우리는 지금 의료 인공지능의 세 가지 유형 중에, 첫번째인 ‘복잡한 의료 데이터를 분석하여 의학적 통찰력을 도출하는 인공지능’을 살펴보고 있다. 대표적인 사례로 최근 많은 주목을 받고 있는 IBM 왓슨 포 온콜로지를 앞서 자세하게 살펴보았으나, 왓슨 이외에도 의료 빅데이터를 기반으로 의학적인 통찰력을 얻으려는 연구는 다양하게 진행되고 있다.
이러한 연구들의 경우, 미래의 질병의 발병을 예측하고, 환자별 맞춤 치료를 실현하거나, 신약 임상 시험 진행의 효율성을 높이고, 재입원율이나 의료 비용을 낮추려는 등의 목적을 가지고 있다. 이러한 연구 중에는 특히 대규모 환자군의 과거 진료 기록을 바탕으로 질병의 발병을 예측하며, 질병 위험군을 분류하며, 퇴원 후 재입원율 등의 치료 결과를 예측하려는 연구가 활발하다 [1, 2, 3, 4, 5].
데이터 기반의 심혈관 질환 예측
이러한 연구 중에 인공지능을 통해 전자의무기록(EMR)에 저장되어 있는 대규모 환자들의 진료 기록을 분석하여 심혈관 질환의 위험군을 성공적으로 예측한 연구를 살펴보려고 한다. 통계에 따르면 2012년 한 해 동안 1,750만 명이 심장마비, 뇌졸중 등의 심혈관계 질환으로 목숨을 잃었다. 만약 우리가 어떤 사람이 이러한 위험에 처했는지를 미리 알아낼 수 있다면, 많은 생명을 살릴 수도 있을 것이다.
심혈관계 질환에 위험성이 높은 사람들을 가려내기 위해 현재 의료계에서는 미국 심장병 학회(American College of Cardiology)와 미국 심장 협회(American Heart Association)가 만든 ACC/AHA 가이드라인을 활용한다. 이 가이드라인에는 나이, 콜레스테롤 수치, 혈압, 흡연, 당뇨병 등의 여덟 가지 위험 요소에 기반하고 있다. 이는 기존의 의학계의 연구와 경험을 기반으로 뽑은 수치들이다.
그런데 현재 통용되고 있는 경험 기반의 기준이 정말로 최선의 예측 모델일까? 혹자는 이러한 기존의 가이드라인이 개별 환자의 특성과 다른 질병의 영향, 생활 습관 등을 반영하지 못하며, 다양한 위험요소들을 충분히 반영하고 있지 못하고 있다고 평가하기도 한다. 예를 들어, 심근경색(myocardial infractions)과 뇌졸중의 절반은 심혈관 질환의 위험군이 아닌 사람에게서 나타난다는 연구 결과도 있다. 사실 예측력이 절반에 그친다는 이야기는 동전을 던져서 판단하는 것과 차이가 없으니 결국 아무런 예측도 하지 못한다는 이야기다. 이와 같이 기존의 가이드라인이 심혈관 질환 위험군의 판별에 실패하고 있고, 위험도가 높지 않은 환자들이 불필요한 예방적 치료를 받고 있다는 비판도 나온다.
그렇다면 심혈관계 질환의 발병에 어떤 위험 요인이 영향을 미치는지를 사람이 아닌 인공지능이 분석해본다면 어떻게 될까? 사람의 경험에 기반한 선입견을 배제하고, 과거의 진료 및 발병 기록에 대한 데이터에만 근거하여 분석한다면 다른 결과가 나올 수도 있지 않을까.
연구에 따르면 인공지능이 편견과 선입견을 배제하고 온전히 데이터에만 기반하여 선정한 위험 요소는 기존의 표준 가이드라인과 상당부분 차이가 있었다. 더 나아가, 인공지능이 선택한 기준이 기존의 표준 가이드라인에 비해서 심혈관 질환의 발병을 더 정확하게 예측할 수 있는 것으로 나타났다. 다시 말해, 이는 인공지능의 기준을 따랐다면 과거에 더 많은 사람들의 목숨을 구할 수 있었다는 의미이다.
