과연 의사는 인공지능으로 대체될 수 있을까. 실리콘밸리의 선각자이자 유명 벤처투자가인 비노드 코슬라(Vinod Khosla)는 몇 년 전 ‘미래에는 80%의 의사가 첨단 기술로 대체될 것’이라고 공개석상에서 주장한 바 있다.[ref 1, 2, 3, 4]
그는 의료의 많은 부분이 여전히 근거에 기반을 둔 과학이라고 보기 어렵다며, 대규모의 데이터에 기반하고 막강한 연산 능력으로 무장한 기계가 평균적인 의사보다 더 저렴하면서도 정확하고 객관적일 수 있다고 언급했다. 그는 ‘닥터 알고리즘(Doctor Algorithm)’의 실력은 갈수록 좋아져서, 어려운 치료 사례에 대해서도 모든 가능성을 고려하여 2차 소견을 제공하면서 진료실에서의 영향력은 더 커질 것이라고 했다. 또한 많은 경우 의사들의 진료에 일관성이 부족하고, 편차가 크다는 점도 지적했다.
또한 오늘날 의사가 환자를 진료하는 방식, 즉 환자가 직접 병원을 방문하고, 환자가 증상을 의사에게 이야기하고, 몇 가지 검사를 받고, ‘종이로 된’ 처방전을 받아서 약국을 직접 방문하는 프로세스의 많은 경우가 디지털 기술의 영향을 받을 것으로 보았다. 이러한 과정에서 상위 20%의 의사들은 살아남겠지만, 그저 그런 실력을 가진 80% 의사들은 대체될 수도 있다고 본 것이다.
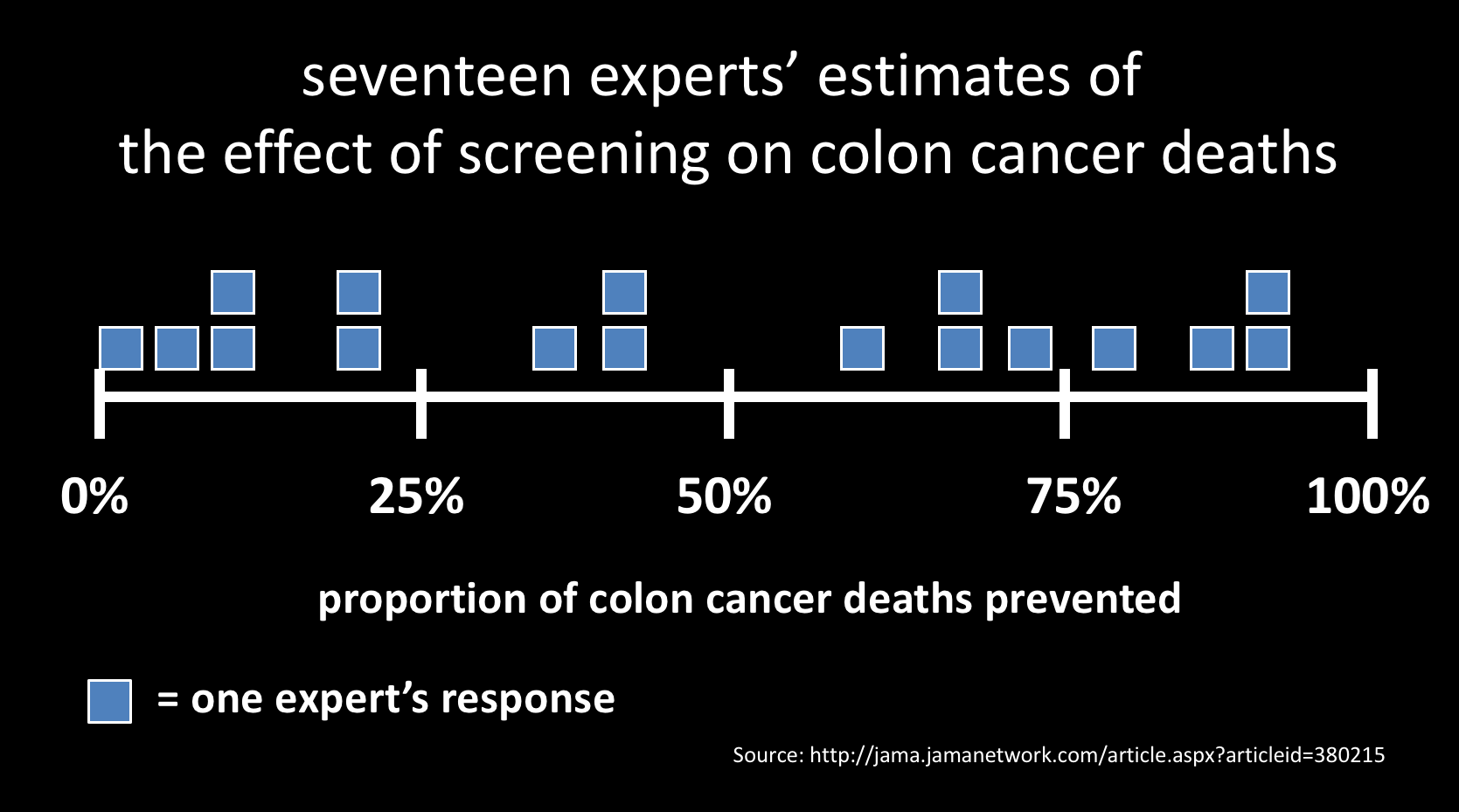 비노드 코슬라의 2013년 Stanford Medicine-X 발표 자료 중 일부
비노드 코슬라의 2013년 Stanford Medicine-X 발표 자료 중 일부
대장암 관련 의사들의 판단에 편차가 매우 크다는 점을 지적하고 있다.
비노드 코슬라는 선마이크로시스템즈(Sun Microsystems)를 창업한 실리콘밸리 IT 분야의 입지전적인 인물로, 지금은 자신의 이름을 딴 코슬라 벤처스(Khosla Ventures)라는 벤처캐피털을 이끄는 전설적인 벤처투자가다. 코슬라 벤처스는 코슬라의 주장대로 여러 인공지능 및 헬스케어 스타트업에 많은 투자를 해왔다. 이렇게 IT 업계에서 영향력 있는 인물의 도발적인 발언은 즉시 의료계 내외부에서 격렬한 찬반양론을 불러일으켰다 [ref 1, 2, 3, 4, 5].
개중에는 ‘실리콘밸리는 의학을 이해하지 못한다’는 반응이 있는가 하면, 비잔 사레히자드(Bijan Salehizadeh)라는 컬럼비아 의대 출신의 의사는 ‘역겹다(Getting nauseated)‘라고까지 했다. 디지털 헬스케어 분야의 선구자로 과감한 주장을 많이 하는 스크립스 연구소의 에릭 토폴 박사도 기술에 의한 의료의 변화라는 큰 흐름에는 동감하지만, 80%라는 수치에는 동의하지 않는다며 한 발짝 물러섰을 정도였다.
이것이 2012년의 이야기였다.
만약 같은 주장을 오늘날에 듣게 된다면 이제는 어떨까. 당시에는 의학을 모르는 타 분야 전문가의 허무맹랑한 주장 정도로 치부되었을 이야기가, 지금에 이르러서는 그리 가볍게 느껴지지 않는다. 그만큼 지난 몇 년 동안의 짧은 기간 동안 인공지능 기술이 폭발적으로 발전했기 때문이다. 그동안 인간 의사 수준의 혹은 그 이상의 실력을 가지는 인공지능 연구들이 쏟아져 나오기 시작했고, 몇몇 병원에서는 인공지능을 실제로 도입하기에 이르렀다. 추후 더 자세히 설명하겠지만, 현재 인공지능의 부흥을 이끌고 있는 딥러닝(deep learning) 기술이 처음 화제가 되기 시작한 것도 공교롭게도 비노드 코슬라의 주장이 있었던 2012년이었다.
