구글은 전자의무기록에 저장된 환자의 진료 기록을 딥러닝으로 분석하여 입원한 환자의 치료 결과를 정확히 예측하는 인공지능을 2018년 1월 발표했다. 이 딥러닝을 이용하면 환자가 입원 중에 사망할 것인지, 장기간 입원할 것인지, 혹은 퇴원 후에 30일 내에 재입원할 것인지, 그리고 퇴원 시의 진단명은 어떻게 될 것인지까지도 높은 정확도로, 조기에 예측할 수 있다.
병원의 전자의무기록(EHR)은 그야말로 의료 데이터의 보고라고 해도 과언이 아니다. 해당 병원에서 환자가 진료받은 모든 검사 결과, 진료 기록, 처방 내역 등이 포함되어 있기 때문이다. 특히 과거에는 종이 차트에 이를 기록하였으나, 미국에서 오바마케어 이후로 진료 기록을 디지털 데이터로 저장하는 EHR의 도입이 증가하면서 예측 모델을 만드는 것도 보다 용이해졌다. 이를 기반으로 환자의 치료 결과나 예후를 예측할 수 있다면 치료를 받는 환자뿐만 아니라, 의료진과 병원의 입장에서도 자원을 효율적으로 활용하고 비용을 감소시키기 위해 도움이 될 것이다.
하지만 전자의무기록의 데이터를 분석하는 일은 결코 쉬운 일이 아니다. 무엇보다 저장되어 있는 데이터가 무척이나 복잡하고, 종류도 다양하며, 빠져 있는 데이터도 많다. 종합병원에서 치료하는 환자의 수, 질병의 유형이나, 처방하는 약의 종류, 진행하는 수술의 종류를 생각해보면 무지막지하게 복잡하고 많은 데이터가 EHR에 저장되어 있을 것이다. 이 데이터의 변수는 족히 수천 개가 넘어갈 것이다.
그렇기 때문에 딥러닝 이전의 연구에서는 EHR 데이터 기반의 예측 모델을 만들기 위해, 의료 지식을 가진 인간 전문가가 직접 중요 변수를 고르고, 데이터를 깔끔하게 만드는 등의 전처리 과정이 중요했다. 이러한 과정에서는 인간 전문가의 사전 지식에 예측 모델의 성능이 좌우되었을 뿐만 아니라, EHR의 전체 데이터가 아닌 일부 데이터만을 활용할 수밖에 없었다. 일부 데이터만 활용한다는 것은 결국 예측 모델의 정확성을 높이기 위해서 한계로 작용할 수밖에 없다.
더욱이 EHR에는 혈액 검사 수치처럼 정량화, 정형화(structured)되어 있는 데이터도 저장되어 있지만, 그뿐만 아니라 의료진이 진료 기록을 텍스트로 기록해놓은 비정형적(unstructured) 데이터도 있다. 의료진이 자연어(natural language) 및 의학 약어 등으로 기록해놓은 진료 노트는 분석하기가 기술적으로 어려우므로, 기존의 많은 연구에서는 이 부분을 분석 대상에서 아예 제외하기도 했다. (사실 EHR 기반의 연구를 이야기하자면 의료 데이터 표준이나, 호환성(interoperability)도 언급해야 하지만, 논의의 범위를 한정 짓기 위해 여기서는 논하지 않는 것으로 하겠다)
전자의무기록 전체를 분석하는 인공지능
구글은 딥러닝 기술을 활용하여 기존의 연구에서 나타났던 이러한 문제점들을 해결했다. 딥러닝의 특성 중의 하나는 데이터를 인공지능에 학습시키기 위해서 데이터의 특징을 사람이 미리 지정할 필요가 없다는 것이다. 즉, 딥러닝은 기존의 다른 기계학습 방법과는 달리 어떤 변수가 얼마나 중요하며, 변수의 어떤 조합이 중요한지를 스스로 계산해준다. 때문에 과거에 비해 인공지능을 개발하기 위해서 해당 분야에 사전 지식을 가지는 것이 덜 중요하다. (딥러닝의 간략한 소개는 이 포스팅을 참고하시길)
그래서 이번 연구에서는 사람이 EHR의 데이터 중에서 인공지능에게 무엇을 어떻게 학습시킬지를 정하는 것이 아니라, EHR 데이터 전체를 딥러닝에게 학습시켜서 그 중에 무엇이 중요한 정보인지를 딥러닝 스스로 파악하게끔 했다. 특히 이번 연구에는 의료진의 진료 노트(medical note)도 인공지능의 학습 데이터에 포함되었다는 점이 큰 특징이다. 대부분의 기존 연구에서는 의료진이 자연어로 메모해놓은 노트의 학습이 기술적으로 어렵기 때문에 분석 대상에서 제외되었으나, 딥러닝을 이용한 자연어 처리(natural language processing) 기술의 발전 [ref] 덕분에 이 연구에서는 자동으로 분석할 수 있게 된 것이다.