의료계 표준 가이드라인 vs. 인공지능이 만든 가이드라인
영국 노팅햄 대학교의 스테판 웽(Stephen Weng) 박사 연구팀은 인공신경망 등 네 가지 기계학습 알고리즘을 통해서 378,256명의 환자의 전자의무기록(EMR)에 포함되어 있는 진료 기록을 분석하여, 심혈관 질환의 발병과 관련된 패턴을 파악하려고 했다. 네 가지 종류의 인공지능 알고리즘은 2005년까지의 진료 기록을 학습해서, 완전히 새로운 ‘가이드라인’을 각각 만들어 낸 것이다. 연구진에 따르면, 이 연구는 일반 환자들의 진료 기록을 바탕으로 질병의 예후를 평가하는 첫번째 대규모 연구였다.
흥미롭게도 인공지능이 파악한 심혈관 질병 관련 주요 위험요소(risk factor)들은 상당부분 기존의 표준 가이드라인에는 포함되지 않았던 것으로 나타났다. 각 방식별로 가장 중요한 위험요소를 10개씩 뽑아본 결과 인공지능은 인종적 차이(ethnicity), 정신질환이나, 경구용 스테로이드(oral corticosteroid) 복용 등을 심혈관계 질환의 주요 위험 요소로 꼽았지만, 이는 기존의 가이드라인에는 찾아볼 수 없던 것들이다. 반대로 ACC/AHA 가이드라인에는 당뇨병이 포함되어 있었지만, 인공지능은 이를 중요 위험 요소로 꼽지 않았다.
이러한 결과에서 우리는 인공지능을 통해서 완전히 데이터에만 기반하여 질병 발병과 관련된 주요 위험 요소를 분석하면, 기존의 의학계에서 경험적으로 받아들이던 기준과 차이가 있을 수 있다는 것을 알 수 있다. 그런데 이러한 방법론 중에 어느 모델이 미래의 질병을 예측하기 위해서 더 효과적이었을까?