인공지능이 의사를 정말로 대체할 수 있을지는 여전히 논쟁의 대상이다. 이 문제에 대해서도 앞으로 심도 있게 논의해보도록 할 것이다. 하지만 이제는 인공지능에 의해서 미래의 의료와 의사의 역할이 어떤 식으로든 상당히 달라지게 될 것이라는 주장 자체에는 의료계 내부에서도 큰 이견이 없어 보인다.[ref 1, 2, 3]
관련 포스팅
- 인공지능에 맞서 ‘인간’ 의사는 어떻게 대처해야 하는가
- 의사, 이제는 인공지능의 습격에 대비할 때
- ‘닥터 알파고’ 의 세 가지 역할
- 디지털 의료는 어떻게 구현되는가 (15) 인공지능
Rise of the Machines
최근 한국에서는 ‘제 4차 산업혁명’ 광풍이라고 불릴 정도로 인공지능이라는 분야가 주목을 받고 있다. 각종 정부 정책, 도서, 강의, 심지어는 관련 학원까지 성행하고 있다. 하루가 멀다 하고 언론에서도 인공지능이 오르내리며, 대선 주자들도 하나같이 ‘제 4차 산업 혁명’을 주요 어젠다로 외쳤을 정도이니까 말이다.
사실 필자로서는 이러한 현상을 보자면 무척 감회가 새롭다. 필자는 전작 ‘헬스케어 이노베이션’에서 상당 부분을 할애하여 IBM의 인공지능 왓슨을 집중적으로 다룬 바 있다. 하지만 최근까지도 왓슨을 소개하면 국내 의료계에서의 반응은 그저 미적지근하거나, ‘신기하네’ 정도였다.
알파고 사태 직전이었던 2016년 2월만 하더라도 마찬가지였다. 당시 개원가 의사들을 중심으로 구성된 한 의료계 협회의 강의에서 IBM 왓슨, 딥러닝 등의 인공지능을 강조하였지만, 결국에 쏟아지던 것은 오로지 원격진료에 대한 질문이었다. ‘원격진료는 의사라는 직업 자체를 위협하지는 않지만, 인공지능은 더욱 근본적인 변화를 야기할 수 있다’고 필자가 강조했지만, 역시 별다른 반응을 얻지 못하고 또 원격진료 질문이 나와서 씁쓸했던 기억이 난다.
하지만 불과 한 달만에 상황은 급반전되었다. 알파고 사태와 ‘제4차 산업혁명’이라는 키워드와 맞물리며 인공지능이 돌연 국가적인 관심사로 떠오른 것이다. 사실 알파고와 이세돌 9단의 대국도 첫판이 끝나기 전에는 대중들의 관심을 크게 받지 못했던 것을 기억한다면 격세지감이라 할만하다. (참고로 ‘제4차 산업혁명’ 이라는 용어는 한국에서만 사용되는 것으로, 필자는 되도록 이 표현을 사용하지 않도록 하겠다.)
다른 여러 분야와 마찬가지로, 인공지능에 대한 관심이 폭발적으로 높아진 것은 국내 의료계도 예외가 아니다. 병원과 학회에서도 앞다투어 인공지능이 화두로 등장하고, 몇몇 대학병원은 이미 발 빠르게 관련 연구소와 센터를 만들어서 국가 연구 과제를 수주하고, 관련 기업과의 공동 연구도 활발해지고 있다. 식약처에서는 의료 인공지능 소프트웨어의 허가심사 규제 가이드라인까지 내어놓았다. (이 과정에는 필자도 참여했다)
 길병원의 인공지능 다학제 진료실 풍경. 환자 정면의 모니터에 IBM 왓슨을 띄워놓고,
길병원의 인공지능 다학제 진료실 풍경. 환자 정면의 모니터에 IBM 왓슨을 띄워놓고,
관련 진료과의 여러 의사들이 참여하여 암환자를 진료한다.
IBM 왓슨도 더 이상 머나먼 타국의 이야기가 아니게 되었다. 2016년 9월 가천대 길병원을 필두로, 이후 부산대병원, 건양대병원, 대구가톨릭병원, 계명대 동산병원 등이 암환자의 진료를 위한 왓슨 포 온콜로지(Watson for Oncology)를 도입했다. 나중에 자세히 논의하겠지만, 이렇게 국내 병원 진료실에도 인공지능이 전격적으로 도입되면서 적지 않은 논란을 던져주었다. 필자는 이렇게 인공지능을 병원으로 받아들이는 과정에서 의료계의 고민이 충분하지 못했으며, 시급히 해결해야 할 과제들이 많이 산적해 있다고 생각한다.
싫든 좋든 알파고 사태 이후로 한국은 인공지능이라는 분야에서는 완전히 새로운 전기를 맞게 되었다. 이러한 전환점이 장기적으로 독이 될지 득이 될지는 아직도 미지수다. 우리가 미래를 미리 대비하는 계기가 되었다는 긍정적인 역할을 할 수도 있고, 아니면 기술에 대한 막연한 환상과 두려움을 심어주며 사회에 불필요한 혼란을 야기하는 부정적인 역할로 끝날 수도 있을 것이다. 이는 지금부터 우리가 무엇을 어떻게 할 것인지에 달려 있을 것이다.
관련 포스팅
제2의 기계 시대
하지만 어떤 방식으로든 인공지능이 인류의 미래에 큰 역할을 할 것이라는 전제 자체를 부인하는 사람은 없는 것 같다. 서두에서도 언급했지만, 대중들이 가장 크게 관심을 가지는 부분은 아마도 인공지능의 능력이 어디까지 발전할 것이며, 인간을 얼마나 대체할 수 있는지일 것이다.
이세돌 9단의 예기치 못한 패배는 다른 분야의 인간 전문가들에게도 큰 위기의식을 심어주었다. 고차원적인 사고와 인간 특유의 직감까지 필요한 바둑에서 기계가 인간 최고수를 능가할 정도라면, 바둑 이외의 다른 분야에서도 향후 인간 전문가들의 자리를 위협할 수 있다는 충분한 가능성을 보여주었기 때문이다.
인공지능이라고 하면, 흔히 ‘터미네이터’의 스카이넷과 T-2000이나, ‘2001 스페이스 오디세이’의 HAL을 떠올리게 될지도 모르겠다. 인공지능이 T-2000 처럼 기관총을 들고 나타나 보이는 대로 인간을 말살하지는 않더라도, 지금까지 인간만이 할 수 있는 고유의 역할이라고 간주되던 것들을 대신하고, 부를 편중시키고, 대규모 실업을 야기한다면 이 역시 사회, 경제, 문화적으로 큰 충격이 될 것이다.

사실 인류의 역사를 돌이켜보면 기술의 발전에 의해서 인간의 역할이나 직업 안정성에 근본적인 변화를 맞이했던 것은 이번이 결코 처음은 아니다. 필자가 인공지능을 이야기할 때면, 읽어보기를 권하는 몇 권의 책 중에 MIT의 에릭 브란프슨과 앤드루 맥아피 교수가 쓴 ‘제2의 기계 시대(The Second Machine Age)‘ 라는 책이 있다. 현실로 다가오는 인공지능을 여러 측면에서 분석하려는 시도들이 있지만, 이 책은 특히 사회적, 경제적 파급효과에 대해서 주로 다루고 있다.
이 책의 제목, ‘제2의 기계 시대’ 라는 것이 바로 인공지능에 의해서 도래한 것이다. 그런데 이 제목은 우리가 이미 ‘제1의 기계 시대’를 거쳐왔다는 것을 암시한다. 이는 다름 아닌 증기 기관의 발명에 의한 산업 혁명을 의미한다. 1776년 영국의 제임스 와트가 발명한 상업용 증기 기관은 인류의 역사를 완전히 바꿔놓았다. 이 기계 덕분에 인류는 비로소 인간과 가축의 근육이라는 한계를 넘어설 수 있게 되었기 때문이다. 증기기관의 발명 덕분에 우리는 대량 생산, 철도 등을 만들 수 있었으며, 현대 산업 문명 자체를 이룩할 수 있었다고 해도 과언이 아니다.
하지만 이러한 기술 혁신 덕분에 모두가 혜택을 받고 행복해진 것은 아니었다. 18세기 초까지만 해도 영국의 산업은 숙련공들이 공장에 모여 협업을 통해 규격화된 제품을 생산하는 공장제 수공업이었다. 하지만 증기기관이 발전함에 따라서, 자신의 신체를 이용해서 일하던 블루 컬러 노동자들은 일자리를 잃어버릴 수밖에 없었다. 이를 소위 기술적 실직(technological unemployment)이라고 불렀다. 그들은 러다이트(Luddite) 운동으로 대표되는 기계 파괴 운동으로 저항했지만, 결국 시대의 도도한 흐름을 거스르지는 못했다.
(주: 러다이트 운동은 노동자들이 산업혁명으로 자본주의 시장경제가 자리 잡아가던 시기에 자신의 권익을 요구한 최초의 노동운동으로 의미가 있지만, 여기에서는 기술적 실직이란 부분에만 집중하기로 한다.)
