이번에는 데이터를 해석하기 위한 또 다른 방법에 대해서 알아보자. 데이터를 인간이 직접 해석하는 것이 한 가지 방식이었다면, 남은 한 가지 방식은 바로 인공지능의 힘을 빌리는 것이다.
최근 국내외를 막론하고 신기술 분야를 통틀어 가장 이슈가 되고 있는 주제를 하나만 고르라면 아마도 인공지능이 될 것이다. 인공지능은 몇 년 전만 하더라도 한국에서는 크게 관심을 받지 못했지만, 2016년 3월 알파고 사태 이후로 돌연 국가적인 관심사로 떠올랐다. 정부 부처별로 인공지능 관련 컨트롤 타워를 만들겠다고 나서고 있으며, 각종 도서, 학회, 강의에는 소위 ‘제 4차 산업 혁명’ 이야기가 가득하다.
(참고로, 이 ‘4차 산업 혁명’이라는 용어는 ‘스마트 헬스케어’, ‘유 헬스케어’처럼 한국에서만 주로 사용되는 용어로, 필자는 되도록이면 사용하지 않는다)
이러한 인공지능 열풍이 이제는 조금 지나친 것이 아닌가 하는 생각이 들지만, 장기적으로 인공지능이 인류의 미래에 큰 영향을 미치리라는 전제 자체를 부정하는 사람은 별로 없을 것이다. 그리고 그런 인공지능의 영향을 가장 크게, 우선적으로 받고 있는 분야 중의 하나가 바로 의료라고 할 수 있다.
“디지털 의료는 어떻게 구현되는가” 시리즈 이전 글 보기
- 변혁의 쓰나미 앞에서
- 누가 디지털 의료를 이끄는가
- 데이터, 데이터, 데이터!
- 4P 의료의 실현
- 스마트폰
- 이제 스마트폰이 당신을 진찰한다
- 웨어러블 디바이스
- 개인 유전 정보 분석의 모든 것!
- 환자 유래의 의료 데이터 (PGHD)
- 헬스케어 데이터의 통합
- 헬스케어 데이터 플랫폼: 애플 & 발리딕
- 빅 데이터 의료
- 원격 환자 모니터링
- 원격진료
- 인공지능
디지털 의료의 화룡점정
지금까지 우리는 디지털 의료가 어떻게 구현되는지를 알아보기 위해 다양한 주제들을 살펴보았다. 그 중심에는 데이터가 있었다. 웨어러블, 사물인터넷 센서, 스마트폰, 유전 정보 기술의 발전은 한 사람의 건강 상태를 파악할 수 있는 데이터의 양을 폭발적으로 증가시키게 된다. 여기에 통신, 클라우드 컴퓨팅 기술의 발전은 이러한 데이터를 저장, 수집, 통합하여, 마침내 이 데이터를 우리가 활용할 수 있도록 준비해놓았다.
이러한 의료 데이터의 질적, 양적인 범람과 이를 어떻게 해석하고 활용할 것인지에 대한 고민은 필연적으로 인공지능이라는 해결책으로 귀결된다.
우리는 의료의 궁극적인 이상향으로 4P의료를 강조했다. 그중 예방 의료(preventive medicine) 및 예측 의료(predictive medicine)를 근본적으로 구현하기 위해서는 개별 환자의 건강과 질병 관련 데이터를 지속적으로 모니터링하는 것이 필요하다. 그 사람의 데이터를 지속적으로 모니터링하고 있어야만 발병이나 상태 악화를 예측하고, 이를 통해 예방도 할 수 있을 것이기 때문이다.
그런데 대부분의 건강 및 의료 데이터는 연속적이다. 예를 들어, 체온, 심박, 심전도, 혈압, 혈당, 수면, 호흡 등의 데이터는 우리가 목숨을 유지하는 한 지속적으로, 끊임없이, 지금 이 순간에도 생산되고 있다. 따라서 이 연속적인 데이터의 모니터링은 24시간, 365일 연속으로 진행되고, 그렇게 얻은 데이터를 실시간으로 분석하여 환자의 상태를 파악하고, 예측하는 것이 이상적이다.
하지만 이는 인간이 하기에는 역부족이다. 한두 명의 환자에 대해서라면 모르겠지만, 모든 환자에 대해서 측정된 연속적인 데이터를 모니터링 및 실시간 해석 및 예측하기 위해서는 결국 인공지능이 필요하다.
더 나아가, 분석해야 할 데이터의 복잡성 때문에도 인공지능의 필요성은 커진다. 일반적으로 질병이나 건강 상태를 분석하고 예측, 예방하기 위해서는 한 가지가 아닌, 두 가지 이상의 데이터를 복합적이고 총체적으로 분석하는 것이 바람직하다.
예를 들어, 당뇨병 환자의 저혈당을 예측하기 위해서는 단순히 혈당 수치의 연속적인 변화뿐만 아니라, 당화혈색소, 유전적 요인, 최근 식습관, 복약, 인슐린 투여, 운동량, 스트레스 등의 데이터를 종합적으로 고려할 필요가 있다. 뿐만 아니라 부정맥, 천식 발작, 뇌전증(간질) 발작, 우울증을 예측하고 예방하기 위해서도 마찬가지로 다양한 데이터의 총체적 분석이 도움이 될 수 있다.
이렇게 연속적인 데이터를 포함한 다양한 데이터를 실시간으로 모니터링하면서, 총체적으로 분석하기 위해서는 결국 인공지능의 역할이 필수적이다. 지금도 다양한 의료 분야에 인공지능의 연구 결과가 쏟아지고 있지만, 향후 의료 현장에서 인공지능의 역할은 더욱 커질 것이다. 데이터의 측정-통합-분석을 통해서 완성되는 디지털 의료에서 인공지능은 화룡점정의 역할을 한다고도 할 수 있겠다.
 인간의 힘만으로 모든 환자의 연속적인 데이터를
인간의 힘만으로 모든 환자의 연속적인 데이터를
24시간 실시간 모니터링 및 분석하는 것은 불가능한 일이다.
인공지능의 발전
1950년대에 수학, 공학, 철학 등 다양한 영역의 학자들에 의해서 인공적인 두뇌의 가능성이 논의되면서, 인공지능은 학문의 한 분야로 발돋움하게 된다. 이후 인공지능의 연구와 사업은 황금기(1956-1974), 첫 번째 암흑기(1974-1980), 활황기(1980-1987), 두 번째 암흑기(1987-1993) 등의 부침을 겪으면서 발전해왔다. [ref 1, 2, 3]
최근에 이르러 또다시 맞이하게 된 인공지능의 활황기는 인공지능을 학습시킬 수 있는 방대한 데이터의 축적, GPU를 비롯한 하드웨어 기술의 발전을 통한 연산 능력의 향상, 그리고 딥러닝을 위시한 인공지능 알고리즘의 발전 등의 요소가 어우러진 결과물이다.
근래에 언론 등에서 ‘인공지능’이라고 통칭되는 이 개념은 상당히 추상적으로 사용될 때도 있고, 어떤 경우는 딥러닝 등의 보다 구체적인 기술을 지칭하는 경우도 있다.
사실 인공지능을 구현하기 위한 학문적인 접근 방법은 매우 다양하다. 예를 들어, 한 때 가장 주목받았던 접근법 중의 하나는 전문가 시스템(expert system) 방식이었다. 이는 인간의 논리, 지식, 규칙을 컴퓨터에 집어넣으려고 시도했다. 만약 인간의 모든 지식, 논리 등을 컴퓨터에 일일이 가르칠 수 있으면 인간과 같은 사고를 모사할 수 있을 것이라는 가정에서였다. 이러한 시스템은 항공, 철도, 자동차 등 특정 전문 분야의 지식을 학습시켜서 성공적으로 활용되기도 했다 [ref 1, 2].
그런가하면, 인간의 뇌 자체를 역설계(reverse engineering)하여 두뇌의 기능을 컴퓨터로 시뮬레이션하려는 시도들도 있다. 2013년 유럽연합에서는 이러한 목적으로 ‘휴먼 브레인 프로젝트(Human Brain Project)‘를 출범하며, 10억 유로가 넘는 연구비를 지원하기도 했다. 기술적으로는 아직 많은 난관이 있지만, 언젠가는 인간이 뇌를 컴퓨터로 완벽하게 시뮬레이션할 수 있을지도 모른다. 만약 그렇게 될 수 있다고 가정한다면, 이는 곧 뇌가 불사의 존재가 된다는 뜻일지, 혹은 인간의 정신이 육체를 떠나 존재할 수도 있다는 것일지 등에 대한 형이상학적인 의문을 불러일으키기도 한다.