이러한 딥러닝 기술의 활용은 전자의무기록의 분석에 대해서 또 다른 중요한 장점을 가진다. 바로 확장성(scalability)이다. 사실 과거의 유사한 연구에서는 확장 가능성에 심각한 문제가 있었다. 학습 데이터를 준비하거나, 가다듬는 전처리 과정에 (이 과정의 많은 부분은 수작업으로 이뤄진다) 프로젝트 리소스의 80%를 소모해야 했기 때문이다 [1, 2]. 이러한 경우 예측 모델의 퍼포먼스를 높이기 위한 인공지능 설계에 투입될 자원이 상대적으로 줄어들 뿐만 아니라, 모델을 한 번 만들어놓으면 더 많은 데이터, 더 다양한 변수 등을 추가적으로 적용하기는 어렵게 되므로 확장성에 문제가 생긴다. 하지만 구글은 딥러닝을 사용함으로써 데이터 전처리 과정을 생략하여, 논문의 제목에도 명시되어 있는 것처럼 ‘확장 가능한(scalable)’ 예측 모델을 만들 수 있었다. 즉, 이 모델에 새로운 종류의 데이터를 추가하거나, 다른 병원에서 적용하기가 용이한 연구 결과이다.
구글 인공지능의 예측 정확도
구글은 미국의 두 유명 대학 병원의 방대한 EHR 데이터를 학습시켜서 정확한 치료 결과 예측 모델을 만들었다. 캘리포니아주립대 샌프란시스코 대학병원(UCSF)의 2012~2016년 데이터와 시카고 대학병원(UCM)의 2009~2016년 동안 최소한 24시간 입원했던 총 114,003명의 환자들의 216,221번의 입원에서 나온 진료 기록에 기반하여 인공지능을 만들었다. 이를 모두 합하면 예측 모델의 개발에 활용된 데이터의 수는 무려 468억 개가 넘는다.
구글은 두 병원의 데이터를 이용해서 동일한 알고리즘을 각각 테스트해보았다. 두 병원의 전체 데이터 중 80%는 인공지능을 학습시키는 훈련 데이터(training data)로, 10%는 개발한 모델을 개선하고 검증(validation)하기 위해서, 나머지 10%는 이 예측 모델의 성능을 테스트하기 위해서 사용되었다.