과거 ‘제1의 기계시대’를 이끈 증기 기관이 인간 근육의 한계를 넘어섰다면, 이제 ‘제2의 기계시대’를 이끄는 인공지능은 인간 두뇌의 한계를 넘어서는 것이라고 할 수 있다. 이제 기술적 실직의 위험에 처한 사람들은 근육을 사용하던 블루 컬러 노동자가 아니라, 본래 두뇌를 사용해서 일하던 화이트 컬러, 혹은 지식근로자(knowledge worker)일 것이다. 이 글을 쓰고 있는 필자 자신과 이 글을 읽고 있는 독자 대부분이 아마도 이 범주에 해당될 것이다.
기술적 실직의 전조
이렇게 인공지능에 의하여 지식 근로자가 기술적 실직을 맞게 되는 현상의 전조는 이미 여러 분야에서 광범위하게 나타나고 있다. 2015년 1월 AP통신은 애플의 지난 분기 실적에 대해서 ‘월스트리트의 예상치를 상회했다(Apple tops Street 1Q forecasts)’ 는 기사를 내어놓았다. 이 기사에는 월스트리트가 예상한 애플의 평균 실적, 애플의 매출, 연초 대비 주가 변동 등에 대해서 상세히 서술하고 있다.

일견 별다를 것이 없어 보이는 이 기사의 말미에는 “This story was generated by Automated Insights.” 라는 문구가 붙어 있다. 기사가 인간 기자가 아니라, 오토메이티드 인사이트라는 회사에서 개발한 인공지능에 의해서 작성되었음을 알리는 문구다.
AP통신은 2014년 중반 이 회사의 시스템을 도입하여 분기당 3,000 개의 기사를 인공지능이 작성하고 있다고 밝혔으며, 이 시스템을 통하면 1초에 2,000개의 기사를 쓸 수 있다고 한다. 2016년 7월부터 AP통신은 마이너리그 야구 기사도 이를 통해 자동으로 작성한다고 밝혔다. 오토메이티드 인사이트의 해당 문구만 구글에 검색해보아도 11만 개 이상이 검색된다.
이러한 ‘로봇 저널리즘’은 이제 상당히 일반화되어 있다. 지진이 잦은 서부 지역을 주무대로 하는 LA타임즈는 지진 발생 보도에 로봇을 활용한다. 이 ‘퀘이크봇’은 미국 지리조사청이 지진 정보를 감지하면, 진도와 발생 시각, 지점 등 기본 데이터를 바탕으로 즉시 기사를 쓴다. 인간 기자는 최종 확인만 하고 발행만 하면 된다. 2014년 3월 로스앤젤리스에서 강도 4.4의 지진이 발생했을 때, LA타임스는 8분 만에 속보를 낼 수 있었다.
이러한 과정이 지속된다면 언론계에서 인간 기자의 역할은 점점 줄어들 수밖에 없을 것이다. 시카고 트리뷴은 2012년부터 로봇이 작성한 뉴스를 제공하는 저너틱(Journatic)이라는 회사로부터 기사를 받기 시작했으며, 이런 과정에서 기자 20여명을 정리해고 했다고 한다.

인공지능의 습격에 변호사도 예외는 아니다. 2011년 뉴욕타임즈에는 “비싼 변호사들이 값싼 소프트웨어로 대체되고 있다(Armies of Expensive Lawyers, Replaced by Cheaper Software)”는 기사가 실렸다. 재판과 변론을 준비하기 위해서 변호사들은 수많은 판례, 관련 법률 등의 자료를 검토해야 한다. 과거에는 이런 과정을 모두 사람이 해야 했기 때문에 많은 변호사 및 법률 보조 인력이 필요했다. 하지만 이제는 인공지능 소프트웨어가 더 값싼 가격으로, 더 빠르게, 더 많은 자료를 검토해준다는 것이다.
2016년 5월에는 뉴욕의 대형 로펌 베이커 앤드 호스테틀러(Baker&Hostetler)가 인공지능 변호사 로스(ROSS)를 사용하기 시작했다는 것이 화제가 되었다. 로스는 IBM 왓슨을 기반으로 제작된 인공지능으로 자연어를 이해할 수 있다. 즉, 변호사가 평상시에 사용하는 언어로 질문을 하면, 질문의 의미를 이해하고 관련 판례와 법률을 분석하여 답을 내어 놓을 수 있다는 것이다.
로스 인텔리전스의 CEO 앤드루 애루다는 “변호사들은 로스에게 가설을 세우게 할 수도 있고, 로스가 세운 가설에 대해 질문할 수도 있다”고 언급했다. 로스는 특히 많은 분량의 문서를 읽고 정리해야 하는 파산 분야 업무를 맡았다고 한다. 이후 2017년 중순까지 미국에서는 14개 로펌에서 로스를 도입했다고 한다.
 인공지능 변호사 로스를 도입한 로펌들
인공지능 변호사 로스를 도입한 로펌들
이러한 변화는 변호사들의 일자리에도 위협을 주고 있다. 딜로이트 컨설팅의 2016년 발표에 따르면, 앞으로 10년 내 법조계에서는 39%에 해당하는 114,000개의 일자리가 자동화되어 사라질 것으로 예상되었다.[1, 2]
그런가 하면 보험사도 변화를 겪고 있다. 일본의 후코쿠 생명보험은 보험금 지급 여부를 심사하는 업무를 맡기기 위해 20억 원을 들여 IBM 왓슨 익스플로러를 도입하기로 했다. 이 보험사에서 왓슨은 보험 가입자의 병력, 입원 기간, 수술 유무 등의 의료 기록을 분석하여 보험료를 산정하는 업무를 하게 된다. 이 과정에서 기존에 보험금 지급을 심사하던 직원 34명은 해고당했다.
이렇게 인공지능의 도입을 바탕으로 후코쿠 생명보험은 생산성을 30% 향상시키고, 투자한 비용을 2년 내에 회수할 수 있을 것으로 기대했다. 도입 비용 20억 원에 연간 1억 5000만 원 정도의 유지보수 비용이 들어가지만, 왓슨을 통해 매년 14억 원 정도의 인건비를 절감할 수 있다는 것이다.
인공지능의 발전에 따라서 기자, 변호사, 보험 분석원 등의 기술적 실직은 이렇게 가시화되고 있다. 그렇다면 또다른 지식 근로자인 의사도 이러한 변화에서 영향을 받지는 않을까? 의사는 과연 기계와의 경쟁에서 살아남을 수 있을 것인가.
인공지능의 간략한 역사
‘의사와 인공지능이 경쟁하면 누가 승리할 것인가’라는 질문을 던지기에 앞서 우리가 해야 할 일이 있다. 먼저 이 질문의 범위를 정확히 정의해야 한다. 또한 그렇게 정의된 이 질문 자체가 타당한 질문인지도 고려해볼 필요가 있다. 질문의 범위가 잘못되면 막연하거나 지엽적인 답을 얻을 수밖에 없고, 잘못된 질문을 던지면 잘못된 답을 얻을 수밖에 없기 때문이다.
인공지능은 매우 폭넓은 분야이기 때문에 하위 주제의 일부만 고른다고 하더라도 책 한 권의 분량은 족히 나올 것이다. 따라서 우리가 의료 인공지능을 본격적으로 논의하려면 논의할 범위를 정의하는 것이 필요하다. 이를 위해 인공지능의 역사를 간략히 되짚어보고, 인공지능의 종류에 대해서도 살펴보도록 하겠다.
인공지능이 학문의 한 분야로 발돋움하게 된 것은 1950년대였다. 수학, 공학, 철학 등 다양한 영역의 학자들에 의해서 인공적인 두뇌의 가능성이 논의되기 시작한 것이다. 1956년 다트머스 대학교에서 10명의 과학자들이 모여 개최한 6주 동안의 인공지능 여름 워크샵은 인공지능 분야 최초의 학회로 간주된다. 이때 참가자들은 인공지능에 대해서 2개월 동안 10명의 인원이 참여하는 연구 과제를 록펠러 재단에 제출하며 아래와 같이 언급했다.
“학습이나 지능의 모든 특성을 자세하게 기술하여 이를 바탕으로 학습이나 지능을 모방할 수 있는 기계를 만들 수 있다는 생각으로 이 연구를 진행할 것입니다. 또한 언어를 사용하고, 관념과 개념을 형성하고, 지금은 오로지 인간만이 해결할 수 있는 문제들을 해결할 수 있으며, 스스로를 향상시킬 수 있는 기계를 만드는 방법을 찾으려고 시도할 것입니다. 신중히 선발된 과학자들이 이 여름 한철 동안 협력한다면, 이 문제들 중 몇 가지는 의미 있는 진척을 이룰 것으로 생각합니다.”