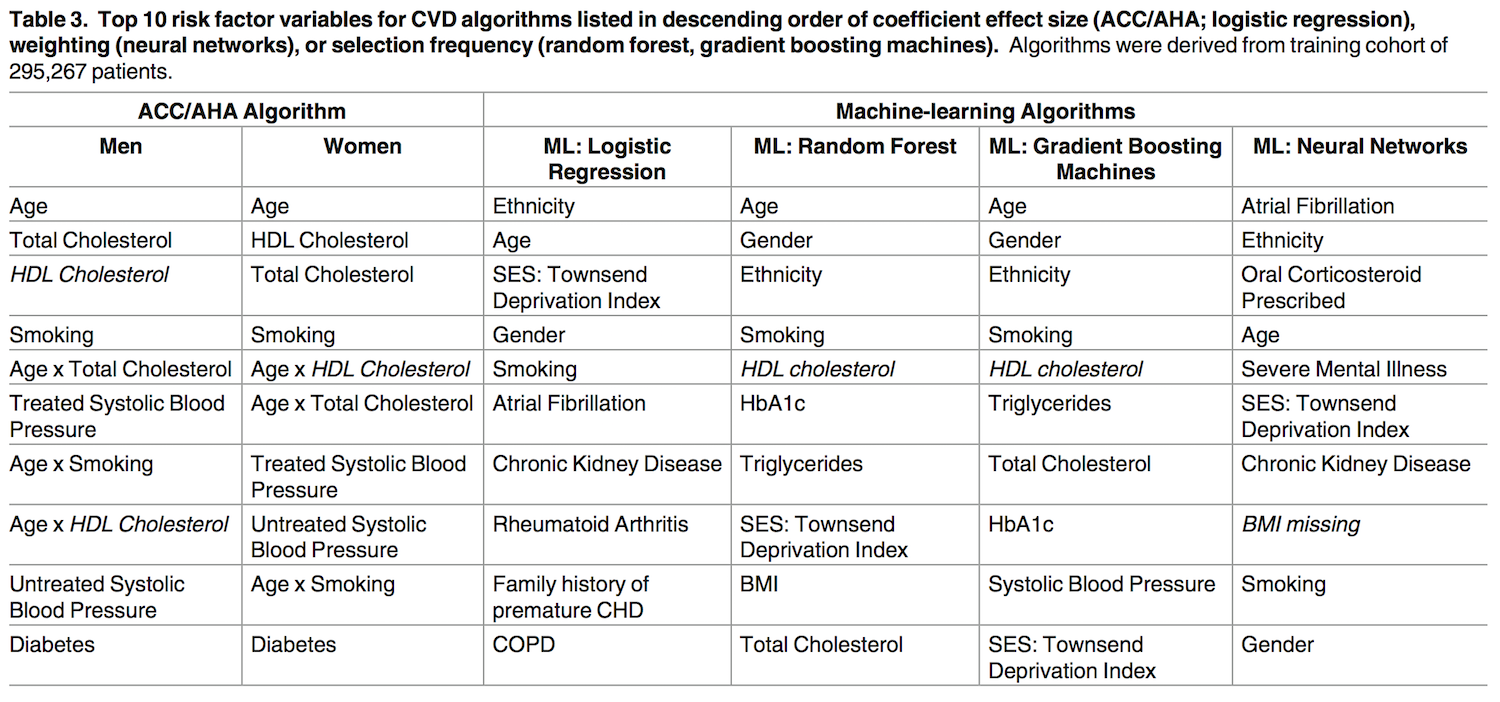
기존의 ACC/AHA 가이드라인의 위험 요소와 인공지능이 데이터 기반으로 추출한 위험 요소 (PLoS ONE 2017)
인공지능의 심혈관 질환 발병 예측
결과적으로 데이터에 기반한 인공지능의 분석이 기존 의료계에서 통용되던 가이드라인보다 더 효과적인 것으로 드러났다. 인공지능이 2005년까지의 데이터를 학습하여 만든 모델을 기반으로, 새로운 환자군에 대해서 이후 10년 동안 심혈관계 질환의 발병 여부를 예측한 결과, 네 가지 인공지능 알고리즘 모두 기존의 ACC/AHA 가이드라인보다 현저히 나은 성과를 보인 것이다. (378,256명의 환자의 데이터 중에 80%는 인공지능을 학습시키고, 나머지 20% 환자의 데이터로 인공지능의 정확성을 테스트하였다)
표준 가이드라인의 정확도는 0.728 이었던 것에 반해, 네 가지 인공지능 알고리즘은 0.745부터, 가장 정확한 인공신경망의 경우 0.764 였다. 즉, 인공신경망의 경우 표준 가이드라인보다 7.6% 더 많은 환자에 대해서 심혈관 질환의 발병을 정확히 예측하였고, 잘못 예측하는 경우는 1.6% 더 적었다. 이는 전체 환자에 대해서 10년 동안 355명의 추가적인 환자에 대해서 심혈관 질환의 발병을 정확히 예측할 수 있었던 수치였다.
