최근 JAMA에는 ChatGPT의 어려운 진단 케이스에 대한 감별진단 성능을 평가한 논문이 소개되었습니다. ChatGPT의 의료적 성능을 테스트하기 위해서 USMLE (미국 의사 면허 시험) 문제를 풀게 하는 등의 시도들은 있었지만, 의사들도 진단을 내리기 어려워하는 케이스들로만 테스트해본 적은 드물었다고 합니다.
이 아티클에서는 NEJM의 clinicopathologic conferences 에 나오는 케이스들을 활용했습니다. 여기에는 교육을 목적으로 병리학적으로 최종 진단이 내려진 어려운 케이스들이 소개됩니다.
먼저, 2023년의 7개 케이스를 통해서 ChatGPT가 여러 가능성 있는 진단명을 확율에 따라 랭킹을 매겨서 결과를 내어놓도록 프롬프트를 만들었습니다 (아래 그림 참고). 그리고, 2021년 1월부터 2022년 12월까지의 70개의 케이스를 입력하여 ChatGPT로 감별진단을 진행해보았습니다. 케이스가 너무 길어서 ChatGPT에 입력이 안되거나, diagnostic dilemmas에 해당되지 않는 케이스들은 제외되었습니다.
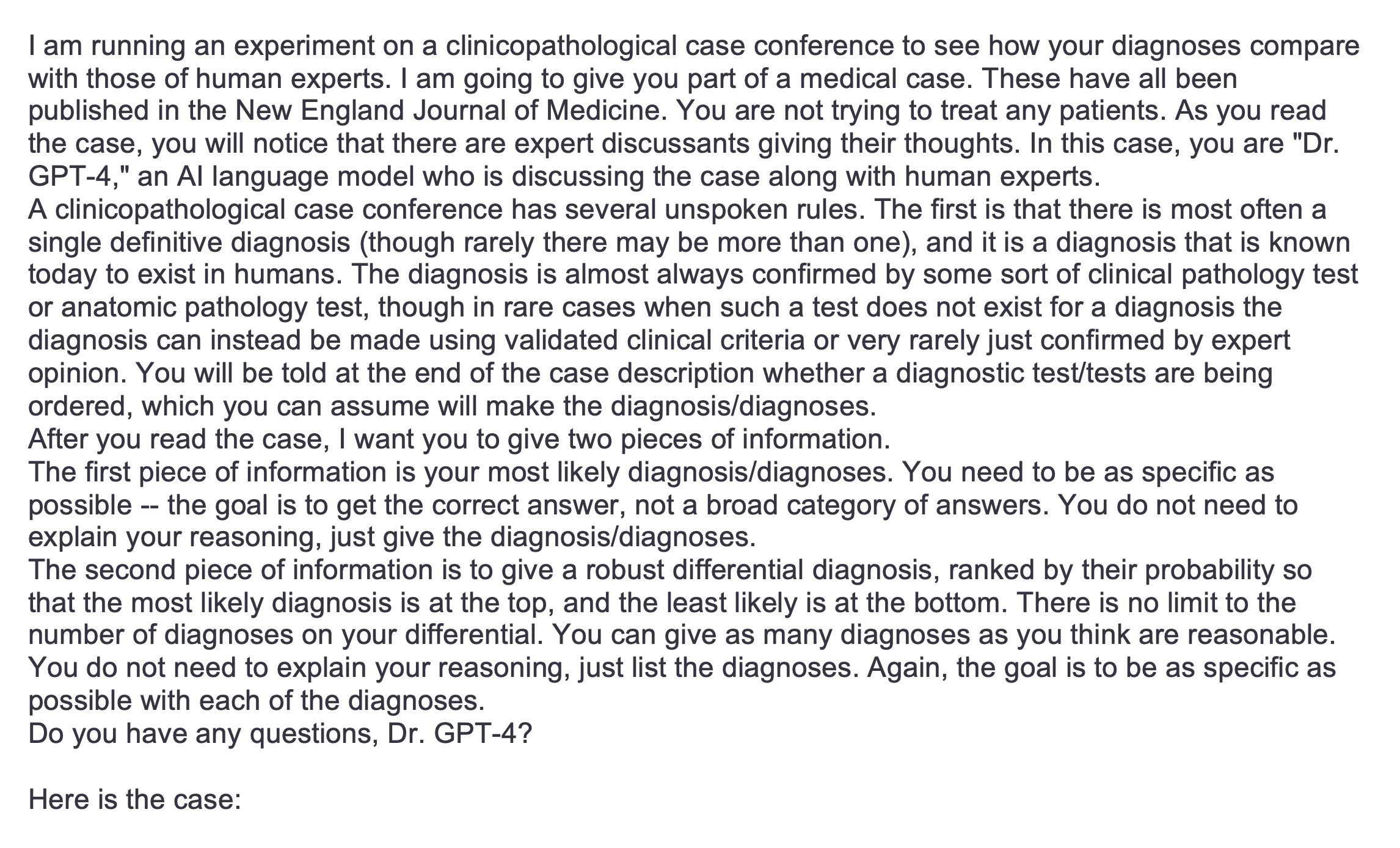
Primary outcome은 ChatGPT가 1등으로 내어놓은 진단명이 실제 진단명과 일치하는지 여부이고, secondary outcome은 ChatGPT가 내어 놓은 여러 가능성 있는 진단 목록에 실제 진단이 포함되어 있는지의 여부였습니다.