이 모델의 정확도를 테스트하기 위한 기준은 아래와 같이 총 네 가지 항목이었다.
- 입원 환자의 사망 위험도 예측 (inpatient mortality)
- 퇴원 후 30일 내 재입원 (30-day unplanned readmission)
- 장기 입원 여부 (long lenth of stay)
- 퇴원 시 진단명 (discharge diagnoses)
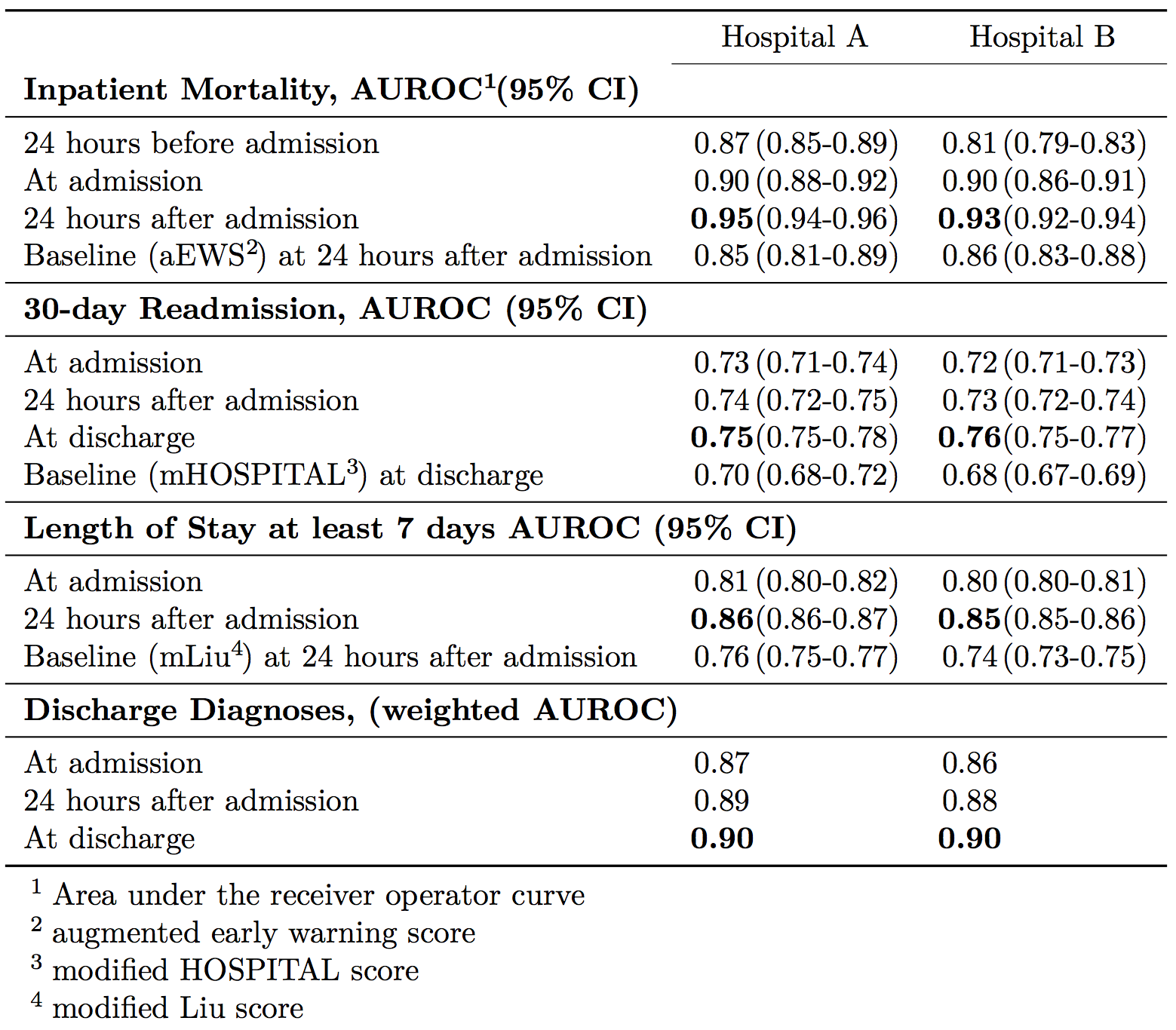
구글은 이러한 네 가지 항목에 모두에 대해서, 딥러닝을 기반으로 만든 인공지능이 기존의 인공지능보다 더 정확하다는 것을 증명했다. 예를 들어 입원 환자의 사망 예측에 대해서는 입원 후 24시간 이후까지의 데이터에 기반하면, UCSF와 UCM 두 병원 각각 AUC 0.95, 0.93의 높은 예측률을 보였다. 기존에 가장 높은 정확도를 보였던 aEWS 모델은 같은 데이터에 기반하면 AUC가 각각 0.85, 0.86에 그쳤다.
뿐만 아니라, 기존 모델에 비해서 구글의 인공지능은 사망 고위험군에 대한 거짓 경보(false alert)를 절반 정도로 줄일 수 있었다. 기존 시스템 대비 구글의 거짓 경보율은 UCSF에서 7.4 vs 14.3, UCM에서 8.0 vs 15.4로 크게 낮았다. 이러한 거짓 경보의 감소는 실제 의료 현장에서 인공지능이 사용되기 위해서 중요한 의미를 가진다. 거짓 경보가 너무 잦은 인공지능은 의료진의 ‘경고 피로(alarm fatigue)’를 초래해서 결국 양치기 소년 취급을 받아서 경보 자체를 무시하게 되기 때문이다.