하지만 현재 인공지능에 대한 접근 방법으로 가장 많이 사용되고 있는 것은 역시 머신 러닝(machine learning), 즉 기계 학습이다. 기계 학습은 데이터를 기반으로 수학적인 방법을 통해서 컴퓨터를 인간처럼 학습시켜 스스로 규칙을 형성할 수 있도록 한다. 현재 인공지능의 대표적인 사례들로 알려진 검색 엔진, 스팸 필터, 자율주행차, 음성 인식, 얼굴 인식, 알파고 등은 모두 이런 기계 학습을 기반으로 한다.
이러한 기계 학습이라는 분야에는 여러 가지 세부적인 방법론이 있다. 과거에는 은닉 마르코프 모델(Hidden Markov Model), 인공 신경망(Artificial Neural Network), 서포트 벡터 머신(Support Vector Machine) 등의 방법론이 있었다. 이런 방법론은 시대에 따라서 유행을 타기도 하고, 기술적으로 구현이 가능한지에 따라 부침을 겪기도 하면서 지난 수십 년에 걸쳐 발전해왔다.
![]() 인공지능 – 기계학습 – 딥러닝의 관계 (출처: NVIDIA 블로그)
인공지능 – 기계학습 – 딥러닝의 관계 (출처: NVIDIA 블로그)
딥러닝의 발전
그러던 지난 2010년 전후로는 인공 신경망에서 발전한 딥러닝(deep learning)이라는 방법론이 급격하게 발전하면서, 적어도 지금은 기계 학습의 여러 방법 중에서 왕좌를 차지하고 있다. 딥러닝은 알파고가 사용한 방법론으로 이를 계기로 국내에서는 비전문가들 사이에서도 널리 알려진 기술이기도 하다.
딥러닝은 기본적으로 인간 뇌의 정보 처리 방식을 모사한 인공 신경망에서 발전한 방법이다. 인간 뇌는 가장 뛰어난 정보 처리 시스템으로, 수많은 뉴런(neuron)들의 연결로 구성된 신경망(neural network)이다. 각각의 뉴런들은 정보를 보유한 전기 신호를 주고받는데, 임계치 이상의 신호가 뉴런에 입력되면, 그 뉴런이 활성화되면서 그다음 단계의 뉴런에게 신호를 전달한다. 하나의 뉴런은 다양한 방향에서 연결된 여러 뉴런에서 신호를 받고, 또 여러 뉴런으로 신호를 주게 된다. 딥 러닝은 이러한 뇌의 전달 방식과 유사하게 신경망 구조를 여러 층(layer)으로 깊이 있게(deep) 구성하여 학습을 진행하는 것이다.
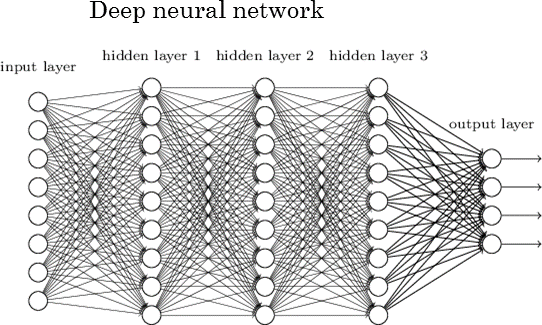
심층 인공 신경망(deep artificial neural network)의 구조[ref]
딥러닝이 세계 인공지능 연구의 흐름을 바꾸었던 것은 2012년 세계 이미지 인식 대회의 우승에서 본격적으로 시작되었다. 2010년부터 이미지넷(ImageNet)은 매년 이미지 인식 경진대회인 ILSVRC (ImageNet Large Scale Visual Recognition Competition)을 개최하여 전 세계 연구 그룹과 회사들의 이미지 인식 기술의 우열을 가린다. 그러던 2012년 대회에서 딥러닝의 대가로 유명한 토론토 대학교의 제프리 힌튼 교수팀이 딥러닝 알고리즘을 이용하여 혁신적인 성과를 보이며, 2등과 큰 격차로 우승한 것이다.
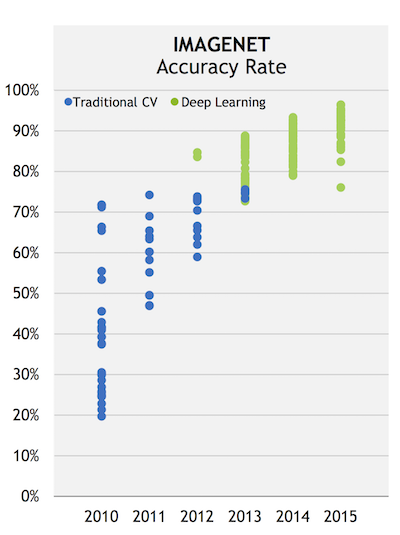
하지만 인공 신경망과 딥러닝의 주요한 학습 방법 중의 하나인 오차 역전파 (backpropagation)나, 이미지를 학습하는 핵심 모델인CNN(Convolution Neural Network) 등은 이미 1980년대에 제시되었던 주제이다. 그러나 당시에는 컴퓨터의 연산능력이나 계산 방법의 한계, 학습 데이터 규모의 한계 때문에 구현되지 못하던 것들이, 2000년대에 이르러서야 해결 가능해졌다 [ref 1, 2, 3]. 연구가 거듭되며 계산 방법에 발전이 있었을 뿐만 아니라, 빅데이터 시대를 맞아 데이터는 모든 분야에서 폭발적으로 증가하고, 컴퓨터 하드웨어와 GPU 연산 등의 발달로 연산 속도 역시 극적으로 개선된 것이다. 이에 따라 최근 딥러닝은 그야말로 인공지능의 부흥을 다시 한번 이끌고 있다.
여기에서 딥러닝의 기술적인 부분을 모두 설명하는 것은 어려울 것이다. 다만, 딥러닝의 가장 큰 특징 중의 하나가 양질의 학습 데이터가 많아지면 많아질수록 그 성능이 (기존의 다른 기계 학습 방법론들에 비해) 비약적으로 좋아진다는 것 정도만 알아두고 넘어가자. 즉, 인터넷, 스마트폰, SNS 등의 발달로 디지털 이미지, 음성, 영상, 텍스트 등의 데이터가 많아졌다는 것은 딥러닝과 같은 방법론이 발달할 수 있는 시대적 요건이 갖춰졌다고도 볼 수 있겠다.
특히 이러한 딥러닝의 특징은 의료 분야에 접목이 용이하다는 것을 뜻한다. 앞서 여러 번 강조했듯, 의료 데이터가 질적, 양적으로 개선되며 디지털화되어 저장 및 축적되고 있기 때문이다. 이는 결국 딥러닝으로 인공지능이 학습할 수 있는 양질의 의료 데이터가 늘어난다는 의미다. 이런 상황에서 최근 보고되는 의료 인공지능의 성과 대부분이 딥러닝을 기반으로 하고 있기도 하다. [ref 1, 2, 3, 4]
사실 인공지능의 의료 적용 전반에 대해서 논하려면 상당히 폭넓고도 복잡한 이슈들을 거론해야 한다. 인공지능의 기술적 측면과 구체적인 적용 사례뿐만 아니라, ‘인공지능은 의사를 대체하는가’, ‘의료 인공지능의 책임은 누가 지는가’, ‘의료 인공지능의 정확성을 어떻게 검증할 것인가’ 등의 흥미로운 이슈가 그러하다.
이러한 이슈는 다음 장에서 다시 자세히 다루기로 하고, 이번에는 의료 데이터의 분석과 해석을 통한 4P 의료의 구현이라는 측면에서 인공지능을 이야기해보려 한다.
