최근 FDA에서는 인공지능/머신러닝 기반의 인공지능 의료기기의 adaptive learning을 어떻게 규제할 것인지에 대한 백서를 내어놓았습니다. (즉, 아직 가이드라인 전단계의 문서입니다.) 인공지능의 속성 중의 하나는 개발할 때뿐만 아니라, 사용하면서도 사용자의 피드백, 새로운 학습 데이터, 혹은 알고리즘 자체의 발전으로 계속 변화/발전할 수 있다는 점입니다. 이를 adaptive learning (적응형 학습)이라고 합니다.
제가 졸저 ‘의료 인공지능’에서도 IBM Watson for Oncology를 설명하면서, 지속적으로 출판되는 논문 등을 반영하여 WFO의 결과가 지속적으로 바뀔 수 있기 때문에 기존 방식의 임상 연구를 통한 검증이 근본적으로 어려울 수 있다고 지적한 바 있습니다. 이때 언급했던 것이 바로 adaptive learning 입니다.
이번 백서에 나오듯이, 일반적으로 AI/ML에 기반한 SaMD가 바뀌는 것은 아래와 같이 Performance, Input, Intended Use의 세 가지 경우 중 하나, 혹은 둘 이상이 될 것입니다. 각각에 대한 예시도 들어드립니다.
- Performance: 새로운 dataset으로 다시 알고리즘을 트레이닝하는 경우
- Input
- a. 같은 종류 데이터이면서, 새로운 데이터 소스: 추가적인 브랜드의 CT 스캐너의 input
- b. 새로운 종류의 데이터: 심박수만 입력하다가 → 심박수+산소포화도를 입력
- Intended Use
- 제공하는 정보의 중요도: ‘aid in diagnosis’ → ‘definitive diagnosis’
- 사용하는 조건/대상의 변화: 18세 이상 → 소아청소년 환자 포함
- 대상 질병의 확대
그런데 이러한 경우에 대해서, 의료 인공지능을 사용하는 과정에서 자주, 혹은 (거의) 실시간으로 학습 데이터가 바뀌거나, 레퍼런스 데이터(정답)에 업데이트가 있거나, 알고리즘 자체가 바뀔 수도 있습니다. 예를 들어, 아래와 같은 경우가 있을 수 있습니다.
- 암 환자 진료 보조: 의사의 사용 결과/매일 나오는 논문을 반영한다면
- 중환자실 심정지 예측: true alarm / false alarm 결과에 대한 의사의 의견을 재반영
- 흉부 엑스레이 분석: 새로운 데이터의 학습 / 알고리즘 발전 / intended for use 확장
하지만 의료 인공지능에 대한 기존 규제 방식은 이러한 adaptive learning의 속성을 제대로 반영하지 못하고 있었습니다. 기존 의료기기는 바뀌면 인허가를 새로 받거나 문서를 고쳐야 하는데, 인공지능이 매우 자주, 혹은 실시간으로 바뀌면 이러한 기존의 규제 방식이 통하지 않기 때문입니다. 또한 그러한 변화 과정에서 안전성, 효과성을 관리할 규제적 장치도 없었습니다.
따라서, 지금까지 FDA 가 인허가 했던 인공지능은 모두 locked 알고리즘이었습니다. (한국 식약처가 인허가한 인공지능의 경우도 마찬가지입니다) 즉, 허가 이후에 원칙적으로 알고리즘, 데이터셋 등을 지속적으로 바꿀 수 없고, 변화가 있을 경우 기존의 software modification guidance를 따라서 필요한 경우 변경 인허가를 받아야 합니다. 이는 자주, 혹은 실시간으로 변화하는 경우에는 적용하기가 어렵습니다. 예를 들어, 5분마다 바뀌는 인공지능이라면, 변화가 있을 때마다 변경 인허가를 새롭게 받기란 현실적으로 불가능하기 때문입니다.
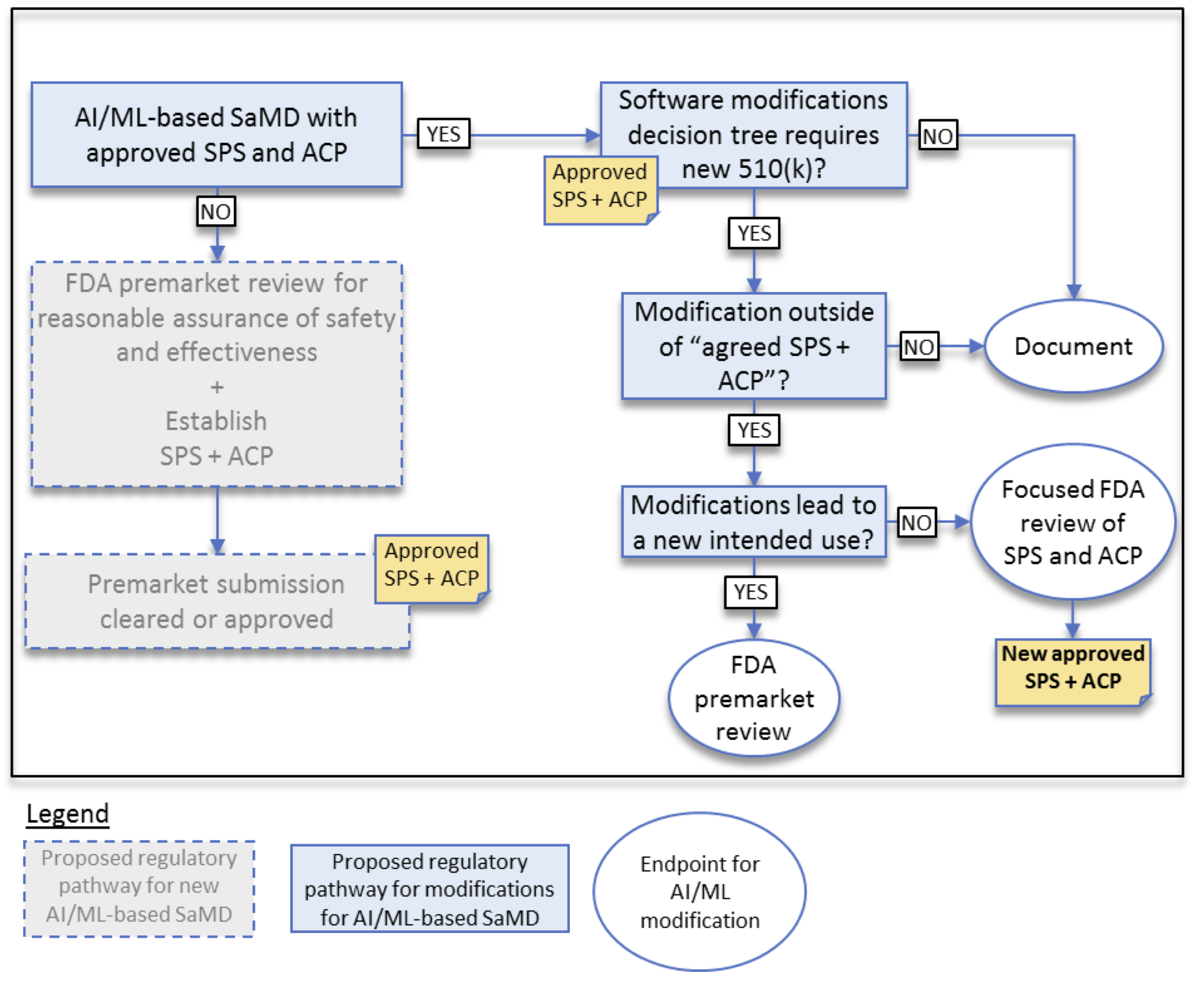