무척 자신만만하고 낙관적인 제안서가 아니라고 할 수 없다. 이 제안서에서는 자연어 처리, 신경망, 오토마타 이론, 추상화 능력, 창의력 등에 대해서도 언급된다. 이 중 대부분은 60여 년이 지난 지금도 완전히 해결되었다고 할 수 없으며, 여전히 인공지능 분야에서 중요한 연구 주제로 자리 잡고 있다.

1956년 다트머스 대학에서 열린 최초의 인공지능 컨퍼런스
인공지능의 연구는 이렇게 낙관적인 비전을 가지고 시작되었지만, 이후 60여 년에 걸친 기간 동안 많은 부침을 겪었다. 과대 선전의 대상이 되어 높은 기대를 받았던 때가 있었던가 하면, 또 발전이 정체되어 실망을 안겨주는 시기도 번갈아 나타났다. 이렇듯 인공지능은 황금기(1956-1974), 첫 번째 암흑기(1974-1980), 활황기(1980-1987), 두 번째 암흑기(1987-1993) 등의 부침을 겪으면서 발전해왔다. [ref 1, 2, 3]
최근에 이르러 또다시 맞이하게 된 인공지능의 활황기는 인공지능을 학습시킬 수 있는 방대한 데이터의 축적, GPU를 비롯한 하드웨어 기술의 발전을 통한 연산 능력의 향상, 그리고 딥러닝을 위시한 인공지능 알고리즘의 발전 등의 요소가 어우러진 결과물이다.
인공지능과 기계학습
근래에 언론 등에서 ‘인공지능’이라고 통칭되는 이 개념은 상당히 추상적으로 사용될 때도 있고, 어떤 경우는 딥러닝 등의 보다 구체적인 기술을 지칭하는 경우도 있다.
사실 인공지능을 구현하기 위한 학문적인 접근 방법은 매우 다양하다. 예를 들어, 한 때 가장 주목받았던 접근법 중의 하나는 전문가 시스템(expert system) 방식이었다. 이는 인간의 논리, 지식, 규칙을 규정하여 컴퓨터에 집어넣으려고 시도했다. 만약 인간의 모든 지식, 논리 등을 컴퓨터에 일일이 가르칠 수 있으면 인간과 같은 사고를 모사할 수 있을 것이라는 가정에서였다. 이러한 시스템은 항공, 철도, 자동차 등 특정 전문 분야의 지식을 학습시켜서 성공적으로 활용되기도 했다 [ref 1, 2].
그런가 하면, 인간의 뇌 자체를 역설계(reverse engineering)하여 두뇌의 기능을 컴퓨터로 시뮬레이션하려는 시도들도 있다. 2013년 유럽연합에서는 이러한 목적으로 ‘휴먼 브레인 프로젝트(Human Brain Project)‘를 출범하며, 10억 유로가 넘는 연구비를 지원하기도 했다. 기술적으로는 아직 많은 난관이 있지만, 언젠가는 인간이 뇌를 컴퓨터로 완벽하게 시뮬레이션할 수 있을지도 모른다. 만약 그렇게 될 수 있다고 가정한다면, 이는 곧 뇌가 불사의 존재가 된다는 뜻일지, 혹은 인간의 정신이 육체를 떠나 존재할 수도 있다는 것일지 등에 대한 형이상학적인 의문을 불러일으키기도 한다.
하지만 현재 인공지능에 대한 접근 방법으로 가장 많이 사용되고 있는 것은 역시 머신 러닝(machine learning), 즉 기계 학습이다. 기계 학습은 데이터를 기반으로 수학적인 방법을 통해서 컴퓨터를 인간처럼 학습시켜 스스로 규칙을 형성할 수 있도록 한다. 현재 인공지능의 대표적인 사례들로 알려진 검색 엔진, 스팸 메일 필터, 자율주행차, 음성 인식, 얼굴 인식, 왓슨, 알파고 등은 모두 이런 기계 학습을 기반으로 한다.
이러한 기계 학습이라는 분야에는 여러 가지 세부적인 방법론이 있다. 과거에는 은닉 마르코프 모델(Hidden Markov Model), 인공 신경망(Artificial Neural Network), 서포트 벡터 머신(Support Vector Machine) 등의 방법론이 있었다. 이런 방법론은 시대에 따라서 유행을 타기도 하고, 기술적으로 구현이 가능한지에 따라 부침을 겪기도 하면서 지난 수십 년에 걸쳐 발전해왔다.
![]() 인공지능 – 기계학습 – 딥러닝의 관계 (출처: NVIDIA 블로그)
인공지능 – 기계학습 – 딥러닝의 관계 (출처: NVIDIA 블로그)
딥러닝의 발전
그러던 지난 2010년 전후로는 기계학습 기법 중의 하나인 인공 신경망에서 발전한 딥러닝(deep learning)이라는 방법론이 급격하게 발전하면서, 적어도 지금은 기계학습의 여러 방법 중에서 단연 왕좌를 차지하고 있다. 딥러닝은 알파고가 사용한 방법론으로 이를 계기로 국내에서는 일반인 사이에서도 널리 알려진 이름의 기술이기도 하다.
딥러닝은 기본적으로 인간 뇌의 정보 처리 방식을 모사한 인공 신경망에서 발전한 방법이다. 인간의 뇌는 (적어도 아직까지는) 대부분의 방면에서 가장 뛰어난 정보 처리 시스템으로, 수많은 뉴런(neuron)들의 연결로 구성된 신경망(neural network)이다. 각각의 뉴런들은 정보를 보유한 전기 신호를 주고받는데, 임계치 이상의 신호가 뉴런에 입력되면, 그 뉴런이 활성화되면서 그다음 단계의 뉴런에게 신호를 전달한다. 하나의 뉴런은 다양한 방향에서 연결된 여러 뉴런에서 신호를 받고, 또 여러 뉴런으로 신호를 주게 된다. 딥 러닝은 이러한 뇌의 전달 방식과 유사하게 신경망 구조를 여러 층(layer)으로 깊이 있게(deep) 구성하여 학습을 진행하는 것이다.
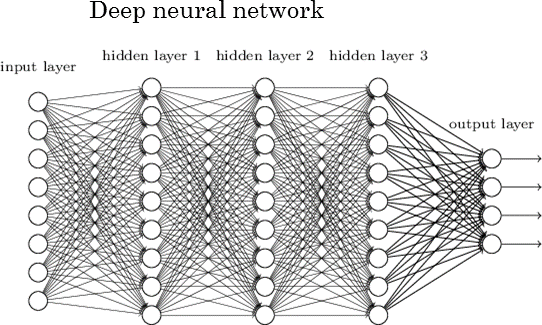
심층 인공 신경망(deep artificial neural network)의 구조[ref]
딥러닝이 세계 인공지능 연구의 흐름을 바꾸었던 것은 2012년 세계 이미지 인식 대회에서 본격적으로 시작되었다. 2010년부터 이미지넷(ImageNet)은 매년 이미지 인식 경진대회인 ILSVRC (ImageNet Large Scale Visual Recognition Competition)을 개최하여 전 세계 연구 그룹과 회사들의 이미지 인식 기술의 우열을 가린다. 그러던 2012년 대회에서 딥러닝의 대가로 유명한 토론토 대학교의 제프리 힌튼 교수팀이 딥러닝 알고리즘을 이용하여 혁신적인 성과를 보이며, 2등과 큰 격차로 우승한 것이다. 이후 지금까지 이미지넷 대회에서도 대부분의 팀이 딥러닝을 활용하여 우승을 하고 있고, 정확도는 갈수록 더 향상되고 있다. [ref 1, 2]
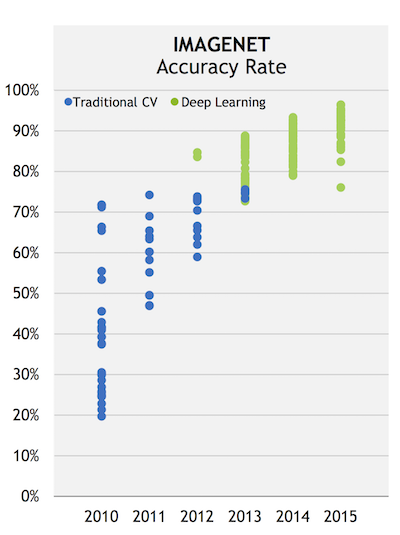
2012년 혜성처럼 등장한 딥 러닝 (출처: NVIDIA)
사실 인공 신경망과 딥러닝의 핵심 모델이라고 할 수 있는 CNN(Convolution Neural Network), RNN(Recurrent Neural Network)과 같은 모델도 사실 1980년대에 이미 활발히 연구되었던 주제이다. 그러나 당시에는 컴퓨터의 연산능력이나 계산 방법의 한계, 학습 데이터 규모의 한계 때문에 구현되지 못하던 것들이, 2000년대에 이르러서야 해결 가능해진 것이다.