스마트폰으로 부정맥 진단
먼저 간단하고도 간편한 형태의 의료 인공지능 사례부터 살펴보도록 하자. 인공지능이라고 해서 거창하고 활용이 어려울 것이라는 선입견은 버리는 것이 좋다. 이미 스마트폰과 애플워치를 통해서 측정한 심전도 데이터를 기반으로 부정맥을 진단하는 기계학습 알고리즘이 사용되고 있기 때문이다.
앞서 스마트폰과 애플워치를 통해서 심전도 데이터를 측정할 수 있음은 언급한 바 있다. 심전도, 즉 심장의 전기적 활동을 측정하기 위해서는 심장을 중심으로 최소한 두 개의 전극을 신체에 접촉할 필요가 있다. 스마트폰 케이스 형태의 기기인 얼라이브코(AliveCor)에는 뒷면에 두 개의 전극이 있어서 양쪽 손으로 잡고서 심전도를 측정할 수 있다.

스마트폰 케이스 형태의 심전도 측정기, 얼라이브코
이 기기는 이미 FDA에서 인허가받은 2등급 의료기기다. 2012년 아이폰에 대해서 FDA 승인을, 2013년 가을에는 안드로이드 폰에 대해서 FDA 승인을 받았다. 더 나아가 지난 2014년 2월에는 의사의 처방 없이, 일반인들도 의사의 처방 없이 구매할 수 있다는 OTC(over-the-counter) 승인을 FDA로부터 받기도 했다.
이 기기와 스마트폰 앱은 단순히 사용자의 심전도 데이터를 측정하고, 저장하는 것에서 그치지 않는다. 바로 부정맥의 일종인 심방세동(atrial fibrillation)을 자동으로 진단해주기 때문이다. 이러한 자동 진단 알고리즘은 심전도 데이터의 이상 패턴을 인지하는 기계학습 방법을 이용한 것으로 인공지능의 간단한 형태라고 볼 수 있다. 이렇게 심방세동을 진단해주는 알고리즘 역시 2014년 8월에 FDA로부터 승인받았으며, 현재 일반 사용자의 앱을 통해서 서비스되고 있다.
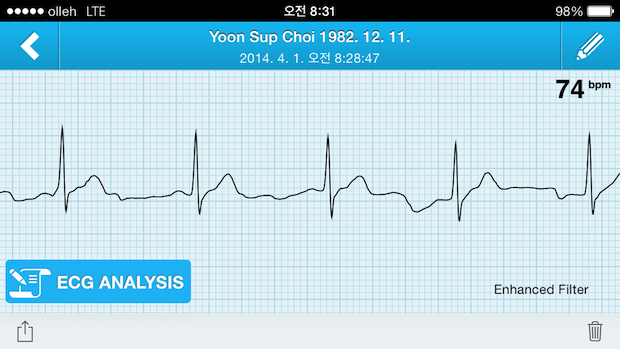 AliveCor로 측정한, 필자의 심전도 데이터
AliveCor로 측정한, 필자의 심전도 데이터
심방세동은 가장 흔한 부정맥 중의 하나로, 70-80세 이상에서는 거의 열 명 중에 한 명꼴로 발생한다. 심장의 수축과 확장이 규칙적이지 못해서 심장이 가늘게 떨고 있는 상태로, 심장이 정상보다 불규칙적이고 빠르게 뛰게 된다. 수축력을 상실한 심방은 시간이 경과하면 늘어나게 되고, 이 때문에 혈액 순환이 원활하지 않게 되면 혈전(혈액 덩어리)의 원인이 된다. 이 혈전이 결국 편두통, 만성 두통, 혈관성 치매, 더 심각하게는 뇌졸증을 초래할 수도 있다.[ref 1, 2, 3] 심방세동의 자동 진단 알고리즘은 심전도에 나타나는 이러한 심장의 이상 패턴을 인식하는 것이다.
부정맥 진단 알고리즘이 FDA의 승인을 받았다는 것은 정확도와 안전성 면에서 검증되었다는 것을 의미한다. 보고에 따르면 이 인공지능은 무려 100%의 민감도(sensitivity)와 97%의 특이도(specificity)를 보인다.
100%의 민감도는 이 알고리즘을 통해서 실제 심방세동을 가진 환자 중에 한 명도 놓치지 않고 진단할 수 있다는 의미다. 97%의 특이도는 이 알고리즘을 통해 심방세동이 ‘없다’고 진단받은 경우에는 97%의 확률로 실제로 병이 없다는 의미이다. 의사도 인간이기 때문에 민감도와 특이도와 측면에서 모두 100%일 수는 없다는 것을 고려하면 이 알고리즘은 매우 정확하다는 것을 알 수 있다.
얼라이브코의 CEO인 유안 톰슨(Euan Thomson) 여기에 그치지 않고 더욱 과감한 예측까지도 내어놓았다. 아직까지 심방세동 진단에서 인간 의사의 역할을 빼놓을 수는 없지만, 향후에는 알고리즘 만으로도 ECG의 해석을 통한 심방세동 확진이 가능하리라는 것이다. 그 근거로 자사의 데이터베이스에 있는 방대한 양의 심전도 데이터를 든다.
그에 따르면, 얼라이브코의 데이터베이스에는 110만 개 이상의 심전도 데이터를 가지고 있으며, 그중에는 약 200,000-300,000 개의 심방세동 심전도의 데이터도 있다. 이러한 데이터는 기계 학습을 통해서 더 정확성이 높은 알고리즘을 만들기 위한 토대가 될 수 있다.
더 나아가서, 얼라이브코는 애플워치로도 심전도를 측정할 수 있는 기기를 2016년 3월 발표했다. 이 기기는 애플워치 본체가 아닌 시계 줄 형태의 기기이다. 하나의 전극이 시계 줄 안쪽에 달려 있어서 한쪽 팔목에 접촉되고, 또 다른 전극 시계줄 바깥쪽에 붙어 있어 반대편 팔의 손가락으로 접촉하면 심전도를 측정할 수 있다.
2017년 상반기 기준으로 아직은 FDA 승인은 받지 않았지만, 회사 측의 데모 영상 등의 자료 등에는 애플워치로 측정한 심전도 역시 자동 알고리즘을 통해 부정맥 진단까지 해주는 컨셉을 볼 수 있다.

애플워치로 측정한 심전도 역시 자동 알고리즘으로 진단 가능하다
중환자실의 데이터 분석 및 예측
얼라이브코의 스마트폰과 애플워치 기반의 심전도 측정 및 분석은 비교적 단순한 플랫폼에서 이루어진 한 가지 종류의 데이터만 분석한다. 특히, 특정한 순간의 데이터를 분석해서 (30초 정도 측정한 순간의 심전도를 분석한다) 부정맥에 대한 진단을 내려주기는 하지만, 24시간 연속으로 데이터를 측정하지 않으며, 미래의 질병을 예측해주는 것도 아니다.
하지만 이러한 데이터 측정 및 분석 모델을 더욱 발전시키면, 전통적인 의료 환경에서도 활용할 수 있는 예방, 예측 시스템의 구현으로 이어질 수 있다. 2016년 11월 아주대학교 병원은 외상센터, 응급실, 중환자실 등의 80개 병상에서 산소포화도, 혈압, 맥박, 뇌파, 체온 등 8가지 데이터를 취합, 분석하는 인프라를 구축했다고 발표한 바 있다.
이러한 인프라가 궁극적으로 목표로 하는 바는 결국 예측이다. 응급실, 중환자실 등에서 측정하고 통합한 데이터를 인공지능으로 실시간 모니터링하고 분석하여, 부정맥, 패혈증, 급성호흡곤란증후군(ARDS) 등의 응급 상황이 발생하는 것을 1~3시간 까지 예측하겠다는 것이다. 이렇게 데이터를 분석하고 예측하는 인공지능의 개발은 국내 딥러닝 스타트업인 뷰노(VUNO)와 협업하게 된다.
이렇게 다양한 종류의, 연속적인 의료 데이터를 실시간으로 모니터링하여, 환자의 상태 변화나 질병을 예측하는 것은 앞서 강조한 예측, 예방 의료를 구현하려고 하는 좋은 사례라고 할 수 있다. 다만, 이러한 인공지능을 개발하기 위해서는 무엇보다 우선적으로 충분한 규모의 데이터 축적이 필요하다. 아주대학병원은 2017년까지 환자 2,000명의 데이터를 모으는 것을 목표로 하고 있다.
