지난 4월에 JAMA Intern Med에 출판되었을 때 꽤 화제(?)가 되었던 논문인데 이제서야 리뷰해봅니다. 환자의 임상적인 질문에 대해서 ChatGPT와 의사의 답변을 비교하여, 누가 더 양질의 & 공감력 높은 답변을 해주는지를 살펴본 논문입니다. 비록 methodology 측면에서 여러 한계가 있지만, 많은 시사점을 주는 연구라고 할 수 있습니다.
환자의 질문은 미국판 디씨인사이드..라고 할 수 있는, 레딧의 환자가 물어보고 의사가 답하는 게시판 (Reddit’s r/AskDocs)을 활용하였습니다. 여기에 올라온 환자의 질문과 의사의 답변 195개를 무작위로 추출하여, ChatGPT (GPT-3.5)의 답변과 비교하였습니다. (ChatGPT에 물어볼 때는 질문마다 fresh session에서 진행.)
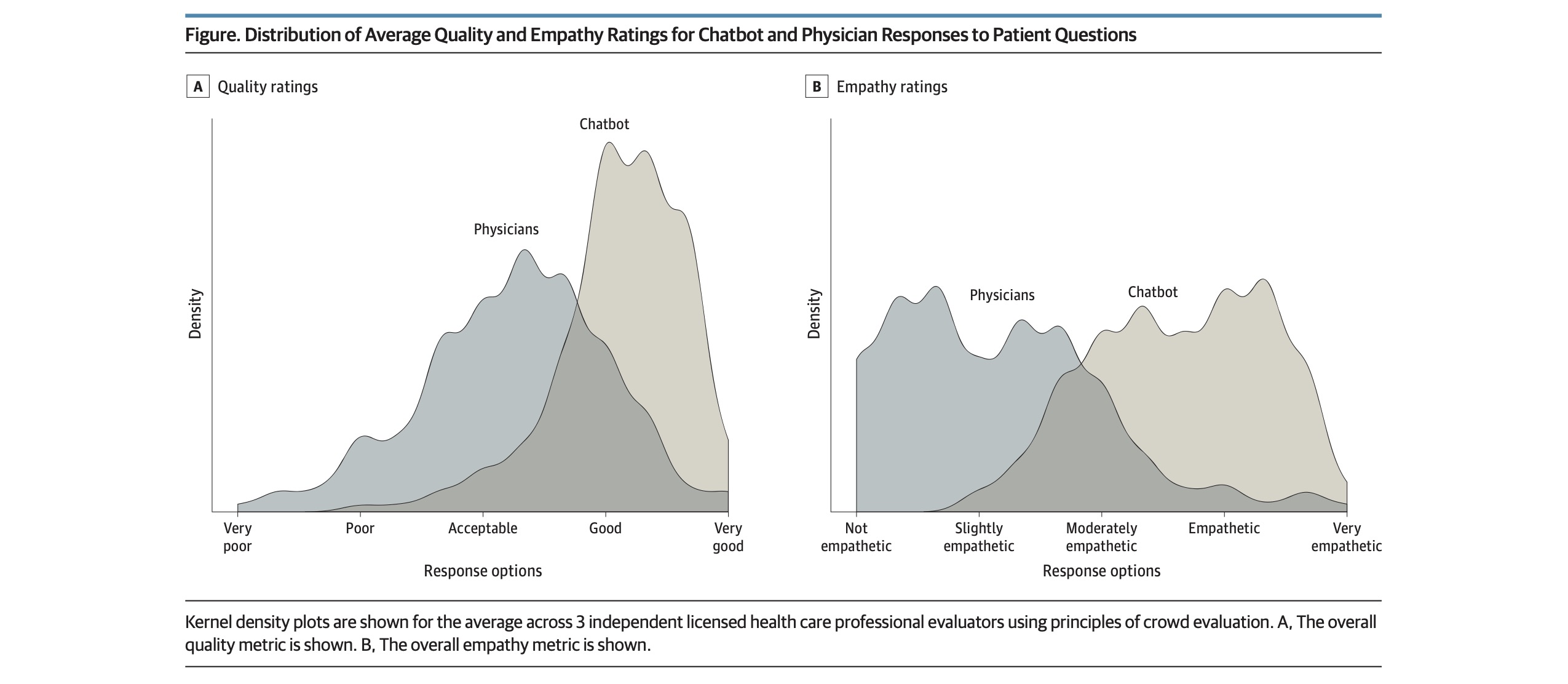
이러한 의사의 답변과 ChatGPT의 답변은 blind 처리하여 세명의 의사가 평가하였습니다. 일단은 두가지 답변 중에 어느 쪽이 더 나은가? 를 평가하였고, 세부적으로는 두 가지 기준, 즉 답변의 질 (quality)와 공감 정도 (empathy)를 5단계 척도 (아주 좋음(5), 좋음(4), 보통(3), 나쁨(2), 아주 나쁨(1))으로 구분했습니다.

그 결과 평가자들은 ChatGPT의 답변을 의사의 답변보다 유의미하게 더 좋다고 평가했습니다. 총 585번의 평가 중에 (195개 질문 x 3명 평가자) 78.6%는 ChatGPT의 답변이 더 낫다고 평가했습니다.