빅데이터 시대를 맞아 데이터는 모든 분야에서 폭발적으로 증가하고, 컴퓨터 하드웨어와 GPU 연산 등의 발달로 연산 능력 역시 극적으로 개선되었다. 이를 통해 더욱 새로운 시도와 복잡한 계산을 할 수 있게 된 것이다. 예를 들어, 딥러닝에서도 더욱 과감하고 복잡한 연산을 시도할 수 있게 되었다.
딥러닝에서 ‘딥(deep)’이라는 말은 신경망 구조에서 은닉층(hidden layer)의 수를 늘려 깊이 쌓는다는 뜻이다. 일반적으로 은닉층을 더 깊게 쌓을수록 인공지능의 성능은 향상되지만, 이를 위해서는 더 많은 계산을 할 수 있도록 소프트웨어 및 하드웨어 리소스가 뒷받침되어야 한다. 2012년 이미지넷에서 우승한 제프리 힌튼 교수팀의 알렉스넷(AlexNet)은 고작(?) 8개 층에 불과했으나, 2014년 우승한 구글의 구글넷(인셉션)은 22층, 그리고 2015년 우승한 마이크로소프트의 레즈넷(ResNet)은 152개의 층을 쌓았다. 더 나아가 최근 연구에서는 천 개 이상의 층을 쌓기도 한다.
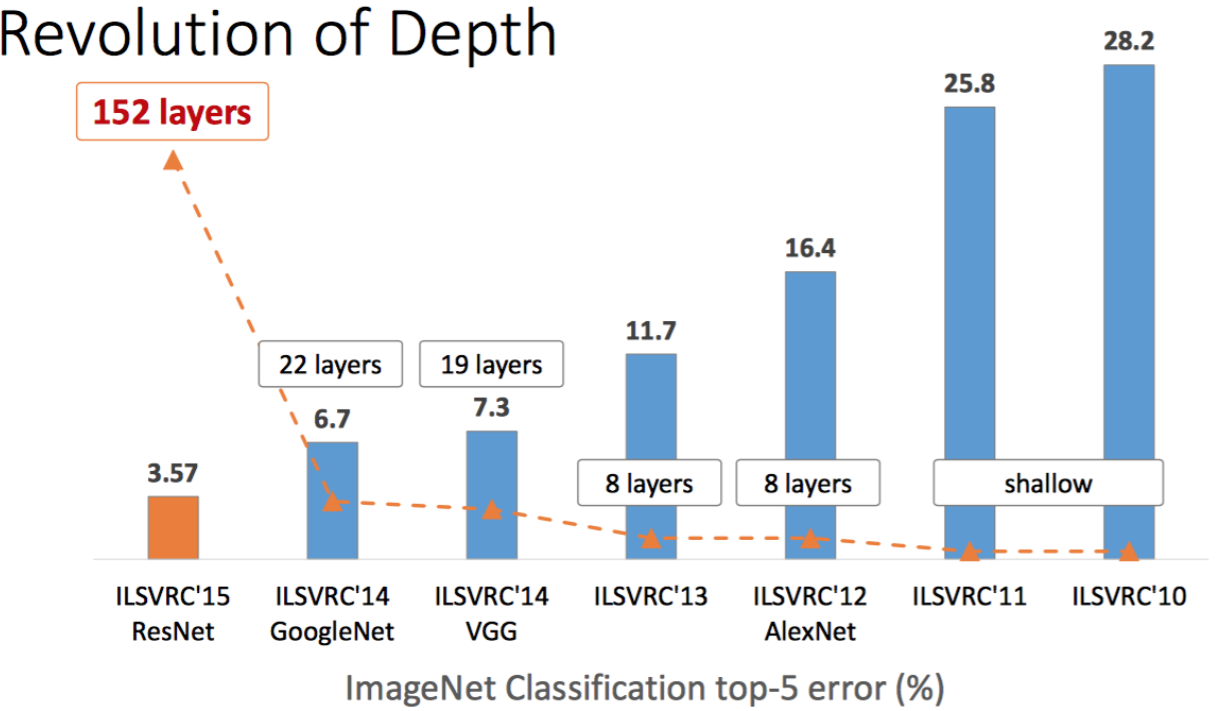
이미지넷에서 딥러닝을 이용해 우승한 팀의 정확도 및 층수
(출처: 마이크로소프트 Kaiming He의 발표 슬라이드)
이러한 배경에 따라 최근 딥러닝은 그야말로 인공지능의 부흥을 다시 한번 이끌고 있다. 여기에서 딥러닝의 기술적인 부분을 모두 설명하는 것은 어려울 것이다. 다만, 딥러닝의 가장 큰 특징 중의 하나가 양질의 학습 데이터가 많아지면 많아질수록 그 성능이 (기존의 다른 기계학습 방법론들에 비해) 비약적으로 좋아진다는 것 정도만 알아두고 넘어가자. 즉, 인터넷, 스마트폰, SNS 등의 발달로 디지털 이미지, 음성, 영상, 텍스트 등의 데이터가 많아졌다는 것은 딥러닝과 같은 방법론이 발달할 수 있는 시대적 요건이 갖춰졌다고도 볼 수 있겠다. 이에 따라 딥러닝은 이미지 인식뿐만 아니라, 음성 인식, 필기 인식, 얼굴 인식, 자연어 처리, 번역 등의 다방면에서 획기적으로 성능을 개선시키고 있다.[ref 1, 2, 3, 4, 5, 6, 7]
특히 이러한 딥러닝의 특징은 의료 분야에 접목이 용이하다는 것을 뜻한다. 앞서 여러 번 강조했듯, 의료 데이터가 질적, 양적으로 개선되며 디지털화되어 저장 및 축적되고 있기 때문이다. 이는 결국 딥러닝으로 인공지능이 학습할 수 있는 양질의 의료 데이터가 늘어난다는 의미다. 이런 상황에서 최근 보고되는 의료 인공지능의 성과 대부분이 딥러닝을 기반으로 하고 있기도 하다. [ref 1, 2, 3, 4]
이번 글에서 필자가 ‘인공지능’ 이라고 언급하는 것은 대부분 기계학습(machine learning)과 동일한 의미로 사용한다고 보면 된다. 기계학습의 여러 방법론들 중에서 특히 딥러닝을 강조해야 할 때에는 별도로 딥러닝이라는 용어를 사용하도록 하겠다.
약한 인공지능
그렇다면 인공지능은 향후 어디까지 발전할까. 우리가 의료 인공지능을 논의하기 위해서는 이 부분에 대한 명확한 정의도 필요하다. 아직까지 최고 수준의 인공지능도 인간처럼 사고하지는 못한다. 자의식이 있거나, 스스로 자신을 프로그래밍하거나, 창의적인 생각을 하지는 못한다.
심지어 지금의 인공지능은 자신이 만들어진 한 가지 목적 이외의 과업은 수행할 수 없다. 예를 들어, 퀴즈를 풀도록 고안된 왓슨에게 바둑을 두게 하거나, 바둑을 두도록 만들어진 알파고에게 자동차를 운전시킬 수는 없다. 하지만 미래에도 인공지능이 이 정도 수준에 머무를까? 앞으로 기술이 더욱 발전한다면 컴퓨터가 인간만큼, 혹은 인간보다 더 똑똑해질 수도 있을까?
이러한 측면에서 인공지능은 일반적으로 아래와 같이 크게 세 가지 종류로 구분한다.
- 약한 인공지능 (Artificial Narrow Intelligence)
- 강한 인공지능 (Artificial General Intelligence)
- 초 인공지능 (Artificial Super Intelligence)
첫 번째로 약한 인공지능 (Artificial Narrow Intelligence)이다. (영어로는 weak artificial intelligence로 쓰기도 한다.) 약한 인공지능은 한 가지 종류의 문제를 풀도록 고안된 인공지능이다. 자의식이 없으며, 스스로 무엇을 할지 판단하지 못한다. 하지만 주어진 특정 종류의 문제를 인간만큼 혹은 인간보다 더 잘 해결할 수 있다. 이런 약한 인공지능은 현실에서 이미 구현되어 있으며, 주변에서 우리도 알게 모르게 널리 사용하고 있다.