만약 이런 시스템이 정확하게 구현된다면, 중환자실과 응급실 환자의 상태를 보다 효과적으로 모니터링하여 상태가 악화되기 전에 미리 예방적인 조치를 취할 수 있으면서도, 의료진의 업무 부담도 덜어줄 수 있을 것으로 예상된다.
IBM 왓슨의 혈당 예측
연속적인 의료 데이터의 실시간 분석을 통한 예방 및 예측 의료 구현의 또 다른 사례는 바로 당뇨병 환자의 혈당 관리에서 찾아볼 수 있다. 앞서 원격 환자 모니터링의 설명에서 우리는 스탠퍼드 대학병원의 연구에서 연속혈당계로 측정한 당뇨병 환자들의 혈당 수치가 스마트폰, 애플 헬스키트, 전자의무기록 등을 거쳐 병원으로 전송되어 분석되는 사례를 살펴본 바 있다.
이러한 원격 환자 모니터링의 경우에도 이 연속 데이터를 의료진이 24시간 365일 모니터링하기는 어렵다. 또한 이 데이터를 바탕으로 향후 몇 시간 뒤 혈당의 변화나 저혈당 쇼크가 올지의 여부를 예측하는 것도 사람의 역량만으로는 용이하지 않다. 때문에 당뇨병 환자의 혈당 관리에 있어서도 향후 인공지능의 역할은 더욱 커지게 될 것이다.
이러한 목적으로 활용되고 있는 인공지능 중의 하나가 바로 IBM 왓슨이다. IBM의 인지 컴퓨팅(cognitive computing) 시스템으로 유명한 IBM 왓슨은 다양한 의료 분야에서 활용되고 있는 인공지능의 대표적인 사례로 꼽힌다.
왓슨은 2011년 제퍼디!(Jeopardy!)라는 미국의 유명 퀴즈 프로그램에서 인간 챔피언 두 명을 압도적으로 이기면서 화려하게 데뷔했다. 그 이후 2012년부터 뉴욕의 메모리얼 슬론 캐터링 암센터(Memorial Sloan Kettering Cancer Center)에서 폐암에 대한 방대한 분량의 논문, 임상시험 결과, 치료 가이드라인, 치료 사례 등을 학습했다.[ref 1, 2, 3, 4, 5]
이는 현재 폐암, 유방암, 직장암, 대장암, 위암 등을 진단하는 왓슨 포 온콜로지(Watson for Oncology)라는 솔루션으로 개발되어, 태국의 범룽랏 병원, 인도의 마니팔 병원에 이어, 한국의 길병원, 부산대병원 및 건양대병원에도 도입되게 되었다. (왓슨 포 온콜로지에 대해서는 다음 장에서 자세히 알아보도록 하겠다)
![[1.5hr v2] How AI would innovate the medicine of future 170204 copy.001](https://www.yoonsupchoi.com/wp-content/uploads/2017/03/1.5hr-v2-How-AI-would-innovate-the-medicine-of-future-170204-copy.001-1.jpeg)
퀴즈쇼로 시작한 지 7년째에 접어드는 왓슨은 이제 한 가지 종류의 인공지능이라기보다, 여러 분야의 문제를 풀기 위해 다방면으로 적용되는 IBM의 인지 컴퓨팅 서비스를 대표하는 일종의 브랜드라고 보는 것이 더 적당할 것 같다.
의료 분야만 하더라도 왓슨은 암 환자 진단 이외에도, 암 유전체 분석, 영상 의료 데이터 분석, 임상 시험 환자 매칭, 전자의무기록 분석 등의 다양한 문제의 해결에 적용되고 있으며, 모두 ‘왓슨’이라는 이름을 사용하지만 개별 문제에 적용되는 세부적인 기술은 다소간의 차이가 있기 때문이다.

지난 몇 년 간 의료 분야에서 왓슨의 적용범위는 빠르게 확대되어 왔다. IBM은 다수의 제약회사, 의료 기기 및 의료 데이터 관련 기업을 인수하거나 파트너십을 맺으면서 왓슨 중심의 의료 산업 생태계를 만들어가고 있다. 이러한 점을 고려했을 때, 필자가 이 글을 쓰고 있는 2017년 상반기의 왓슨과 독자들이 이 글을 읽는 시점의 왓슨의 범위는 크게 차이가 있을 가능성도 있다는 것도 알아두자.
인공지능을 통한 저혈당 예측
IBM 왓슨은 개방형 API를 제공하여 외부의 앱이나 기기 개발사들이 왓슨의 인공지능을 활용할 수 있도록 하고 있다. 이러한 방식으로 왓슨의 생태계를 확장시켜 나가겠다는 복안이다. 그렇게 활용되고 있는 의료 분야 중의 하나가 바로 당뇨병 환자의 혈당 관리를 위한 것이다.
혈당이 적정한 수준으로 유지되지 않는 당뇨병 환자들은 평생 동안 자신의 혈당이 정상 범위 내에 유지되도록 많은 노력을 해야 한다. 혈당이 너무 높게 유지되면 실명의 주요 원인인 당뇨성 망막병증 등 합병증의 위험이 있고, 혈당이 너무 낮으면 저혈당 쇼크로 심할 경우 목숨이 위험할 경우도 있다. 하지만 혈당에 영향을 미치는 요소는 음식, 운동, 인슐린, 스트레스 등으로 다양하기 때문에, 당뇨병 환자들은 혈당 유지를 위해서 일상생활에서도 많은 불편함을 감수해야 한다.
만약 당뇨병 환자에게 몇 시간 뒤의 혈당 변화를 미리 예측하여 알려줄 수 있다면 매우 편리할 것이다. 혈당이 너무 높아지거나, 너무 낮아질 것을 정확하게 알 수 있다면, 이를 대비하여 인슐린을 미리 투여하거나, 당분을 보충하여 혈당을 조절할 수 있을 것이기 때문이다.
2016년 1월 IBM은 메드트로닉과 협력하여 당뇨병 환자의 혈당 변화를 미리 예측할 수 있는 솔루션을 개발했다고 발표했다. 메드트로닉은 연속혈당계, 인공췌장 등의 의료 기기를 만드는 회사로, 파트너십을 통해서 IBM 왓슨 생태계에 참여하고 있는 대표적인 회사 중의 하나다. 메드트로닉의 연속혈당계로 지속적으로 측정한 당뇨병 환자의 혈당을 IBM 왓슨이 모니터링하고 실시간 분석하여, 저혈당증(hypoglycemia)를 최대 3시간까지 미리 예측할 수 있다는 것을 600명의 익명 환자의 데이터로 증명했다는 것이다.
이후 2016년 9월에는 메드트로닉은 슈거아이큐(Sugar.IQ)라는 왓슨 기반의 앱을 출시한다고 밝혔다. 앞서 발표했던 앱을 기반으로 개발한 것으로 보인다. 발표에 따르면 이 앱은 특정 당뇨병 환자의 음식 섭취와 그에 따른 혈당 변화, 인슐린 주입 등의 과거 데이터를 바탕으로, 지금부터 이 환자의 혈당이 앞으로 어떻게 변화할지를 왓슨이 예측해주는 방식이다. 예를 들어, 내가 지금 참치 샐러드를 먹으면, 몇 시간 뒤에 혈당이 어떻게 변화할지를 알 수 있는 것이다.
아마도 당뇨병 환자들이 가장 궁금해하는 것은, “잠시 후에 나의 혈당이 어떻게 변화할까?”, “오늘 밤에 수면 도중 저혈당의 가능성이 있을까?”, “그래서 지금 당장 내가 인슐린 양을 얼마나 조절해야 하나?” 와 같은 질문일 것이다. 혈당 변화를 정확하게 예측하고, 필요한 음식이나 인슐린을 계산하기 위해서는 여러 복합적 요인이 작용하며, 개인 환자별 차이도 크다.
따라서, 정확한 계산을 위해서는 과거의 음식 섭취 기록, 인슐린 투여와 함께 혈당 데이터를 지속적으로 축적시켜나가는 것이 필요하다. 이러한 데이터를 바탕으로 개별 환자에 대해서 향후 혈당 변화를 정확하게 예측할 수 있을 것이다.