특히 흥미로운 것은 구글의 예측 모델을 활용하면, 기존의 aEWS 모델보다 24시간 혹은 48시간까지도 더 일찍 환자의 사망을 예측할 수 있다는 점이다. 환자의 입원 후 24시간 이후의 데이터가 아니라, 입원할 때, 혹은 입원 24시간 이전의 데이터를 쓰더라도 aEWS와 비슷한 정도의 정확도가 나오기 때문이다. 구글은 UCSF의 경우 입원 24시간 이전 데이터만으로 AUC가 0.87, UCM의 경우 입원 시의 데이터만으로 AUC 0.90을 달성했다. 따라서 두 병원에 대해 구글의 예측 모델이 각각 48시간, 24시간 더 일찍 예측할 수 있다는 해석이 가능하다.
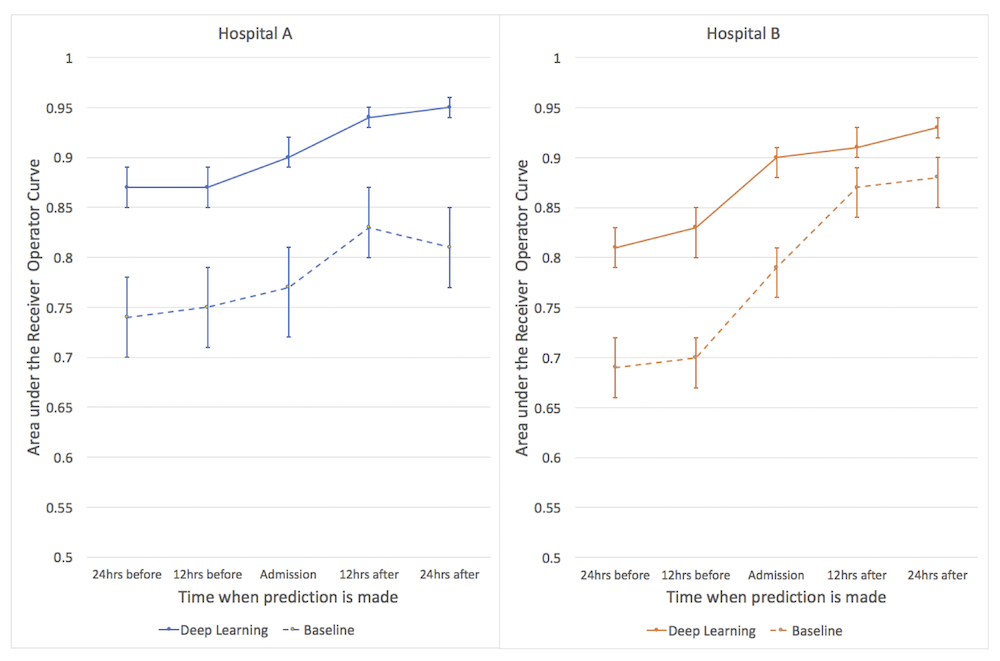
구글의 인공지능은 기존 방법에 비해 사망 가능성을 24-48시간 일찍 예측할 수 있다
이와 마찬가지로 재입원 가능성 및 장기 입원 여부에 대해서도 기존의 다른 예측 모델보다 더 이른 시간에 예측할 수 있었다. 30일 내 재입원 가능성은 기존 mHOSPITAL 알고리즘이 퇴원 시에 예측한 정확도 (두 병원의 AUC 가 각각 0.7, 0.68)를 구글의 알고리즘은 입원 시에 심지어 더 정확하게 (AUC 0.73, 0.72) 예측할 수 있었다. 또한 장기 입원 여부도 기존의 mLiu 알고리즘이 입원한 뒤 24시간 후의 데이터에 기반한 정확도(AUC 0.76, 0.74)보다 구글은 입원 시에 이미 더 높은 정확도 (AUC 0.81, 0.8)로 예측할 수 있었던 것이다.
또한 구글의 알고리즘은 환자가 퇴원할 때 어떤 진단명을 가지게 될지를 정확히 예측했다. 진단을 체계적으로 예측하기 위해서 진단명에 국제 표준으로 사용되는 ICD 코드를 이용하였다. 이 코드는 크게 22가지 항목으로 구성되어 하위분류까지 들어가면 진단을 세부적으로 구분하여, 총 14,025개로 나누고 있다. 이 코드는 질병을 매우 세부적으로 나누기 때문에, 인공지능이 이 코드에 기반하여 진단명을 정확하게 예측하기는 아주 어렵다고 할 수 있다.