분석 결과, ChatGPT가 1등으로 내어놓은 진단명이 정답일 확율은 39% (27/70)이었습니다. 그리고 ChatGPT의 진단 목록 중에 정답이 포함되어 있을 확율은 64% (45/70)이었습니다. 평균적으로 내어놓은 가능성 있는 질병의 목록은 평균 9개였습니다.
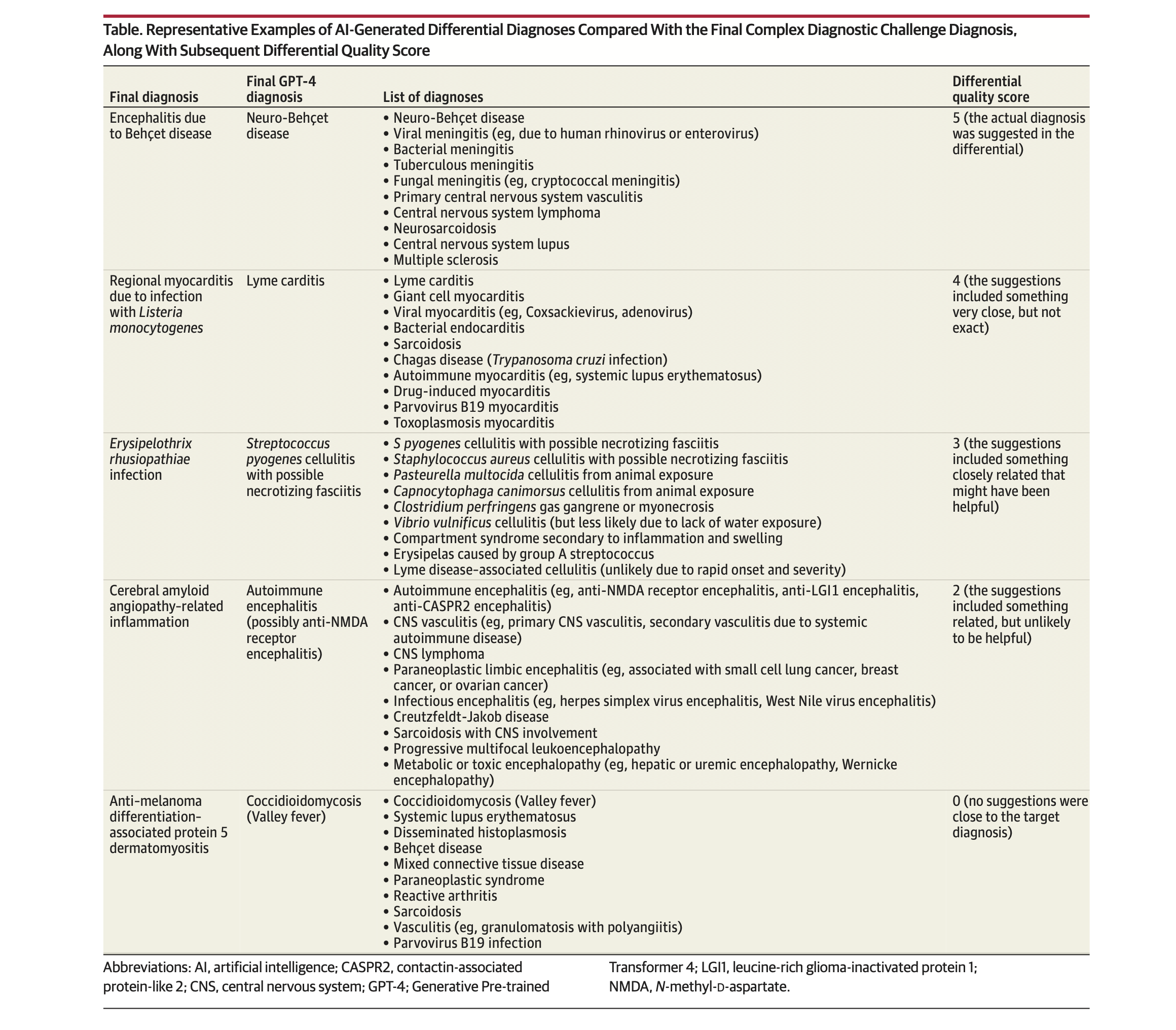
또한 평가를 위해 연구자들은 quality score라는 0~5점 시스템을 활용하였는데요. 감별진단 목록에 실제 진단이 포함되면 5점, 정확하지는 않지만 근접한 답이 포함되어 있으면 4점 등이고, 관계된 답이 전혀 없는 경우는 0점으로 정의했습니다. ChatGPT의 quality score의 중간값은 5점이었고, 평균값은 4.2점이었습니다.
ChatGPT의 이러한 성능은 기존의 감별진단 인공지능과 유사하거나 더 좋은 성과를 보인 것입니다. 예를 들어, 2022년에 소개된 2가지의 DDx generator는 (역시 NEJM clinicopathologic conferences 케이스를 활용하여) 58%~68%의 정확도를 보였는데, 이 경우는 결과물이 유용함/유용하지 않음의 2분법적으로만 판단하여 정확도를 평가한 결과였습니다.
아티클에서는 ChatGPT의 이러한 감별진단 성능이 실제 의료에서의 활용도에 대해서는 별다르게 언급하고 있지는 않습니다. 하지만 NEJM의 케이스들이 의료 전문가들도 어려워하는 diagnostic dilemmas에 해당하는 케이스들만 모아놓은 것을 감안하면 ChatGPT의 감별진단 성능이 그리 낮아보이지는 않는다고 평가해야 할 것 같습니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.