다만 이 슈거아이큐라는 앱에 대해서는 아직 논문이나 임상 연구 결과가 발표지 않은 것으로 보인다. 따라서 예측 정확성, 안전성 등에 대해서는 추가 검증이 필요하다. 하지만 인공지능을 활용한 만성질환의 관리가 향후 어떻게 이루어질 수 있는지를 잘 보여주는 사례라고 할 수 있다.
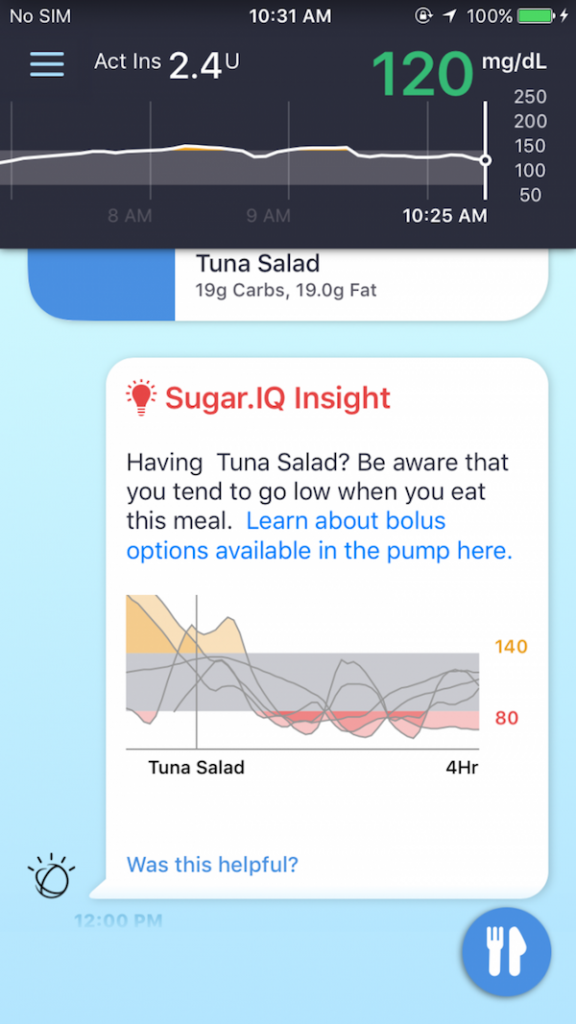 슈거아이큐
슈거아이큐
개인 맞춤형 혈당 관리
인공지능을 활용한 혈당 관리에는 앞서 언급한 혈당 변화의 예측과 함께 살펴봐야 할 또 하나의 측면이 있다. 바로 예측 의료, 예방 의료와 함께 4P의료의 다른 한 축인 맞춤 의료(personalised medicine)에 관한 것이다.
혈당 변화를 예측하기 위해서 가장 중요한 요인 중 하나는 바로 섭취한 음식에 대한 식후 혈당 반응이다. 그런데 최근 연구 결과에 따르면 동일한 음식을 섭취하더라도 환자에 따라서 혈당 변화는 정반대가 될 수도 있다. 기존에 당뇨병 환자들은 각 식품의 혈당 지수, 탄수화물 함량을 기반으로 식후 혈당 변화(PPGR)을 판단해왔다.
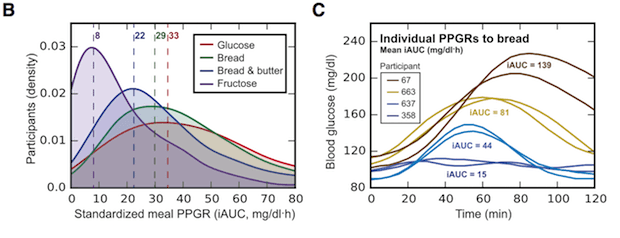
하지만 2015년 11월 세계 최고 학술지 쎌(cell)에 발표된 연구에 따르면, 동일한 음식물을 섭취했을 때에도 각 환자마다 식후 혈당 변화는 매우 다양하게 나뉘며, 때로는 정반대의 혈당 변화를 보인다. 연구에서는 이를 800명의 환자군에 대하여 증명했다.
예를 들어, B번 그림과 같이 글루코즈, 빵, 빵&버터, 프럭토즈 등의 다양한 음식에 대해서 사람별로 혈당의 변화가 다양하게 분포함을 알 수 있다. 그림 C에서는 빵에 대한 식후 혈당 변화가 4명의 환자 중 67번 환자는 200 mg/dl 이상으로 높아지기도 하고, 358번 환자의 경우에는 별다른 변화가 없는 것을 볼 수 있다.
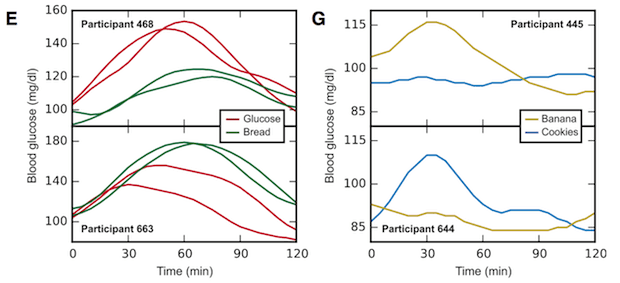
특히, 그림 E, G를 보면 빵, 바나나, 쿠키 같은 음식에 대해서 두 환자의 혈당 변화가 반대로 나오기도 한다. 445번 환자의 경우 바나나는 혈당을 높이고, 쿠키는 아무런 변화가 없었던 반면, 644번 환자는 바나나는 혈당을 높이지 않았지만 쿠키는 혈당을 높이는 효과가 있었다.
그렇다면 다른 환자가 아닌, 나에게 어떤 음식이 혈당을 어떻게 변화시키는지를 어떻게 알 수 있을까? 이 연구에서는 다름 아닌 스마트폰을 이용한 식단 기록, 활동량 데이터, 메드트로닉의 연속혈당계로 측정한 혈당 데이터를 환자별로 측정하여, 기계 학습을 바탕으로 식후 혈당 변화 예측 모델을 만들었다.
이렇게 만든 예측 모델이 기존의 식품별 탄수화물 함량 기반의 계산보다, 식후 혈당 변화를 더 정확하게 예측할 수 있었다. 뿐만 아니라, 이러한 모델을 통해서 개별 환자에게 혈당 조절에 ‘좋은 음식’과 ‘나쁜 음식’을 선별할 수 있다는 것까지 보여주었다.
눈치를 챘을 수도 있겠지만, 이 연구는 그 자체로도 디지털 의료 구현의 3단계를 잘 담고 있다. 식단, 활동량, 혈당 등의 환자 유래의 의료 데이터(PGHD)를 측정하여, 이를 통합하고 인공지능으로 분석하여 식후 혈당 변화 예측 모델을 만든 것이다.
한 걸음 더 나아가, 이 연구와 앞서 언급한 IBM과 메드트로닉의 슈거아이큐와 같은 연구가 합해질 경우를 상상해보자. 슈거아이큐에서는 과거의 데이터를 바탕으로 몇 시간 뒤의 혈당 변화를 예측할 수 있다. 이렇게 예측된 혈당 변화에 대처하기 위해서, 인슐린이나 적절한 음식을 섭취해야 한다. 이 특정 환자가 섭취해야 할 ‘맞춤 음식’은 이번 연구에 소개된 모델을 통해서 도출할 수 있을 것이다.
필자는 이렇게 인공지능을 이용한 혈당 관리가 4P 의료의 모든 요소를 구현하는 좋은 사례라고 생각한다. 환자가 스스로 생산한, 환자 유래의 의료 데이터를 활용하여(참여 의료), 향후 몇 시간 뒤의 혈당 변화를 예측하고 (예측 의료), 3시간 뒤에 올 저혈당증을 예방하기 위하여 (예방 의료), 해당 개별 환자의 혈당 변화를 유도하기에 적합한 음식을 적절한 양을 섭취(맞춤 의료)하는 것이 가능해지기 때문이다.
유전 정보 기반의 인공지능 다이어트
우리는 ‘디지털 의료의 3단계’ 중 첫 번째인 데이터 측정에서 스마트폰 어플리케이션, 웨어러블 기기뿐만 아니라, 개인 유전 정보까지 언급했다. 이번에는 세 가지 종류의 데이터를 모두 통합하여 인공지능으로 분석함으로써 체중 감량 등을 위한 맞춤형 건강 조언을 주는 사례를 살펴보자.