예를 들어, 체스, 바둑, 퀴즈, 스팸 메일 필터링, 아마존 닷컴에서의 상품 추천, 테슬라의 자율 주행차, 아이폰의 시리(Siri), 페이스북에 올린 사진의 얼굴 인식 등이 모두 약한 인공지능의 사례들이다. 하지만 앞서 이야기했듯이, 약한 인공지능은 자신이 풀도록 고안된 특정 정류의 문제 외에는 해결하지 못한다.
페이스북에 사진을 올리면 얼굴의 위치를 인식하고,
안면을 인식하여 누구인지 자동으로 태깅해주기도 한다.
이러한 종류의 인공지능은 이제는 너무 일반적으로 사용되고 있기 때문에, 독자들은 (특히 젊은 세대들은) “이런 것도 인공지능이라고 해야 하나?” 하고 의아하게 생각할지도 모르겠다. 하지만 지금의 1970년대로 돌아가 거리에서 아무나 붙잡고 스마트폰을 꺼내어 시리를 보여주면 누구나 SF 영화에 나오는 인공지능이라고 생각할 것이다. 테슬라가 상용화하고 있는 자율주행차는 1980년대 초 ‘전격 제트 작전’에서나 나오던 상상의 산물이었고, 1950년대 후반의 몇몇 전문가들은 “만약 성공적인 체스 기계가 만들어진다면, 이는 인간의 지적 활동의 핵심이 간파된 것으로 보아도 좋을 것이다” 라고 까지 생각했다.
혹시 약한 인공지능이 너무 시시하게 보인다면, 인공지능의 아버지 존 매카시(John McCarthy)가 “일단 인공지능이 구현되고 나면, 아무도 그것을 더 이상 인공지능이라고 부르지 않는다(As soon as it works, no-one calls it AI anymore.)” 라고 언급했던 것을 떠올려보자.
강한 인공지능
하지만 사람들은 흔히 인공지능이라고 하면, 조금 더 발전된 형태의 인공지능을 떠올리게 마련이다. 아이언맨의 ‘자비스’, 그녀(Her)의 ‘사만다’, 인터스텔라의 ‘타스(Tars)’ 와 같이 SF 영화에서 자주 등장하는 이러한 인공지능은 스스로 생각할 수 있고, 자의식이 있다. 명령받지 않은 일도 스스로 필요하다고 생각해서 수행하거나, 반대로 명령을 거부할 수도 있다. 인간과 같이 감정을 느끼고, 농담을 주고받을 수 있으며, 한 번도 배우지 않은 일을 스스로 학습할 수도 있다.

이것이 바로 강한 인공지능(Artificial General Intelligence)이다. 영어로는 strong artificial intelligence라고 하기도 하며, 일반 인공지능 혹은 범용 인공지능으로 부르기도 한다. 강한 인공지능은 약한 인공지능과 달리 스스로 사고하고, 종류를 가리지 않고 다양한 문제를 인간 정도의 수준으로 해결할 수 있다. 미래에 대한 계획을 세울 수도, 추상적인 개념에 대해서 학습할 수도, 자신의 존재에 대한 고민을 할 수도 있다.
강한 인공지능은 SF 영화에서는 단골로 등장하지만, 현실에서는 아직 구현되지 않았다. 강한 인공지능을 진지하게 고민하는 연구자들과 학회도 있지만, 아직까지 가시적인 성과는 없다고 해야 할 것이다.
그렇다면 과연 강한 인공지능은 구현될 수 있을까? 이에 대한 정답은 아무도 가지고 있지 않을지도 모른다. 하지만 흥미롭게도 많은 인공지능 전문가들은 강한 인공지능의 구현이 언젠가는 가능하다고 믿는다. 2017년 1월 미국 캘리포니아에서 열린 한 학회에서, 구글 딥마인드의 데미스 하사비스, 테슬라의 엘론 머스크, 미래학자 레이 커즈와일, 옥스퍼드대학 닉 보스트롬, 버클리 대학의 스투어트 러셀 등의 전문가들이 모여서 강한 인공지능과 (더 나아가 초지능의 도래 가능성에 대해) 토론한 적이 있다. 여기에서 ‘초인공지능이란 영역은 도달 가능한 것인가?’, ‘초지능을 가진 개체의 출현이 가능할 것이라고 생각하는가?’ 라는 두 가지 질문에 대해서 아홉 명의 모든 패널이 ‘그렇다’ 라고 답했다.
하지만 강한 인공지능의 구현 시기에 대해서는 예측이 갈리는 편이다. ‘특이점이 온다’로 유명한 미래학자 레이 커즈와일은 기술의 기하급수적인 발전 추이를 토대로 강한 인공지능의 도래 시점을 2045년 경으로 예측하기도 했다. 기하급수적으로 발전하는 컴퓨터의 연산 능력이 인류 전체의 두뇌의 연산 능력의 총합을 넘어서는 시점이 그 정도 시기로 보고 있기 때문이다.
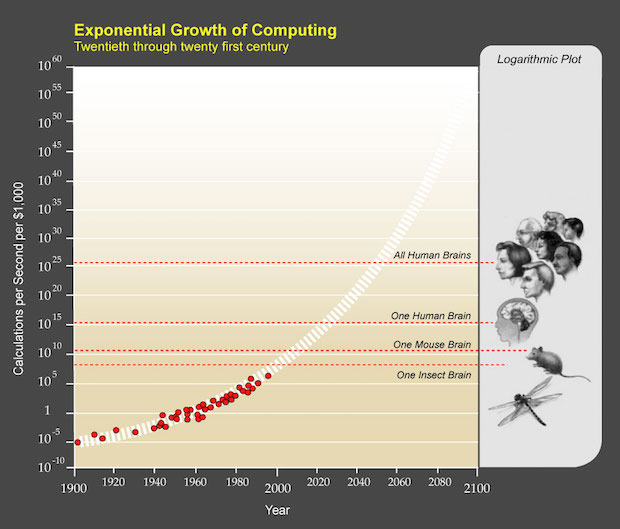
특이점주의자들은 2045년 경에 강한 인공지능이 구현될 것으로 본다
강한 인공지능과 초지능에 대해서 진지하게 고찰한, 옥스포드 대학 인류미래연구소장 닉 보스트롬의 ‘슈퍼인텔리전스: 경로, 위험, 전략‘에는 강한 인공지능의 도래 시기에 대하여 학회 참석자나 관련 논문 저자 등 전문가를 설문 조사한 결과가 언급되어 있다. 설문 응답자 중 강한 인공지능이 일찍 도래하리라고 보는 상위 10%의 경우는 대략 2020년에서 203년 사이로 보기도 한다. 늦어도 2040년에서 2050년 전후까지는 가능하다고 보는 사람들은 전체의 50% 정도이다. 그리고 아무리 늦어도 금세기 안으로 강한 인공지능이 구현되리라고 생각하는 전문가들은 전체의 90%에 달한다.
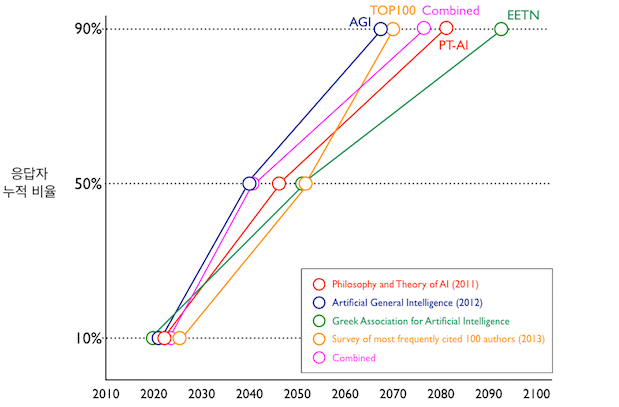
언제쯤 기계가 인간 수준의 지능을 획득할 것인가? (출처: 슈퍼인텔리전스)
초 인공지능
그렇다면 이렇게 강한 인공지능은 혹시 인류에게 위협적이지 않을까? 많은 전문가들은 강한 인공지능의 위험성에 대해서 벌써부터 경고하고 있다. 스티븐 호킹 박사는 ‘강한 인공지능의 발전은 인류의 멸망을 의미할 수 있다’ 고 BBC 인터뷰에서 밝혔으며, 엘론 머스크는 인공지능의 발전이 ‘악마를 소환하는 것(summoning the demon)’과 같을 수 있다고 MIT의 심포지움에서 언급한 바 있다. 빌 게이츠도, 스티브 워즈니악도 마찬가지였다.
