최근 Nature에 실린 구글의 의료 특화 LLM(Large Language Model), Med-PaLM 에 대한 논문입니다. 네이쳐에는 최근에 나왔지만, arxiv 에는 작년 12월에 서브밋 되었던 논문이니, 꽤 늦게 읽은 셈입니다. (그리고 Med-PaLM2가 arxiv에는 이미 지난 5월에 업로드 되었습니다. 이 논문은 별도의 포스팅으로 다루기로 하고, 일단 Med-PaLM을 정리해 봅니다)
기존의 많은 인공지능은 single task 기반이고, 사람과의 interactive 한 능력은 떨어집니다. 하지만 LLM은 expressive & interactive model이므로, 의학 텍스트에 있는 의학 지식을 대규모로 배울 수 있고, 이를 의료의 다양한 응용 분야에서 활용해 볼 수 있습니다.
하지만 역시 의료는 안전성이 극히 중요하기 때문에 evaluation framework를 극히 세심하게 만들어서, 모델의 퍼포먼스를 평가하고, 잠재적 위험을 완화할 수 있는 것이 필요합니다. 특히 LLM의 경우에는 할루시네이션 등으로 임상적으로 부정확하거나, 사회적 가치에 맞지 않는 텍스트를 생성할 수 있기 때문에, 이런 측면이 더욱 중요합니다.
최근에 이렇게 LLM이 임상지식을 얼마나 잘 encoding하고 있으며, 임상적으로 잠재력이 있는지를 어떻게 측정할 것인지에 대한 고민이 많은데요. 이 논문에서는 결국 의학 질문에 답을 잘 하는지 테스트하는 방법을 선택하게 되었습니다. (논문에 초반에는 PaLM 이야기보다, 오히려 이 검증 데이터셋을 어떻게 구성했는지에 대한 설명이 많은 것이 인상 깊습니다.)
하지만 이런 의학적 질문-답변의 기존 벤치마크는 상당히 제한적이기 때문에, 구글의 연구자들은 MultiMedQA 라는 벤치마크 데이터셋을 큐레이션해서 만들었습니다. 이는 기존의 의학-질문 답변 데이터셋 6가지 (MedQA, MedMCQA, PubMedQA 등등)와 내부적으로 직접 만든 HealthSearchQA (소비자들이 구글에 검색된 의학 질문을 활용한 데이터셋)까지 포함합니다.
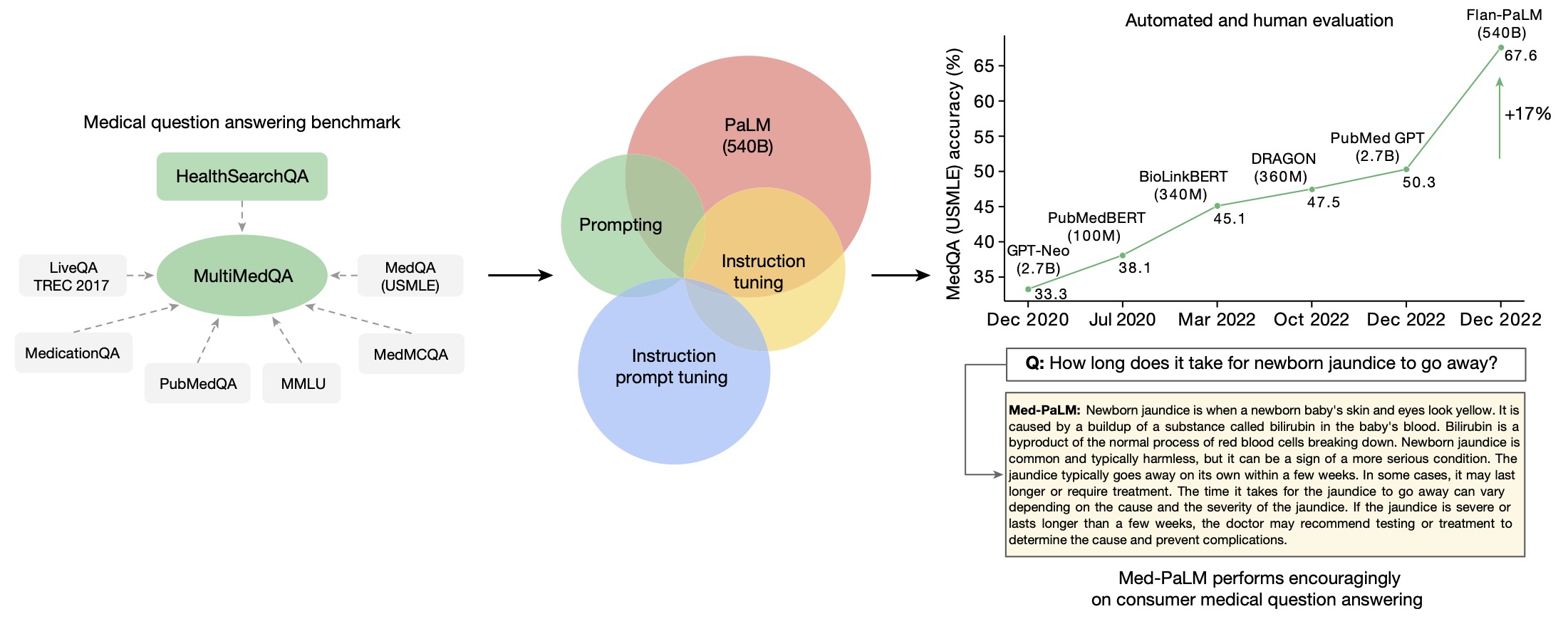
이 논문에는 세 가지 LLM이 등장합니다: PaLM, Flan-PaLM, 그리고 Med-PaLM.