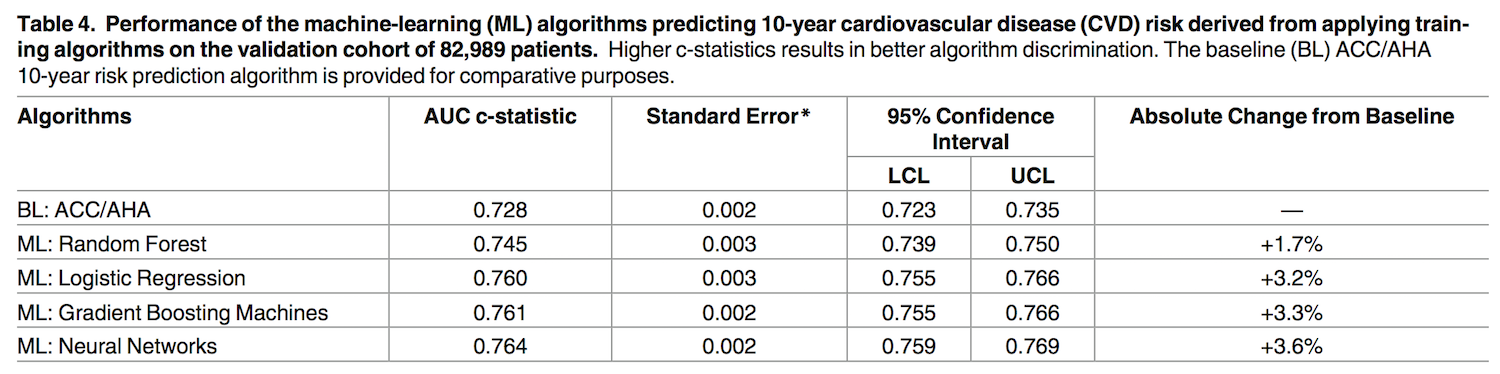
네 가지 인공지능 모델 모두 ACC/AHA 가이드라인에 비해서 정확도(AUC)가 높다 (PLoS ONE 2017)
과거에는 진료기록과 같은 의료 빅데이터가 있더라도, 사람의 힘으로 이 방대한 데이터를 면밀하게 분석하고 통계적으로 유의미한 모델을 만들어내기가 어려운 경우가 많았다. 때문에 현실적으로 전문가의 직관이나 경험칙에 의존할 수밖에 없었다. 하지만 이제 우리는 막강한 연산능력과 저장능력 뿐만 아니라, 다양한 방식의 인공지능까지 활용할 수 있으므로 의료 빅데이터를 일일이 분석하여 적합한 수학적인 모델을 만들어낼 수 있다. 그렇게 도출된 인공지능 모델이 과거의 전문가들의 경험으로 만들어낸 기준보다 더 나을 수 있음을 이 연구는 보여주고 있다.
스탠퍼드 대학의 혈관 외과의사인 엘시 로스(Elsie Ross)는 “이 연구의 중요성은 아무리 강조해도 지나치지 않다”며, “의사들이 환자의 치료를 위해서 인공지능을 받아들여야 할 것이다”고 밝혔다.
이 연구에 대해서 마지막으로 첨언하고 싶은 것은 바로 딥러닝(deep learning)에 관한 것이다. 만약 연구에서 딥러닝을 활용했다면 결과가 더 좋게 나왔을 수 있다. 이 연구에서 시도한 네 가지 인공지능 방법 중에 가장 정확했던 것은 다름 아닌 인공신경망(artificial neural network)였다. 추후 조금 더 자세히 설명하겠지만, 딥러닝은 인공신경망을 더 발전시켜서 나온 방법론이다. 사람의 뇌에 있는 신경의 네트워크를 모방한 것이 인공신경망으로, 그 네트워크의 은닉층(hidden layer)을 더 쌓는 방식으로 더 ‘깊고’ 정교하게 만든 것이 바로 딥러닝이다. 대부분의 경우 인공신경망보다 딥러닝의 퍼포먼스는 훨씬 더 좋게 나온다.
앞으로 이런 연구에 딥러닝 등의 다양한 방법들이 시도되면서, 환자의 진료기록을 비롯한 의료 빅데이터를 기반으로 환자의 질병 예측과 관리, 치료에 활용할 수 있는 의학적 통찰력을 더욱 많이 얻을 수 있을 것이다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.