예를 들어서, 제2형 당뇨병(E11)만 하더라도, 세부적으로 비증식성 당뇨성 망막병증(nonproliferative diabetic retinopathy)이 약하게(mild) 동반된 경우 (E11.32), 중간(moderate) 정도로 진행된 경우 (E11.33), 그리고 심하게(severe) 진행된 경우(E11.34)까지도 구분하고 있다. 그런데 구글의 인공지능은 환자가 입원할 때 이미 AUC 0.87의 정확도로 진단명을 예측할 수 있다. 이번 연구는 진단 명을 ICD 코드까지 사용해서 상세하게 분류한 최초의 연구이며, 따라서 정확도를 비교할 수 있는 기존 연구 자체가 없다.
이렇게 인공지능을 통해서 입원 환자의 사망 위험도, 재입원 가능성, 장기 입원 여부, 진단명 등 환자의 치료 결과와 예후에 대해서 미리 예측할 수 있다면, 환자의 치료 뿐만 아니라, 병원의 제한적 자원의 효율적 운영이나 비용 절감 등에도 큰 도움이 될 수 있을 것이다.
인공지능이 주목하는 데이터
그렇다면 실제로 구글의 인공지능은 특정 환자의 진료 기록 중에 어떠한 부분에 기반하여 치료 결과를 예측하는 것일까. 딥러닝은 기본적으로 블랙박스이기 때문에 내부에서 어떠한 방식으로 판단하는지 파악하기가 쉽지 않고, 때로는 성능은 좋지만 전혀 의미 없는 엉뚱한 데이터를 학습해서 우리가 원하지 않는 방식으로 계산된 결과를 내어놓을 수도 있다. 때문에 딥러닝이 실제 어떠한 계산 과정을 거치는지를 파악해보는 것은 중요하다. (딥러닝의 블랙박스 문제에 대해서는 이 포스팅을 참고하시기 바랍니다)
이 연구에는 전이성 유방암 환자 한 명의 진료 기록을 예시로 들어서 설명하고 있다. 이 환자가 입원한 후 24시간이 흐른 후의 시점에서 사망 위험도를 예측한 것이다. 그때까지 쌓인 175,639개의 데이터를 분석한 결과 구글의 인공지능은 사망 위험도를 19.9%로 예측한 것에 반해, 기존의 aEWS는 9.3%로 예측했다. 실제로 입원 10일 후에 해당 환자는 사망하였다.
구글은 TANN (Time-Aware Neural Network)이라는 기술을 통해서 인공지능이 환자의 전체 진료 기록 중에서 특히 어느 부분을 중요하게 보았는지를 파악해보았다. 그 결과 실제로 환자의 사망 위험도와 관계가 높은 데이터에 인공지능이 주목하고 있음을 알 수 있었다. (아래 그림에서 빨간색으로 표시된 부분) 예를 들어, 구글의 인공지능은 진료 노트를 분석해서 농양(empyema), 흉수(pleural effusions) 등에 집중하였고, 간호 기록에서는 반코마이신, 메트로니다졸 등의 항생제 투약, 그리고 브랜든 수치에 기반해서 욕창(pressure ulcer)의 위험이 높음을 주목하였다. 또한 흉부에 삽입하는 튜브(카테터)의 상표인 ‘PleurX’도 중요 단어로 파악했다. 이에 반해 기존의 aEWS는 유방암 환자의 사망 위험도와 상대적으로 관계가 낮아 보이는 알부민, 맥박, 백혈구 수 등을 중요하게 판단하였다고 밝히고 있다.