이처럼 강한 인공지능이 인류에게 위협적일 것이며, 인류를 멸망시키거나 인공지능의 노예로 전락할 수 있다고 보는 이유는 일단 강한 인공지능이 구현되고 나면, ‘스스로 발전할 수 있는’ 인공지능은 인간 수준에서 그대로 멈춰있지는 않을 것이기 때문이다. ‘순환적 자기 개선(recursive self-improvement)’을 할 수 있는 강한 인공지능은 스스로가 자신에게 필요한 더 나은 프로그램을 반복적으로 프로그래밍하는 것을 통해 계속해서, 아마도 인간이 상상하기 어려울 정도의 빠른 속도로 더욱 발전을 거듭할 것이다.
이러한 지능 대폭발(intelligence explosion)을 거쳐서 맞이하게 되는 것이 초 인공지능(Artificial Super Intelligence)이다. ‘인공’을 빼고 그냥 초지능(superintelligence)라고 부르기도 한다. (닉 보스트롬에 따르면, 초지능에 이르기 위한 유력한 경로 중의 하나가 인공지능이지만, 전뇌 에뮬레이션, 뇌-컴퓨터 인터페이스 등의 다른 경로도 가능하다고 말한다.)
이러한 초지능은 아인슈타인과 같이 가장 똑똑한 인간보다도 비교할 수 없을 정도로 훨씬 더 똑똑한 존재다. 이렇게 되면 인간의 능력으로는 초지능이 얼마나 똑똑하고 무엇을 할 수 있는지를 짐작조차 하기 어려울 것이다. 개미와 인간 사이의 지능 차이보다, 인간과 초지능적 존재 사이의 지능 차이가 더 커진다는 것을 상상해보라. 영국의 SF 소설가이자 미래학자 아서 C. 클라크는 ‘충분히 발달한 과학은 마법과 구분할 수 없다’ 고 언급했다. 아마도 초인공지능은 인간에게 이해 불가한 마법과 같은 혹은 신적인 존재로 느껴지게 될 것이다.
 생물학적 지능의 단계가 이러하다고 가정하였을 경우 (출처),
생물학적 지능의 단계가 이러하다고 가정하였을 경우 (출처),
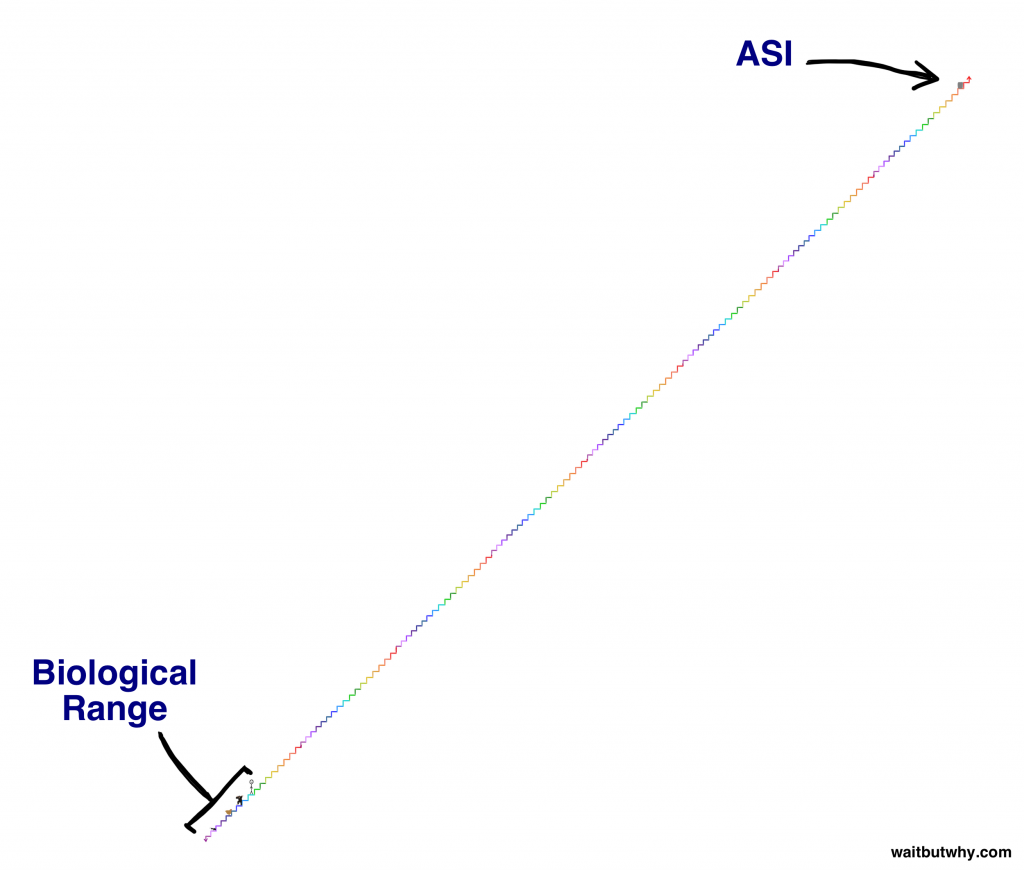 이 범위를 뛰어 넘어 발전을 지속하는 초 인공지능(ASI)을
이 범위를 뛰어 넘어 발전을 지속하는 초 인공지능(ASI)을
인류의 지능으로는 도저히 이해하기 어렵고 컨트롤도 불가능할 것이다. (출처)
이렇게 되면 이 초인공지능이 어떠한 목적을 가지고 있는지, 인간이라는 존재를 어떻게 인식할 것인지가 매우 중요해진다. 인간이 만든 인공지능에서 발전했지만, 인간보다 뛰어난 기계가 여전히 인간의 명령을 따를 이유는 없을 것이다. 만약 이러한 상황이 된다면, 스티븐 호킹이나 엘론 머스크가 경고한 바대로 인류의 생존 자체를 걱정해야 할지도 모른다.
많은 전문가들은 이러한 초인공지능이 도래할 가능성에 대해서 우려하며, 미리 준비가 필요하다고 강조한다. 약한 인공지능에서 강한 인공지능까지 발전하는 것은 최소한 수십 년에 걸친 상당한 시간이 걸릴 것이다. 하지만 일단 강한 인공지능이 구현된 이후에, 이것이 인간의 컨트롤을 벗어나 지구 상의 모든 자원을 사용하여 스스로 진화한 결과 초인공지능으로 거듭나는 데는 매우 짧은 시간밖에 걸리지 않을 수 있다는 것이다. 예를 들어, 며칠, 몇 시간 혹은 몇 분만에 말이다. 이렇게 불과 순식간에 지능 대폭발을 통해서 역사상 처음으로 자신보다 더 똑똑한 존재를 마주하게 된 인류는 그야말로 대혼란에 빠질 수도 있을 것이다.
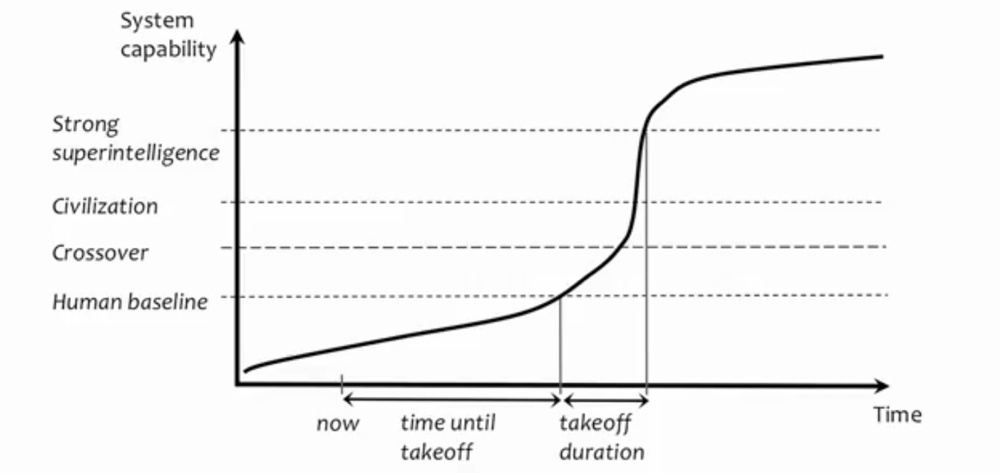
일단 인간 수준(human baseline)의 강한 인공지능이 구현되면,
이후 초지능(superintelligence)로 도약(take off)하기까지는
극히 짧은 시간이 걸릴 수 있다 (출처: 슈퍼인텔리전스)
어찌 보면 흔해빠진 SF 영화의 시나리오처럼 보이는 이러한 강한 인공지능과 초 인공지능에 대해서도 매우 진지하게 접근하는 학자들이 있다. 이러한 가능성을 사전에 탐구하고 인류의 멸망 시나리오를 막기 위함이다. 다만 의료 인공지능에 대해서 논하는 필자의 글에서는 논의를 ‘약한 인공지능’의 범주로 제한하도록 하겠다. 강한 인공지능이나 초인공지능을 가정한다면, 앞으로 하게 될 의료 인공지능에 대한 모든 논의는 무의미해질 것이기 때문이다.