미국 샌디에이고에 위치한 패쓰웨이 지노믹스(Pathway Genomics)는 23앤미와 같이 개인 유전 정보를 분석해주는 기업이다. 암 유전자, 심혈관 질환 유전자 검사 등 질병에 특화된 검사들과 함께, ‘패쓰웨이 핏(Pathway FIT)’이라고 하는 검사를 통해 식습관, 영양, 운동, 체중감량, 지질 및 설탕 대사 등 보다 실용적인 데이터를 제공하기도 한다.
 필자의 패쓰웨이 핏 분석 레포트 중 일부
필자의 패쓰웨이 핏 분석 레포트 중 일부
예를 들어, 필자의 패쓰웨이 핏 분석에 따르면 저탄수화물 식사가 좋으며, 공복감과 포만감을 느끼는 정도는 보통이다. 섭식 무절제에 대한 가능성은 낮으며, 비타민 중에서는 비타민 B12, D, E 의 섭취를 증대해야 한다. 근력 훈련은 효과가 적은 편이며, 운동에 따른 체중 감소와 혈압 반응에 대하여 운동이 권장된다. 또한 비만 가능성은 평균이지만, 감량 후 체중 재증가 가능성이 높고, 혈당 수치가 평균보다 높을 가능성이 있다.
이러한 부분들은 일상생활 속에서도 식사 메뉴를 고르거나, 영양제를 고르고, 운동할 때 실제로 참고할 수 있는 부분들이다. 이런 정보를 잘 활용하기만 한다면, 식습관, 운동, 체중 감량, 질병 관리 등에서도 보다 좋은 효과를 보일 가능성도 있다.
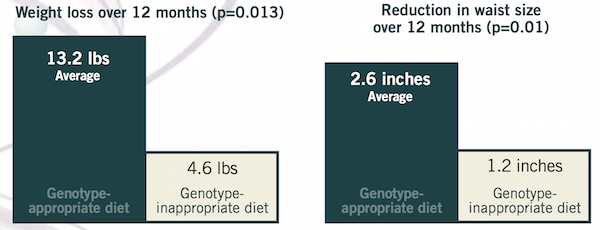
실제로 체중 감량의 경우, 유전 정보에 기반하면 효과가 더 좋다는 연구 결과가 있다. 2010년 인터루킨 제네틱스 (Interleukin Genetics)와 스탠퍼드 대학이 145명의 과체중 및 비만 여성들을 대상으로 한 연구에 따르면 유전형에 적합한 음식을 먹은 사람은 체중의 5.3%를 감량했는데 비해서, 그렇지 않았던 사람들은 2.3%를 감량하는데 그쳤다.
특히, 유전형에 적합한 음식을 먹은 사람은 12개월간 평균 13.2 파운드를 감량했는데 비해, 다른 사람들은 평균 4.6 파운드를 감량해서 약 2.5배의 차이가 났다고 한다. 허리둘레도 유전형에 적합한 음식을 먹은 사람은 2.6인치가 감소했으나, 대조군은 1.2인치 밖에 줄지 않았다. 실험군과 대조군 사이의 격차는 통계적으로도 유의했다.
유전 정보+애플 헬스키트+왓슨=OME
그렇다면 이런 유전정보, 식습관, 운동, 등의 데이터를 어떻게 효과적으로 통합하고, 분석하여 건강 관리에 유용한 조언을 들을 수 있을까? 이 부분 역시 인공지능을 접목하려는 시도가 이뤄지고 있다.
패쓰웨이 지노믹스 (Pathway Genomics)는 IBM 왓슨을 이용하여 개인의 건강 정보, 유전 정보 등을 분석하여 개인 맞춤 건강 조언을 제공하는 오미(OME)라는 앱을 개발하여 클로즈드 알파 테스트를 2016년 1월 시작했다. [ref 1, 2]
유전정보와 웨어러블 등의 데이터를 통합하여, 인공지능이 분석,
맞춤형 건강 조언을 주는 오미(OME) (출처)
이 앱은 사용자의 건강 상태를 파악하고 조언을 주기 위해서, 외부에서 세 종류의 데이터를 가져온다. 먼저 우리가 데이터 통합 부분에서 다루었던 애플 헬스키트 플랫폼에서 데이터를 가져온다. 또한 웨어러블의 대명사 핏빗(fitbit)과 스마트폰의 GPS 데이터를 가져온다. (활동량 측정계 시장 점유율 1위인 핏빗은 애플 헬스키트 생태계에 들어가지 않고 있어서, 데이터를 헬스키트와는 별도로 가져와야 한다)
오미는 이러한 애플 헬스키트, 핏빗, GPS 데이터에 패쓰웨이 지노믹스가 분석한 개인 유전 정보를 결합시키고, 이런 데이터를 바로 IBM 왓슨이 분석하여 사용자가 일상생활 속에서 ‘행동’ 으로 옮길 수 있는 맞춤형 건강 조언을 제공하겠다는 것이다.
예를 들어서, 사용자가 지방 성분을 대사하는데 영향을 주는 유전자에 변이가 있거나, 포만감을 느끼는 유전자에 특정 변이가 있다면 식습관을 결정하기 위해서 참고할 수 있다. 오미는 이 분석 결과와 최근의 운동량, 식습관 등을 고려하여 ‘유전적으로 이상적인 식사 계획’을 짜주기도 하고, 심지어 GPS로 사용자의 위치를 파악하여 근처에 있는 특정 식당의 메뉴를 추천해주기도 한다.
향후 패쓰웨이 지노믹스는 전자의무기록(EMR) 데이터와 보험 정보 등도 OME 서비스에 추가할 계획이다. 이렇게 되면, 헬스케어 데이터, 유전정보, 의료데이터, 보험 데이터가 통합되는 더욱 완전한 그림이 그려질 수도 있을 것이다.
필자는 2015년 5월 서울대학병원 교수님들과 패쓰웨이 지노믹스를 방문한 적이 있다. 방문 당시 최고 혁신 책임자인 마이클 노바(Michael Nova) 박사로부터 개발 중이던 오미의 시연을 볼 기회가 있었다.
사용자는 스마트폰이나 태블릿 PC의 오미 앱을 실행시키고, “오늘 식사는 어떤 메뉴가 좋을까?”, “오늘은 어떤 운동을 할까?”, “내가 이 약을 먹어도 될까?” 하는 질문을 던지면, 왓슨이 이 질문 및 데이터를 분석해서 답을 주게 된다. 서로 다른 사용자를 가정하고 질문을 던지면, 동일한 질무에 대해서도 다른 조언을 내어주었다.
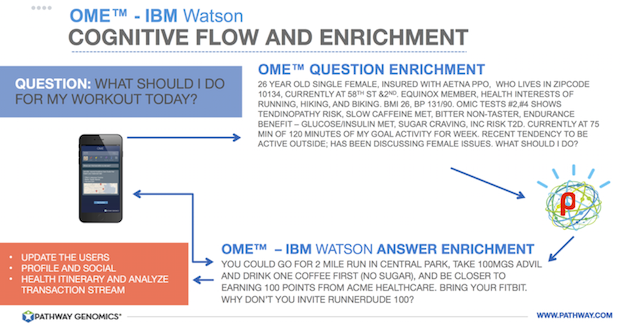
‘오늘 무슨 운동을 해야 하나?’ 는 질문에 대해서
다양한 데이터를 기반으로 분석해주는 OME
2016년 1월에 오미의 베타 테스트가 시작되었지만, 아직 이 앱의 정식 출시 뉴스는 들려오지 않고 있다. 또한 이 앱이 권장하는 건강 조언이 실제로 효과적이고, 정확한 것인지에 대해서도 추가적인 검증이 필요할 것이다. (시연할 당시 마이클 노바 박사는 질병 진단 등 의학적인 판단이 필요한 질문의 경우에는 어떤 답을 주느냐는 필자의 질문에, 그런 경우에는 오미는 자세한 답변을 하지 않고, 의료 전문가와 상의하라는 정도로 알려준다고 언급하였다) 또한, 사용자들이 이렇게 인공지능이 내리는 조언을 따르고 싶어 할지의 여부도 완전히 별개의 문제로 봐야 할 것이다.