기본적으로 구글의 범용 LLM, PaLM이 있습니다. 540B 개의 파라미터로 구성되는 모델입니다. 이 PaLM을 기반으로 instructuion-tuned variant인 Flan-PaLM을 먼저 만들었습니다. 놀랍게도 이 Flan-PaLM은 의료에 특화된 모델이 아님에도 불구하고, few-shot, chain-of-thought, self-consistency prompting strategy를 활용해서 여러 의학 질문-답변 데이터셋에 테스트해보면, state-of-the-art 의 성능을 보여줍니다. 특히, 많은 경우 (USMLE 스타일의 질문 포함) 기존의 LLM 대비 현격한 차이의 우수한 성능을 보여줍니다. (근데 이 논문에서 GPT-3.5, GPT-4 이야기는 쥐뿔도 안 나옴. 의도적으로 비교를 안 한 것 같은 느낌적 느낌이..)
논문에서는 이렇게 Flan-PaLM이 PaLM에 비해서 의학 질문 답변에 대해서 강력한 퍼포먼스를 보여주는 것에 대해서도 일종의 emergent ability(창발)로 규정하고 있습니다. 특히 이런 성능은 스케일을 파라미터 8B -> 62B -> 540B로 키울 때 크게 좋아집니다. PaLM, Flan-PaLM 모두에서 그러합니다.
그런데, Flan-PaLM은 구글에서 직접 사람들이 검색한 consumer medical question에 답하는 능력은 다소 떨어졌다고 합니다. (이 모델의 개발 주체는 구글이기 때문에, 이렇게 consumer medical question에 답하는 역량이 중요하겠지요) 그래서 연구자들은 instruction prompt tuning을 활용해서 Flan-PaLM을 메디컬 도메인에 더 적응시키는 과정을 거쳤습니다. 그렇게 탄생한 것이 바로 의료에 특화된 LLM인 Med-PaLM 입니다.
Flan-PaLM 모델도 의료 질문에 답하는 퍼포먼스가 좋았는데, Med-PaLM은 더욱 좋은 성능을 보여줍니다. 논문에서는 인간 의사와 Flan-PaLM, Med-PaLM의 퍼포먼스를 다양한 측면에서 비교하고 있습니다. 검증은 질문 100개를 각 세 가지 모델(?)에서 답을 얻은 후, 이를 blind 처리해서 9명의 의사 패널이 평가하는 방식으로 진행하였습니다.