하지만 FDA는 최근 내어놓은 백서에서 SaMD Pre-Specification (SPS)와 Algorithm Change Protocol (ACP)라는 두 개념을 새롭게 도입해서 이 문제를 해결할 것을 제안하였습니다. 이 개념은 한마디로 처음 인허가 받을 때 제조사에서 앞으로 예상하는 알고리즘의 변화 및 관리 방안을 예상/정의해서 이러한 관리계획 자체도 함께 인허가 받는 것입니다. 간략히 아래와 같습니다.
- SaMD Pre-Specification (SPS)
- 제조사가 예상/계획하는 출시 이후 performance / input / intended use 상의 변화
- 최초 기기에서 향후 변화할 범주 (region of potential changes)를 정의
- Algorithm Change Protocol (ACP)
- SPS에서 정의된 변화에 대한 risk 를 컨트롤하기 위한 구체적인 방법
- 변화 이후에 safety/effectiveness 유지 되도록 data/procedure 에 대해 단계별 기술
그리고 이후에 adaptive learning에 따른 변화에 대해서, 그 변화가 SPS와 ACP의 범주를 넘어서는 것인지를 기준으로 새로운 변경 인허가가 필요한지 단순 documentation만 할 것인지를 판단하겠다는 것입니다. 더 나아가 새로운 SPS와 APC를 허가받을 수도 있습니다. 아래의 그림과 같습니다.
사실 국내 식약처에서도 (저를 포함한) 전문가 협의체에서 재작년 인공지능 의료기기 가이드라인을 만들 때 이러한 개념이 고려된 바 있고, 이것이 ‘버전 관리’의 개념으로 제조사의 책임하에 관리한다는 정도로 기술된 바 있습니다. 하지만, 제 기억으로 당시에는 주로 training dataset의 변화 정도만 다루었던 것으로 기억합니다. (IBM Watson for Oncology 때문이었지요) 그리고 adaptive learning을 하는 인공지능에 대해서는 아직 한국은 허용하지 않고 있습니다. (사실 이 국내의 가이드라인은 FDA보다 더 빠르게 나왔습니다.)
하지만 이제 FDA는 training dataset의 변화를 포함하여, 보다 전반적인 data managment, re-training, performance, update procedure 등에 대한 상세한 SPS와 ACP를 제시하고 있습니다. 매우 인상적인 개념입니다. 이번 뉴스에 관한 기사들을 보면 FDA에서 스콧 고틀립 국장은 떠났지만, FDA의 혁신은 아직 끝나지 않았다고 평가하고 있네요. (작년에 스콧 고틀립이 이 ML의 adoptive learning의 새로운 규제 방안을 만들고 있다고 언급했던 적이 있습니다)
향후 많은 의료 인공지능은 이렇게 adaptive learning의 속성을 지니게 될 것이므로, 이러한 새로운 규제 방식의 영향을 크게 받을 것으로 생각합니다. 아직 백서의 수준이라 실제로 가이드라인에서는 어떻게 나올지 알기 어렵습니다만, 관련 분야에 계신 분들은 앞으로도 이 개념을 꼭 팔로업하셔야 하겠습니다.
또한 문제는 심평원 등지에서 알고리즘 및 결과가 계속 변화하는 시스템에 대해서 수가를 어떻게 매길 것인지에 대해서도 앞으로 고민하셔야겠지요. 알고리즘 및 결과가 바뀌면 cost-effectiveness도 바뀔테니까요. 저도 다음번 식약처, 심평원 회의에서 이러한 개념을 소개해드리려 합니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.