하지만 웨어러블, 스마트폰 등으로 측정한 건강 데이터가 개인 유전정보와 결합하여 사용자에게 실질적인 도움을 주는 것은 디지털 헬스케어가 궁극적으로 지향하는 방향 중의 하나이다. 인공지능을 이용하여 여러 종류의 건강 데이터를 해석하고 가치를 더하려고 하는 오미가 성공적 일지는 더 지켜봐야 하겠지만, 이러한 시도가 의미하는 바는 적지 않다고 생각한다.
인공지능의 유전 정보 분석
패쓰웨이 지노믹스의 오미는 개인 유전 정보의 결과를 다른 환자 유래의 의료 데이터와 통합하여 해석하였지만, 유전 정보 자체를 해석하기 위해서도 인공지능의 역할은 더욱 중요해질 것이다.
앞서 강조하였듯이, 유전 정보 분석 기술의 발전에 따라서 이제는 1,000달러 게놈 시대를 넘어서서, 100달러 게놈의 시대를 바라보는 때가 되었다. 하지만 이러한 유전체 데이터를 저렴하고 빠르게 생산하는 것과 제대로 해석하는 것은 별개의 문제라고도 볼 수 있다. 유전체 데이터는 그 자체로도 방대한 크기의 빅데이터이며, 유전적 변이가 생물학적으로, 의학적으로 가지는 의미를 파악하기 위해서는 아직 많은 기술적 난제를 해결해야 한다.
지금도 유전 변이에 대해서 많은 연구가 진행되고 있다. 하지만 특정한 유전 변이가 특정 질병의 발병이나 진행에 관련하여 어떠한 역할과 기능을 가지며, 더 나아가 질병 치료나 예방을 위해서 어떤 의미를 가지는지 파악하는 것은 여전히 어려운 경우가 많다.

환자들 뿐만 아니라, 정상인들도 누구나 많은 수의 유전 변이를 가지고 살아간다. 연구에 따르면 한국인의 경우에도 평균적으로 보유하고 있는 SNP(단일 염기 다형성)는 무려 340만~360만 개나 된다. 이 수치에는 인종별로 다소간에 차이가 있으나, 대부분 300만 개 이상이다.
이 중에서 어떤 것들은 우리의 머리 색깔이나 키, 몸무게 등에 영향을 주기도 할 것이고, 또 어떤 것들은 질병의 발병에 영향을 주기도 한다. 또 어떤 것들은 우리의 건강이나 표현형에 아무런 영향을 주지 않기도 한다. 특히, 정상인들 중에도 90%의 사람들은 질병에 관계되었다고 알려진 유전 변이(pathogenic variant)를 적어도 하나 이상 보유하고 있다. 하지만 이런 변이를 가진 모든 사람들이 질병이 발병하는 것은 아니다.
더 나아가, 수많은 유전 변이 중에 기능이 알려져 있는 것보다는 알려져 있지 않은 미지의 것들이 더 많다. 이를 유전학자들은 VUS(Variant of Uncertain Significance), 즉 ‘중요도가 불명확한 변이’라고 부른다. 유전 정보의 분석에는 이 수많은 VUS를 어떻게 해석할 것인지가 중요한 문제다.
아직은 인공지능이 유전체 분석에는 활발하게 적용되지는 않고 있다. 하지만 앞으로는 유전체 분석과 유전 변이의 기능, 역할 파악 및 질병 치료와 관련하여 연구가 확대될 것이라고 예상한다. 이 부분 역시 복잡하고 방대하고, 복잡한 데이터를 바탕으로 인공지능이 학습하고, 분석 및 예측이 필요하기 때문이다.
예를 들어, 암 환자의 유전자를 분석한다고 해보자. 환자에게서 발견된 유전 변이들 중에 기존 연구 결과 암과 관련된 변이가 있을 수도 있고, 혹은 기능이 알려지지 않은 변이, 즉 VUS가 있을 수도 있다.
만약 암 유전자에 변이가 있다면, 이것이 정말 암과 관련된 것인지를 판단하는 것이 필요하다. 특히 이 환자의 암을 발병시키는데 주요한 역할을 했을지, 혹은 보조적인 역할을 했거나 별다른 역할이 없었을지를 구분하는 것이 중요하다. 발병에 주도적인 역할을 한 전자를 흔히 운전자 변이(driver mutation)라고 부르는데, 현재는 이를 판별할 수 있는 방법은 마땅치 않다.
또한 많은 경우, 기존에 기능이 알려진 변이는 없고, VUS만 발견되는 경우가 있다. 이러한 환자라면, 이런 알려지지 않은 변이의 기능이나 역할을 분석하고 예측하여 중요도를 판별하는 것도 필요할 것이다. 이러한 분석을 위해서는 임상 데이터뿐만 아니라, 인종, 환경, 병력, 가족력, 생활습관 등의 데이터까지 복합적으로 고려해야 할 수도 있다. 인공지능을 통한 VUS 분석의 중요성은 앞으로 더 커지고, 많은 시도가 있을 것으로 예상한다.
왓슨의 암 유전체 해석
IBM 왓슨이 암 유전체 데이터를 분석하기 위해 활용되기 시작한 것도 이러한 측면에서 해석할 수 있다. 2017년 1월, 유전체 분석 기기와 분석 서비스를 제공하는 미국의 일루미나(Illumina)는 노바식(NovaSeq)이라는 새로운 기기를 내어놓으며, 100불 유전체 시대가 머지않아 도래할 수도 있음을 알렸다. 그런데 이 때 함께 발표한 것이 바로 IBM 왓슨과의 협력이었다.
이 발표에서 일루미나는 ‘트루사이트 투머 170(TruSight Tumor 170)’에서 나온 유전 변이 결과를 해석하여 종양 전문의에게 전달하는 보고서를 제공하기 위해 왓슨을 활용한다. ‘트루사이트 투머 170’은 170개의 암 유전 변이를 검사하는 유전자 패널이다.
사실 모든 종양 전문의가 유전체 결과를 해석할 수 있는 역량이나 시간적 여유가 있는 것은 아니기 때문에, 이렇게 바로 진료에 적용할 수 있는 보고서를 만들어주는 것도 의미가 있다. 특히 매일같이 쏟아져 나오는 논문을 모두 의사가 읽기는 어려우므로, 최신 논문의 내용을 반영하여 왓슨이 유전 변이에 대한 해설을 해주는 것은 의미가 있을 수 있다.
하지만 단 170개 정도의 유전 변이만을 해석하는 것이라면, 인공지능까지 필요할까 하는 생각이 든다. 이 정도 적은 수의 변이라면 왓슨이 없이도 충분히 해석이 가능하기 때문이다. 하지만 여기에서 머물지 않고 더 나아가 전장 유전체 분석이나, 전장 엑솜 분석을 통해 2만 개에 달하는 유전자를 모두 분석한다면, 인공지능의 도움이 필요하게 될 것이다.
왓슨의 여러 솔루션 중에, 유전체 분석 결과의 해석을 도와주는 ‘왓슨 포 지노믹스(Watson for Genomics)’ 라는 것이 있다. 부산대학교 병원의 경우, 암 환자 진료에 도움을 주는 왓슨 포 온콜로지와 함께 이 왓슨 포 지노믹스도 함께 도입했다.
아직까지 왓슨 포 지노믹스는 유전 정보 분석의 결과를 바탕으로 기존에 알려진 유전자와 변이의 기능에 대하여 설명을 해주는 것에 그치고 있는 것으로 보인다. 즉, 기존에 알려져 있지 않은 새로운 기능의 예측이나, 중요도를 분석해주지는 않는다.
하지만 앞으로 유전체 데이터의 분석에서 인공지능은 단순히 알려진 변이의 해설에 그치지는 않을 것이다. 인공지능은 유전체 분석에서 질병 관련 유전자의 중요도 판별, VUS의 기능 예측과 이를 기반으로 한 환자 맞춤 치료법을 권고하는 것까지 발전할 것으로 예상한다.