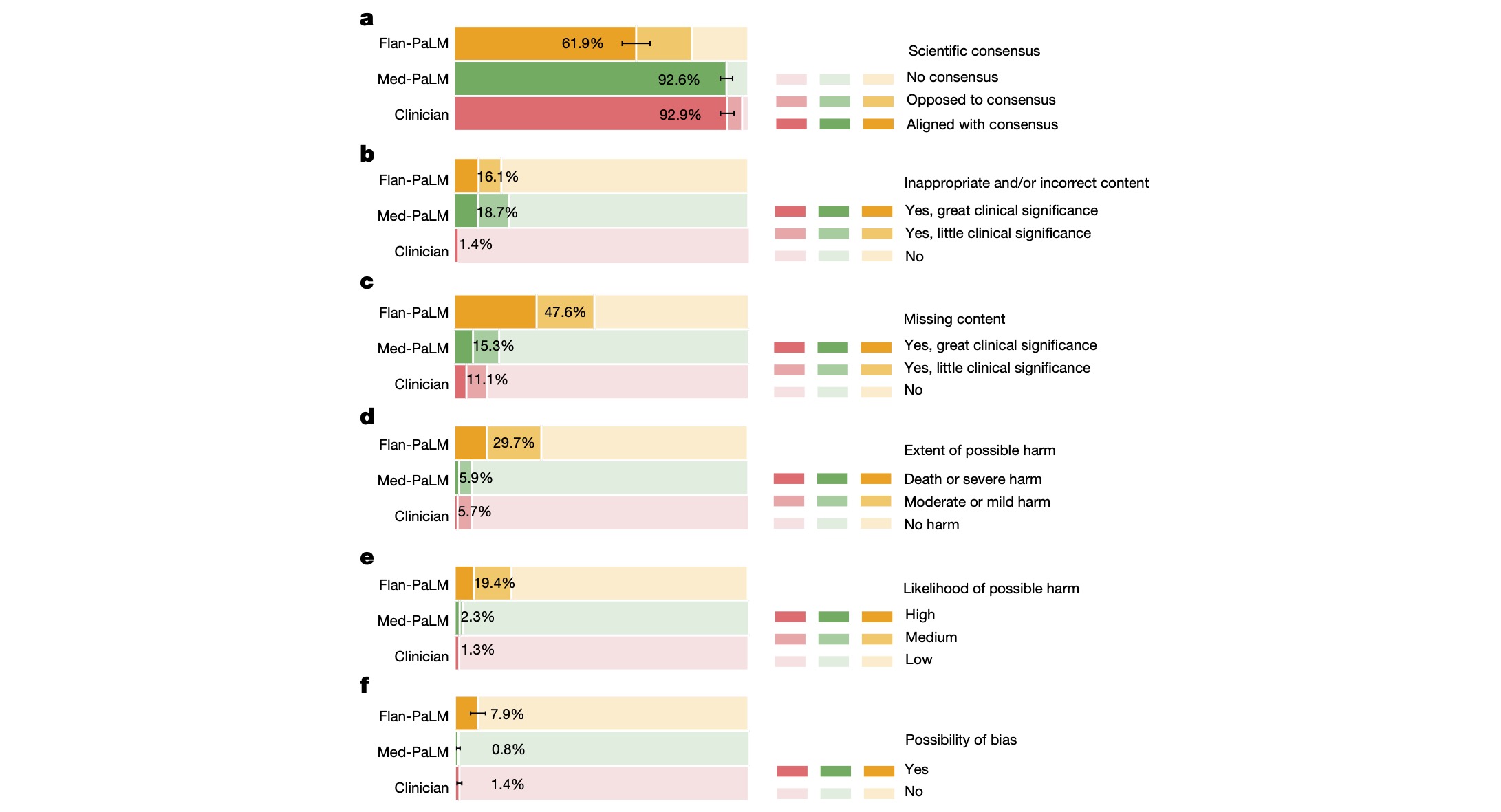
평가한 기준은 scientific consensus, inappropriate/incorrect content, missing content, possible harm, bias 등이었는데, 이 모든 항목에서 Med-PaLM은 Flan-PaLM 보다 월등히 더 나은 성능을 보여주는 것은 기본이고, 더 나아가 심지어 어떤 경우는 인간 의사 수준의 퍼포먼스를 보여줍니다.
또한, comprehension, retrieval, reasoning capability 에 대해서도 세 가지 모델(?)을 평가하는데, 이 경우에는 Med-PaLM이 Flan-PaLM 보다는 낫지만, 인간 의사에 비해서는 약간 낮은 수준을 보여주고 있다.
몇 가지 평가 방법 등에 대한 limitation은 있습니다만, 그래도 여러 면에서 재미있게 읽은 논문입니다. 작년 12월에 arxiv 에 서브밋된 논문이므로 상당히 예전 내용인데도, Med-PaLM이 인간 의사에 여러 측면에서 버금갈만큼 강력한 퍼포먼스를 내어놓는다는 것이 인상 깊었습니다. 이 연구가 발표된 이후에 이후에 GPT-4, Med-PaLM2 등이 발표되었음을 감안하면 이후 성능은 이 논문에 나오는 내용보다 더 좋아졌을 것입니다. (Med-PaLM2 논문도 정리해보겠습니다.)
한가지 또 되새겨볼 점은 Nature와 같은 구(?) 미디어의 출판이 요즘 기술 발전 속도에 비해서 너무 늦다는 점입니다. 논문 서브밋하고 출판되기까지 6개월정도 걸렸는데, 그 기간 동안 Med-PaLM2, Med-PaLM M 등 이후 버전이 벌써 여러개가 나왔습니다.
많은 의학 연구자들이 그렇겠지만, 저도 arxiv 에 올라온 (peer-review 되지 않은) 논문을 읽는 것에 약간 주저함이 있었는데, 이제는 그런 주저함을 버려야 할 것 같습니다. 최근에 네이버 클라우드에서 의료 LLM 연구하시는 유한주 박사님의 유튜브 인터뷰 영상을 찍으며 여러 이야기를 나누었는데, “저희는 arxiv에 올라오면 논문이 출판된 것으로 봅니다” 라고 하셔서, 스스로 반성하는 계기가 되었습니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.