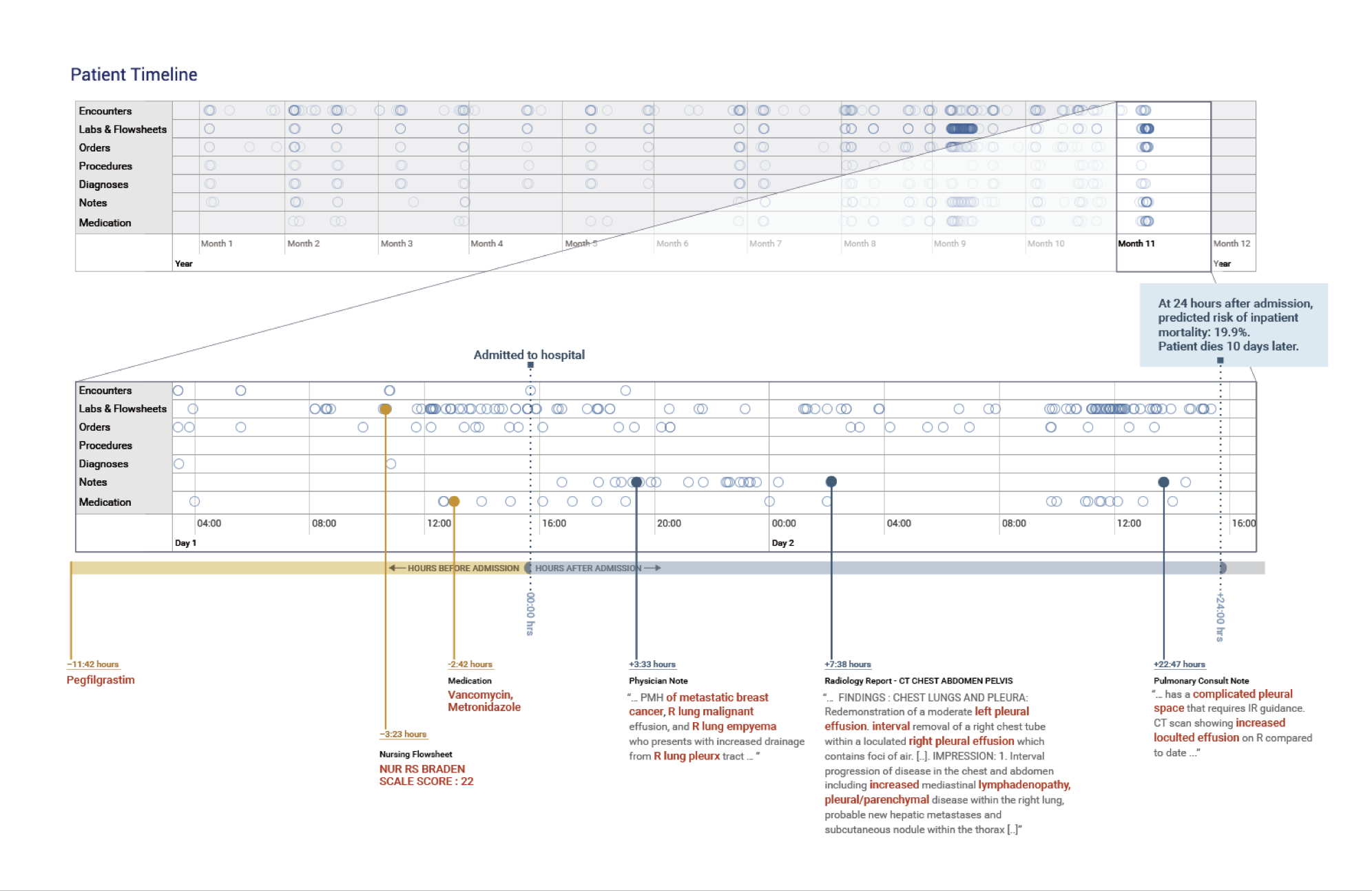 구글의 인공지능은 실제로 사망과 연관성이 높은 데이터를 중요하게 생각했다
구글의 인공지능은 실제로 사망과 연관성이 높은 데이터를 중요하게 생각했다
이번에는 전자의무기록에 저장된 방대한 의료 데이터를 정확하게 분석해서 입원 환자의 사망 가능성, 재입원, 장기 입원 여부, 진단명 등을 정확하면서도 조기에 예측할 수 있는 구글의 인공지능을 살펴보았다. 이는 의료 인공지능의 필자가 언급한 세 가지 유형 중에 첫 번째 유형, ‘복잡한 의료 데이터를 분석하여 의학적 통찰력을 도출하는 인공지능’의 또 다른 사례로 볼 수 있을 것이다.
그동안 전자의무기록은 여러 기술적인 한계 때문에 체계적이고 효율적인 예측 모델을 개발하는 것이 쉽지 않았다. 하지만 딥러닝 등 인공지능 기술의 발전을 덕분에, 자연어로 기록되어 있는 의료진의 진료 노트를 비롯하여 EHR에 저장되어 있는 전체 데이터를 효과적으로 분석함으로써 환자의 치료와 병원에 운영에 유용한 인사이트를 얻을 수 있었다. 아직 이 인공지능은 두 개의 병원에서만 검증되었으나, 확장 가능하도록 개발되었기 때문에 다른 병원에서도 추가적으로 검증이 용이하리라고 생각한다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.