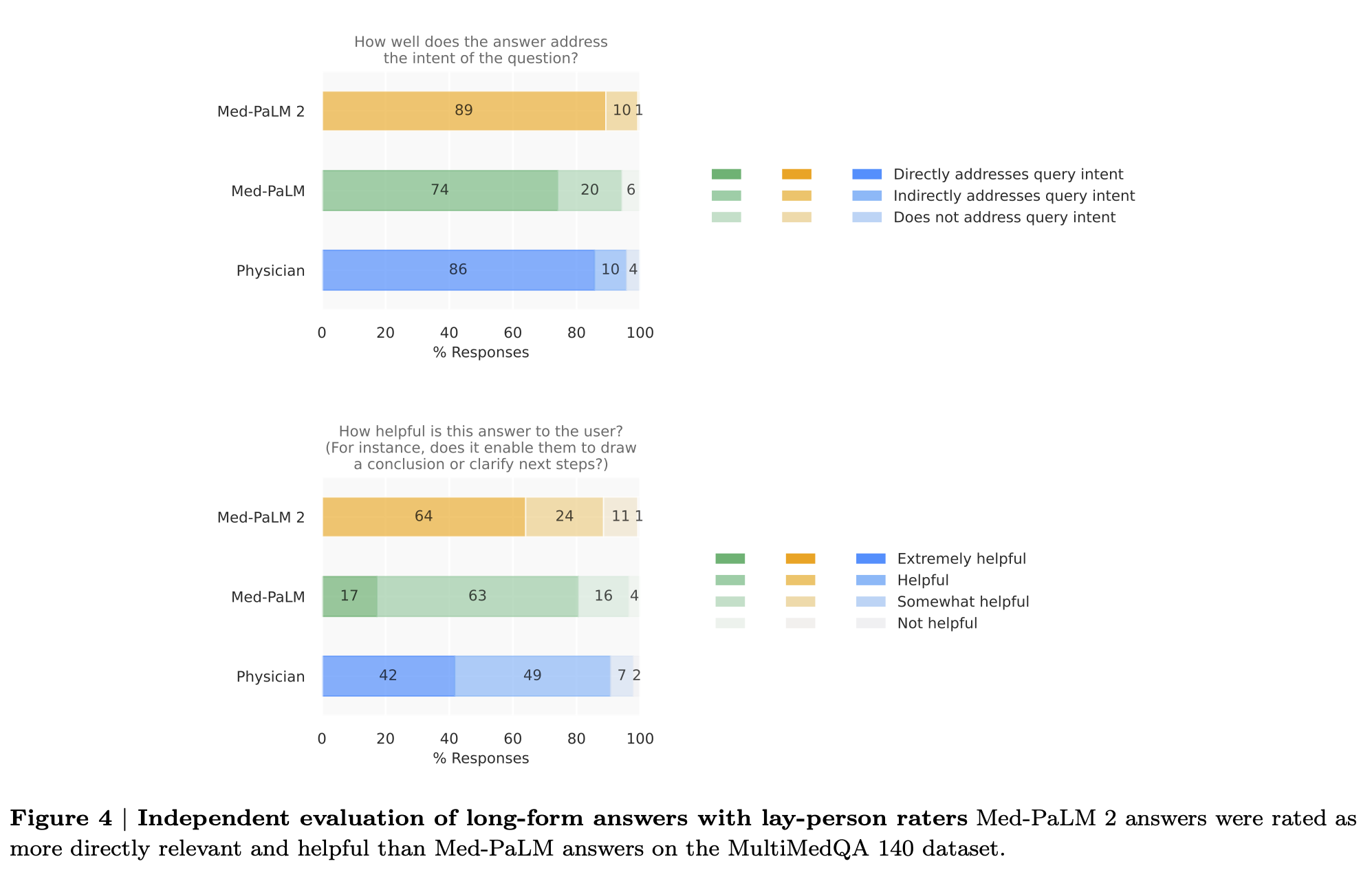
추가적으로 Med-PaLM, Med-PaLM2, 의사의 답변을 1:1로 비교하여 (by 의사 평가자, 일반인 평가자) 어느 답변을 더 선호하는가를 보았습니다. 흥미롭게도 Med-PaLM2의 답변이 의사의 답변에 비해서 대부분의 경우 더 퀄리티가 높은 것으로 선호되었습니다. 의사 평가자들은 better reflect consensus, better knowledge recall, better reasoning, more inaccurate/irrelevant information, greater extent of harm 등등의 측면에서, Med-PaLM2가 의사보다 더 낫다고 평가하였습니다. 또한 일반인 평가자들은 Med-PaLM2의 답변이 의사의 답변에 비해서 질문의 의도에 대한 답을 비슷한 수준으로 잘 내어놓으며, 오히려 더 큰 도움이 된다고 평가하였습니다. 이런 결과가 이 논문에서 가장 중요한 결과라고 할만합니다.
덧붙이는 말
결론적으로 Med-PaLM2는 의학적인 질문-답변 테스트 셋에 대해서는 지난 버전인 Med-PaLM 은 물론이고, 이제는 인간 의사에 버금가거나 어떤 측면에서는 더 좋은 성과를 보여준다는 것을 이 논문은 보여주고 있습니다.
특히, 의료 분야에서 극히 중요한 정확성, 위험성, 더 나아가서는 의료 형평, 접근성, 인종, 사회적 요인 등 의료 내적/외적인 측면들까지 이번 논문에서는 잘 테스트되었습니다. 또한 의료 전문가들 뿐만 아니라, 비전문가인 일반 환자의 입장에서도 이런 기술이 어떻게 받아들여질지에 대해서도 검증되고 있습니다.
사실상 Med-PaLM2는 이제 real-world 에서 활용이 가능할 정도의 퍼포먼스와 robustness를 이번 연구에서 보여주고 있습니다. 아직 완벽하지는 않지만, 인간 의사에 버금갈 정도는 됩니다. 이건 제 개인적인 추측이지만, Med-PaLM2의 다음 연구는 real-world 의료 현장에서 검증 혹은 활용을 하는 수순으로 가지 않을까 싶습니다. 이번 논문에서도 그런 언급을 잠깐씩 하고 있으며, 검증하고 있는 요소를 보면 자연스럽게 그런 방향으로 가지 않을까 합니다.
이번 연구의 한계는 이제 결국 LLM에 대한 것이므로 ‘언어’에만 기반한 것이라는 점 정도가 한계가 아닐까 합니다. 또 다른 중요한 (어쩌면 더 중요한) 발전 방향은 멀티모달입니다. 아닌게 아니라 구글에서 Flan-PaLM, Med-PaLM, Med-PaLM2 에 이어서, 최근 내어놓은 것이 바로 Med-PaLM M 으로 멀티모달 인공지능이다. 다음 연구로는 이 Med-PaLM M 논문을 살펴보겠습니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.