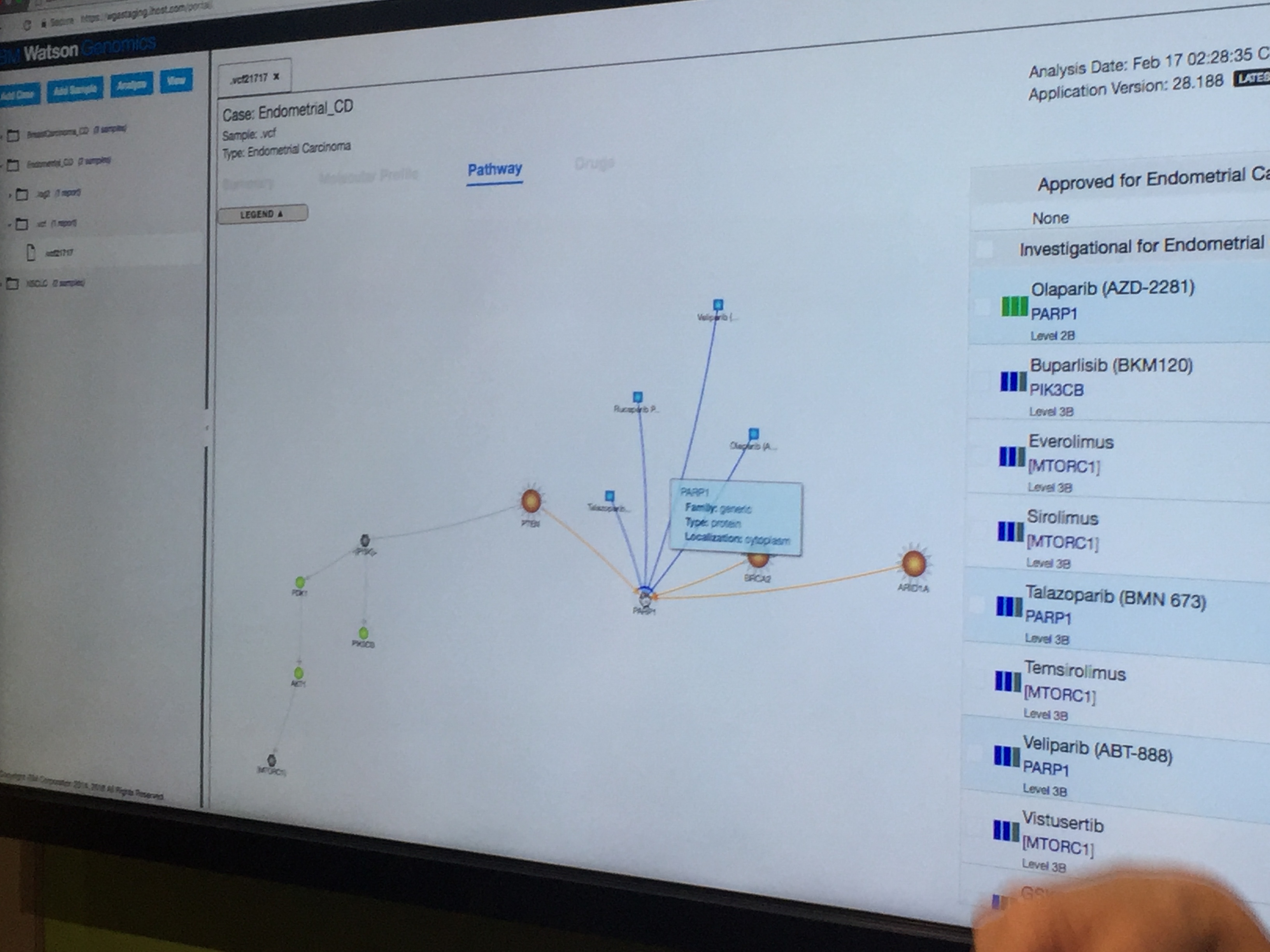 HIMSS 2017에서 발표된 왓슨 포 지노믹스 (서울아산병원 감혜진 박사님 제공)
HIMSS 2017에서 발표된 왓슨 포 지노믹스 (서울아산병원 감혜진 박사님 제공)
실제로 2016년 11월에 세계 최고의 유전체 연구소인 보스턴의 브로드 연구소(Broad Institute)는 IBM 왓슨과 협력하여 암 환자의 치료법 선택에 도움을 줄 수 있는 연구를 시작하기로 했다. 암 환자 수천 명의 유전체 데이터를 분석하여, 특정 환자에게 어떤 항암제가 효과가 있을지 혹은 내성이 있을지를 파악하는 방법을 개발할 것으로 기대하고 있다. 이런 연구에 대해서, 국내 유전체 분석 회사인 테라젠이텍스의 김태형 본부장은 “유전체 기술과 인공지능 기술을 결합해서 암세포가 항암제에 대한 내성이 생기는 기전을 이해하는 계기가 될 수도 있다”고 말한다.
의사를 능가하는 인공지능
지금까지 의료 데이터의 분석을 위해서 인공지능이 어떻게 활용되고 있는지, 그리고 앞으로 어떤 방향으로 활용될 것인지에 대해서 몇 가지 사례를 살펴보았다. 이는 데이터의 측정-통합-분석으로 이어지는 디지털 의료의 3단계에서 ‘분석’에 해당하는 것이다.
데이터의 분석은 데이터 사이언티스트 등 사람의 역할도 중요하겠지만, 데이터의 크기가 많아지고 복잡도가 증가할수록, 그리고 정확도와 시의성이 중요할수록 인공지능의 역할이 커지게 될 것이다. 다시 강조하자면, 디지털 의료에서 결국 데이터 해석에 대한 고민은 필연적으로 인공지능이라는 해결책으로 귀결될 수밖에 없다.
의료에 인공지능이 구현되고 진료 현장에서 활용되기 위해서는 여러 기술적, 제도적 난관이 있을 것이다. 정확성이나 안전성의 검증, 더 현실적으로는 의료비 및 건강 보험 적용 등에 대한 이슈도 있을 수 있다. 그럼에도 불구하고, 만약 우리가 이러한 문제들을 해결하고 인공지능을 적절히 이용할 수 있으면 마침내 우리는 예방, 예측, 정밀, 참여 의료의 4P 의료의 구현에 한 걸음 더 다가갈 수 있으리라고 본다.
사실 인공지능의 의료 분야 적용은 훨씬 폭넓은 범위에 걸쳐 빠르게 이뤄지고 있다. 특히 기존에 인간의 인지능력을 바탕으로 해석하거나 판독하던 의료 데이터의 경우, 이미 인공지능의 실력이 인간 전문의를 능가하는 결과들이 속속 등장하고 있다. 인간의 시각적 인지 능력을 이미 인공지능이 넘어섰다는 것을 고려한다면, 그리 놀라운 일이 아닐 수도 있다. 여기에는 대부분 딥러닝이 큰 역할을 하고 있다.
구글은 2016년 11월 JAMA에 출판한 논문에서 약 13만 장에 달하는 안저 데이터를 딥러닝으로 학습하여, 당뇨성 망막 병증을 인간 안과 전문의보다 더 정확하게 판독할 수 있음을 보여주었다. 그런가 하면 스탠퍼드 연구진들은 지난 2월 네이처 논문을 통해 피부과 병변 이미지를 분석하여 피부암 등의 판독에 대해 역시 피부과 전문의보다 인공지능의 성적이 더 좋음을 보여주기도 했다. 2017년 3월에 구글은 또 다른 논문을 통해 생검한 유방암 환자의 병리 조직 데이터 판독 역시 병리과 전문의보다 인공지능이 더 정확함을 증명했다.
이러한 사례들에 대해서는 다음 장에서 더욱 자세히 알아보겠지만, 의료 분야에서 인공지능의 적용은 앞으로 더욱 확대될 것이 명약관화하다. 이에 따라서 당뇨병, 부정맥, 비만 등 만성 질환 환자의 관리, 유전체 정보 분석을 통한 건강 관리나 암 환자 치료에도 영향을 미칠 것이다. 뿐만 아니라, 응급실이나 중환자실의 환자를 치료하고, 병원의 일상적인 진료 프로세스에도 크고 작은 변화가 야기될 가능성이 높다. 이러한 과정에서 전통적인 의사의 역할, 그리고 환자의 역할까지도 지금과는 크게 달라질 것이다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.