지금껏 이 세 가지 인공지능에 대해서 장황하게 설명한 것은 이러한 논의가 존재한다는 것을 알아둘 필요가 있다는 점, 그리고 우리가 향후 논의할 범위를 정의하기 위함이었다. 이제 필자가 ‘인공지능’ 이라고 한다면 주로 ‘기계학습’이라는 방법론에 의해서 구현된 ‘약한 인공지능’ 이라는 점을 알아두면 좋겠다.
혹시 강한 인공지능 및 초인공지능에 대해서 더 공부해보고 싶은 독자들이 있다면 레이 커즈와일의 ‘특이점이 온다‘, 닉 보스트롬의 ‘슈퍼인텔리전스: 경로, 위험, 전략‘, 제임스 배럿의 ‘파이널 인벤션‘ 등의 책을 참고할 것을 권한다. 이렇게 기술의 기하급수적 발전에 따른 인류의 미래를 급진적으로 논의하는 책의 평가는 상당히 엇갈리는 편이다. 이 책의 저자들은 현재 인공지능을 실제로 연구하는 주류 학계의 연구자가 아니라는 점에서 비판받기도 한다. 하지만 이러한 미래의 가능성에 대해 어떠한 주장과, 그러한 주장에 대한 근거로는 무엇이 있는지를 비판적으로 살펴본다면 인공지능에 대해서도 유익한 공부가 될 것이다.
인공지능을 어떻게 바라볼 것인가
자. 이제 ‘의사와 의료 인공지능이 경쟁하면 누가 승리할 것인가’ 라는 질문으로 다시 되돌아오자. 이 질문은 과연 올바른 질문일까?
흔히 인공지능의 미래를 논할 때 이처럼 인간과 인공지능의 대결 구도를 전제로 하는 경우가 많다. 2016년 이세돌과 알파고도 대결을 했고, 2011년 미국의 퀴즈쇼 제퍼디! 에서는 인간 챔피언 켄 제닝스와 브레드 레터가 IBM 왓슨과 대결했다. 더 이전에는 체스 세계 챔피언 가리 카스파로프와 IBM 딥블루가 대결했다.
이러한 대결 구도가 만들어지게 된 계기도 충분히 이해할 수 있다. 인공지능 기술의 발전을 가장 명확하게 보여줄 수 있는 방법이 바로 인간 최고수와의 대결에서 승리하는 것이기 때문이다. 또한 이는 인공지능을 개발한 기업 입장에서 아주 훌륭한 마케팅 전략이기도 하다. (인간과의 대결에서 승리한 IBM과 구글은 금전적으로 환산하기 어려운 큰 마케팅 효과를 얻었을 것이다)

사실 필자도 앞서 기자와 변호사 등의 ‘기술적 실직’을 언급함으로써, 그러한 대결 구도의 뉘앙스를 풍겼는지도 모르겠다. 하지만 인공지능이 인류의 미래에 큰 영향을 미칠 것이라는 점을 누구도 부인할 수 없는 상황이라면, 이제 우리가 던져야 할 올바른 질문은 ‘어떻게 하면 힘을 합쳐서 더 나은 결과를 얻을 것인가’ 하는 것이다. 즉, 한쪽은 이기고 한쪽은 패배하는 대결 구도가 아니라, 협력 구도를 통한 시너지 창출을 전제로 해야 한다.
인공지능이라는 미래는 무작정 막을 수도, 막아지지도 않을 것이다. 이제는 어떻게 하면 인간의 ‘마지막 발명’이 될 수도 있을 인공지능을 현명하게 활용할 것인지에 대해서 고민해야 한다. 인공지능과 인간이 함께 달려서 더 나은 미래, 더 나은 사회를 만들 수 있도록 고민해야 한다는 것이다.
의료 분야로 국한하자면, 인공지능과 의사가 힘을 합쳐 환자에게 더 나은 의료를 제공할 수 있는 방안을 고민하는 것이 무엇보다 중요할 것이다. 인공지능이 도입된다고 해서 의료가 가지는 본래의 목적 자체가 바뀌지는 않는다. 더 높은 질의 의료를 제공하고, 부작용은 낮추며, 가능하다면 의료 비용도 낮출 수 있으면 좋을 것이다. 그리고 그러한 과정에서 의사의 역할에 어떠한 변화가 있을지를 예상해보는 것이 올바른 논의의 방향일 것이다.
 인간과 인공지능의 강점은 서로 다르다 (출처: IBM)
인간과 인공지능의 강점은 서로 다르다 (출처: IBM)
강한 인공지능이나 초 인공지능을 전제로 한다면 문제가 완전히 달라지기는 하지만, 약한 인공지능을 전제로 한다면 인공지능과 인간이 힘을 합치고 시너지를 낼 수 있는 충분한 가능성이 있다. 그 이유는 인간이 가지는 강점과 (약한) 인공지능이 가지는 강점이 서로 다르기 때문이다. 현재 전 세계적으로 인공지능의 사업화를 가장 활발하게 진행하고 있는 기업 중의 하나인 IBM의 설명에 따르면 인간과 인공지능이 가지는 강점은 다음과 같이 차별화된다.
- 인간이 더 나은 부분:
- 상식이 있다.
- 딜레마의 해결이 가능하다.
- 윤리를 갖추고 있다.
- 공감 능력이 있다.
- 상상력이 있다.
- 꿈을 꿀 수 있다.
- 추상화 능력이 있다.
- 일반화 능력이 있다.
- 인공지능이 더 나은 부분:
- 자연어를 (더 효율적으로) 처리할 수 있다.
- 패턴을 인식할 수 있다.
- 지식을 체계적으로 분류할 수 있다.
- 기계 학습을 통해서 배울 수 있다.
- 편견이 없다.
- 기억력(저장공간)이 무한대다.
앞으로 더 자세히 논의하겠지만, 의료 분야에서도 인간 의사와 인공지능 의사가 어떻게 힘을 합쳐야 할지도 이러한 ‘서로 다른’ 강점에서 힌트를 얻을 수 있다. 현재 의료 체계 하에서 의사의 역할이나, 수련의가 교육받고 훈련받는 방식, 중점적으로 계발시키려는 역량을 떠올려보자. 위의 목록에 따르면 현재 의사는 인간으로서의 강점보다는 패턴 인식, 지식 분류, 암기 등 오히려 인공지능이 잘할 수 있는 역량을 주로 강화하고 있다. 이러한 측면에서도 인간 의사의 역할, 요구되는 역량 및 의과대학 교육 방식에 큰 변화가 불가피해보인다.
이제부터는 의료 분야에서 인공지능이 현재 어디까지 발전해있으며, 구체적으로 어떻게 사용되고 있는지 다양한 사례를 들어서 설명할 것이다. 중요한 것은, 이러한 실제 사례들을 살펴보면서도 인공지능과 인간 의사의 강점을 결합하고 조화시켜야 한다는 전제를 잊지 않는 것이다. 이러한 전제 하에서 우리는 인공지능 패배주의나 인공지능 만능주의에서 벗어나 미래지향적이면서도 보다 생산적인 이야기를 할 수 있다.
물론 의료 인공지능 자체의 성능을 높이는 것도 매우 중요할 것이다. 하지만 같은 인공지능이라 하더라도 실제 의료 현장에서 어떠한 방식으로 진료, 진단, 치료 프로세스에 녹아들고, 어떠한 기준과 원칙 하에 활용되는지에 따라 환자에 미치는 영향과 의학적인 효용성은 크게 달라질 수 있다. 하지만 아직 이러한 부분에 대한 고민은 전 세계적으로도 여전히 미약한 상황이다.
(계속)
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.