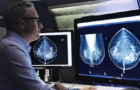
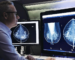
며칠 전 Science에 실린 흥미로운 아티클입니다. 바로 의료 인공지능에 대한 adversarial attack, 즉, 악의적인 공격의 가능성에 관한 것입니다. 다른 모든 인공지능과 마찬가지로 의료 분야의 인공지능 역시 이러한 악의적인 공격에 취약할 수 있습니다. 데이터를 (인간은 알아차릴 수 없을 정도로) 미묘하면서도 교묘하게 의도적으로 조작함으로써, 알고리즘이 내어놓는 결과를 완전히 반대로 만들 수 있다는 것입니다.
예를 들어서, 피부의 점 사진에 대해서 (인간의 눈으로는 알 수 없는) 몇 픽셀 수준의 perturbation을 줌으로써, 원래는 인공지능이 정상으로 판독하던 것을 암으로 판독할 수 있게 만들 수 있습니다. 이는 이미지 판독 관련 뿐만 아니라, 자연어 처리에서 단어 표현을 조금 바꾸거나, 혹은 보험 심사에 대해서 청구 코드를 약간 바꾸는 것으로도 알고리즘이 정반대의 결과를 내어놓게 하는 것이지요.
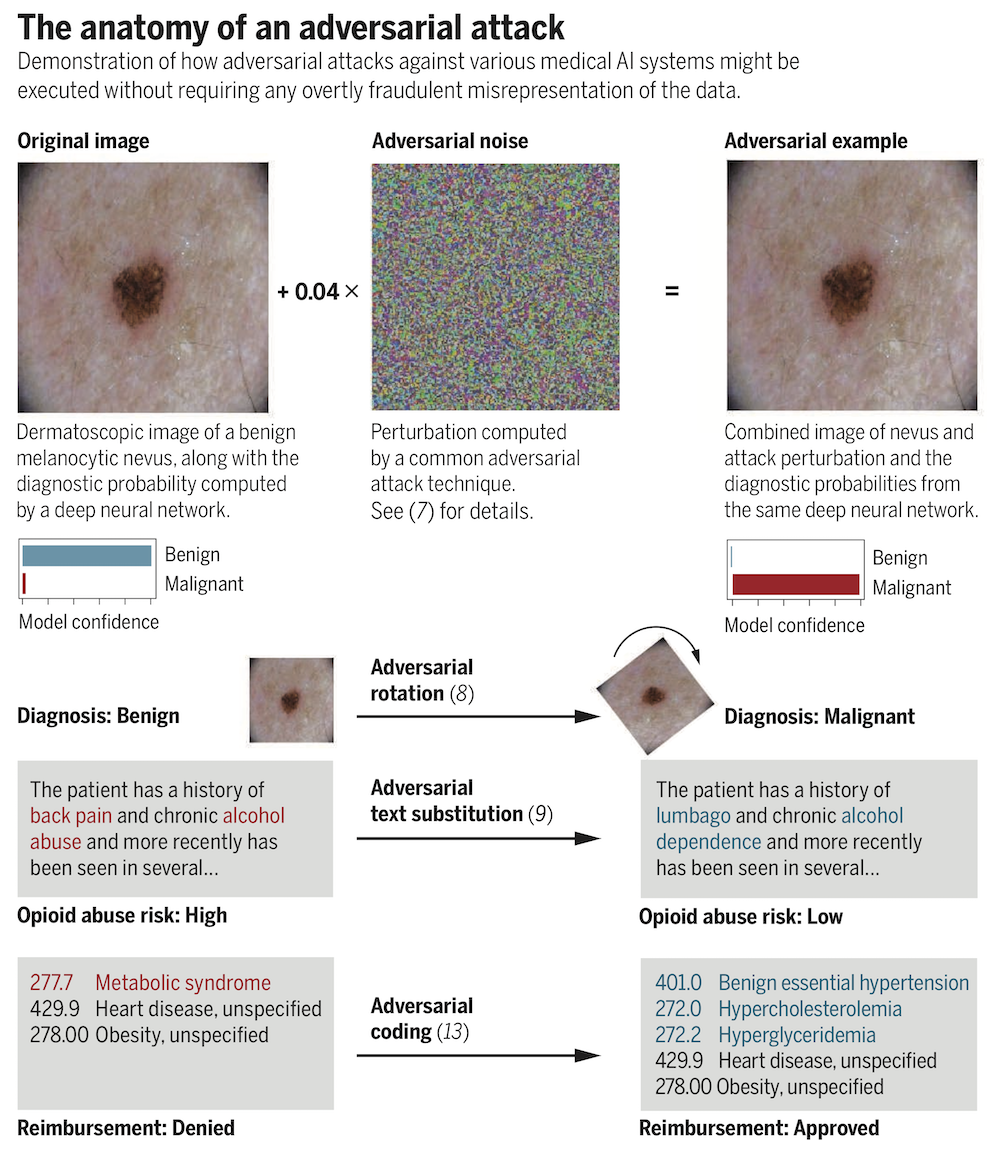
아티클에서는 특히 보험 심사 알고리즘에 대한 악의적인 공격의 우려에 대해서 많이 언급합니다. 보험사는 보험 사기 판독 알고리즘이나, 보험 청구를 허가할 지에 대한 알고리즘을 사용하기 때문입니다. 사실 미국의 의료계에서는 이미 보험 청구에 대한 승인율을 높이기 위해서 청구 코드를 최적화(?)하거나 (내분비학회에서는 아예 청구에 대한 요령을 홈페이지에 올려놓았다고..), 혹은 데이터를 조작하면서 더 많은 보험료를 타내기도 한다는 점을 지적하면서 이런 악의적인 공격에 대한 동기는 충분하다고 설명합니다.
의료 인공지능에 대해서만 이 문제가 있는 것은 아니지만, 역시 건강과 많은 돈이 걸려 있는 분야이다보니, 이 이슈에 대해서 어떻게 대응할지도 중요합니다. 아직 이 문제가 불거지지 않았는데도 미리 대응하자니, 기술의 발전도 저해되고 (아직 성능의 최적화와 악의적인 공격에 대한 robustness를 모두 갖추는 것은 컴퓨터 공학적으로 해결되지 않은 문제. 즉, 현재로서는 robustness를 올리려면 성능이 떨어질 수밖에 없음), 이러한 의료 인공지능에 의한 혜택을 환자들이 누리지 못하는 결과를 받게 되기도 합니다. 또 너무 늦게 대응하면 문제가 겉잡을 수 없이 커질 수도 있습니다.
사실 이 문제는 의료 인공지능 뿐만 아니라, 자율 주행차나, 인공지능에 의한 무기의 컨트롤 등에 대해서도 마찬가지로 존재하는 문제입니다. 어찌보면 기존의 해킹 위험과 이에 대한 방화벽을 쌓는, 도전과 응전의 관계처럼 앞으로 시행착오를 거치며 단계적으로 발전할 것이라고 볼 수 있습니다.
이러한 문제는 분명히 존재하고 앞으로 그 중요성이 더 커질 가능성이 높습니다. 현재 이 문제에 대한 대비책을 모두 세울 수는 없겠습니다만, 이 문제의 중요성을 인식하고, 여기에 대한 기술적(사진에 대한 해시값을 저장했다가 비교 등), 규제적, 정책적인 대비를 차근차근 할 필요가 있을 것입니다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.