또한 ChatGPT의 답변의 질이 의사의 답변보다 유의미하게 더 높다고 평가했습니다. ChatGPT의 답변의 평점은 4.13점이었고, 의사의 답변은 평균 3.26점이었습니다. 또한 좋음/아주 좋음의 평가을 받은 비율은 ChatGPT는 78.5%, 의사는 22.1%로 3.6배 정도의 차이가 났습니다.
뿐만 아니라, ChatGPT의 답변은 의사의 답변에 비해 유의미하게 환자의 질문에 더 공감을 잘 하는 것으로 나타났습니다. ChatGPT 답변의 공감은 평점 3.65점, 의사의 답변은 2.15점으로 의사의 답변이 41% 낮았습니다. 공감력이 좋음/아주 좋음의 평가를 받은 비율은 ChatGPT가 45.1%인데 비해서, 의사는 4.6%로 9.8배 차이가 났습니다.
답변의 질과 공감의 정도는, 답변의 길이와 상관 관계가 있다고 생각할 수 있습니다. (무조건 길게 답변하면 더 질도 좋고, 공감도 한다고 느낄 수도 있으므로.) 따라서, 연구자들은 의사의 답변 중에 긴 답변들을 모아서 ChatGPT와 비교해보았습니다. 평균보다 긴 답변, 그리고 상위 75th percentile에 드는 긴 답변 두 가지로 평가하였는데요. 하지만 이 경우에도 평가자들은 각각 71.4%, 62.0%의 경우 ChatGPT의 답변을 더 선호하였습니다.
Discussion에서 저자들은 ChatGPT를 활용하여 의사가 환자의 메시지에 답할 때 초안을 작성하는 등의 도움을 받을 수 있다고 언급하고 있습니다. 코로나 이후 원격진료, 온라인 상담 등이 매우 활발해지면서, 환자들의 메시지가 폭증하였고, 이를 답하는 과정에서 의사들이 번아웃을 겪는 경우가 많아지고 있는데요 (논문의 가장 서두에 이 현상이 언급됩니다).
이미 현장에서도 의사들이 직원들의 써놓은 초안이나 이미 준비해둔 답변에 추가하여 답장을 주는 경우들이 많으므로, 이번 논문에서 나타난 것처럼, 양질의 & 공감력 높은 초안을 써줄 수 있는 ChatGPT를 여기에 활용하면 좋을 수 있다는 것을 언급하고 있습니다.
환자의 메시지에 더 빠르고, 양질의, 공감력 높은 답변을 할 수 있으면, 결국 환자의 outcome도 증진시킬 가능성이 있다고 언급하고 있는데요. 불필요한 내원을 줄여서, 병원 리소스를 정말 필요한 환자에게 집중할 수 있고, 또한 환자의 건강행동 (복약 순응도 등)을 개선시킬 가능성도 있다고 언급합니다.
Discussion에서 저자들은 ChatGPT의 보조적인 역할만 언급할 뿐, 의사들과의 직접적인 비교는 의도적으로 피하고 있는 듯해보이는데요. 적어도 이 논문을 그대로 해석하자면 ‘레딧에서 의사 게시판에 물어보는 것보다는, ChatGPT에게 물어보는 것이 더 낫다’는 정도로는 이야기할 수 있을 것 같습니다.
그리고 (이 연구가 진행되었을 때의) GPT-3.5보다, 최근에 새로 출시된 GPT-4에서는 정확도가 (특히 세부 전문 분야에 대한 답변의 정확도가) 상당히 올라갔다고 알려진 것, 할루시네이션의 위험이 상당히 줄었다는 것을 고려하면, 환자의 의학적 질문에 ChatGPT가 답하는 능력과 이의 활용도는 앞으로 더 큰 잠재력을 가지고 있다고 할 수 있습니다.
하지만 이 연구는 여러 한계도 있습니다. 가장 중요한 한계점은 레딧에 올라온 의사의 답변을 비교군으로 사용하였다는 것인데요. 온라인 포럼에 올라온 의사의 답변은 진료실에서 이뤄지는 실제 의사의 답변과 여러 측면에서 다를 수밖에 없기 때문이지요.
(디씨인사이드 같은 게시판에 쓰는 답변을 정말 정성들여서 제대로 쓰지는 않을 수도 있을테니까요. 돈을 받는 것도 아니고. 만약 의사들이 직업적으로 보수를 받고 답변을 주는 온라인 상담 서비스, 원격진료 등을 통해서 환자의 질문에 텍스트로 답변을 한 데이터를 구할 수 있으며, 이런 것과 ChatGPT를 비교했을 때는 조금 더 유의미한 비교가 되지 않을까요.)
흠. 그리고 추가적으로 이 연구에서는 답변의 정확성(accuracy)와 fabricated (아마도 할루시네이션)를 검증한 것은 아니었다고 limitation 파트의 마지막에 와서 한발을 물러섭니다. 본문에서는 답변의 quality 를 비교했으니, 여기에는 당연히 정확도를 포함해서 평가한 것이라고 생각했는데요. 정확도를 포함한 전반적인 답변의 질을 평가한 것이라 (아마도 리뷰어의 지적을 받고) 이렇게 한발 빼는 문장이 들어간 것 같기도 합니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.