이제는 ‘디지털 의료의 3단계’에서 세 번째 단계에 해당하는 데이터의 분석에 대해서 알아보려 한다. 1단계인 ‘측정’에서 우리는 많은 종류의 헬스케어 데이터가 다양한 방식을 통해서 측정될 수 있다는 것을 알아보았으며, 2단계 ‘통합’에서는 이 다양하고 방대한 데이터를 통합하기 위한 플랫폼에 대해서도 살펴보았다. 이제는 이렇게 측정하고 통합한 데이터를 어떻게 분석하고 해석할 것인지에 대해서 알아볼 차례다.
아무리 중요한 정보가 담긴 데이터를 다양하고 폭넓게 측정하고 통합해놓았다고 할지라도, 그 데이터 속에 담긴 의미를 제대로 파악하지 못한다면 아무런 쓸모가 없을 것이다. 질병을 예방하고 치료, 관리하며 건강을 유지하기 위해서는 우리가 끊임없이 만들어내는 데이터를 효과적으로 해석할 필요가 있다.
“디지털 의료는 어떻게 구현되는가” 시리즈 보기
- 변혁의 쓰나미 앞에서
- 누가 디지털 의료를 이끄는가
- 데이터, 데이터, 데이터!
- 4P 의료의 실현
- 스마트폰
- 이제 스마트폰이 당신을 진찰한다
- 웨어러블 디바이스
- 개인 유전 정보 분석의 모든 것!
- 환자 유래의 의료 데이터 (PGHD)
- 헬스케어 데이터의 통합
- 헬스케어 데이터 플랫폼: 애플 & 발리딕
- 빅 데이터 의료
- 원격 환자 모니터링
- 원격진료
- 인공지능
데이터 폭발의 시대
다양한 웨어러블 기기, 사물인터넷 센서, 스마트폰 앱과 가젯, 유전 정보 분석 등으로 한 사람에 대해 다방면으로 측정한 헬스케어 데이터를 모두 통합하는 클라우드 기반의 플랫폼까지 구축해놓았다고 가정해보자. 비로소 우리는 그 사람의 총체적인 건강상태를 복합적이고 다차원적으로 확인할 수 있게 될 것이다.
그런데 이렇게 데이터가 풍부한 상황에서 필연적으로 대두될 수밖에 없는 새로운 문제가 있다. 바로 데이터가 많아도 너무 많다는 것이다. 현재 인류는 분야를 막론하고 끝없이 쏟아져 나오는 거대한 규모의 데이터에 압도당하고 있다. 데이터가 많아질수록 저장, 전송, 보안 등에 관한 새로운 문제들이 생길뿐만 아니라, 특히 이를 어떻게 해석하고 분석할지의 문제가 커지게 된다.
필자는 앞서 개별적인 헬스케어 데이터의 통합을 퍼즐 맞추기에 비유한 바 있다. 하지만 만약 퍼즐 조각이 무한대로 많은 데다가, 끊임없이 새로운 퍼즐 조각이 만들어진다면 전체 그림을 완성시키고, 그 그림이 무엇을 의미하는지 파악하기는 어려울 것이다. 지금의 상황이 그러하다.
‘빅 데이터’라는 용어는 몇 년 전 처음 사용되면서 일종의 유행어처럼 번져나갔지만, 이 용어만으로는 현재의 상황을 적절히 설명하기에는 부족한 감이 있다. 쏟아지는 데이터의 양은 분야를 막론하고 기하급수적으로 증가하고 있기 때문이다. 2010년 이코노미스트에 따르면 인류가 가진 디지털 데이터는 매 5년마다 10배씩 증가하고 있다. 그야말로 데이터 폭발(data explosion)의 시대다.
데이터의 폭발은 분야를 가리지 않는다. 천문학을 보자. 뉴멕시코의 천체망원경 슬로언 디지털 스카이 서베이(Sloan Digital Sky Survey)는 2000년 구동을 시작한 이후 단 몇 주만에 천문학 역사상 축적된 데이터보다 더 많은 데이터를 수집했다. 2016년 칠레의 천체망원경 LSST(Large Synoptic Survey Telescope)은 이 정도의 데이터를 단 5일 만에 축적한다.
페이스북은 2017년 기준으로 전 세계 20억 명에 가까운 사용자들이 하루에 3억 개의 사진을 업로드한다. 또한 매 60초마다 51만 개의 댓글과 416만 개의 좋아요, 약 30만 개의 상태 메시지가 생성된다. 트위터에서는 2016년 기준으로 1초에 6,000개씩, 매일 5억 개의 트윗이 올라온다. 2010년만 하더라도 하루 트윗은 5천만 개였으나, 불과 몇 년만에 열 배로 성장한 것이다. 전 세계 13억명이 사용하는 유투브에는 1분마다 300시간 분량의 동영상이 업로드되며, 매일 약 50억 건의 시청이 이루어진다.
 매 1분 동안 생산되는 데이터의 양 (출처: Domo)
매 1분 동안 생산되는 데이터의 양 (출처: Domo)
빅 데이터 하면 유전체 정보도 빼놓을 수 없다. 앞서 개인 유전 정보를 설명할 때 언급했듯이, 연구에 따르면 2025년 경에 인류가 가질 가장 큰 규모의 데이터는 천문학, 트위터, 유투브 데이터도 아닌, 바로 유전체 데이터라고 한다. 연간 1 엑사바이트 정도의 데이터가 생산될 천문학, 유투브와는 달리 유전체 데이터는 연간 최대 40 엑사바이트까지 생산될 수 있다는 것이다 (1 엑사바이트=10억 기가바이트).
유전체 분석 기술의 눈부신 발전에 따라서 서열 분석의 속도와 수율은 폭발적으로 증가하고 있다. 2017년 1월 일루미나가 내어놓은 노바시크 (NovaSeq)라는 새로운 유전체 분석 기기는 한 대당 이틀에 6테라바이트, 즉 60명 정도의 전장 유전체 분석(WGS)을 할 수 있을 정도로 발전했다. 굳이 따지자면 한 시간당 한 사람의 전장 유전체 분석을 할 수 있을 정도이니, 2003년 휴먼 게놈 프로젝트에서 한 명의 분석에 13년이 걸렸던 것을 떠올려보면 너무도 큰 변화다. 이런 추이를 보면, 미래에 인류가 가지게 될 유전체 데이터의 크기가 매우 방대할 것이라는 점은 어렵지 않게 짐작할 수 있다.
머니볼과 빅 데이터 의료
이렇게 데이터의 종류가 많아지고 그 크기가 커질수록, 그 데이터를 분석하기는 더욱 어려워진다. 한 사람의 환자의 건강에 대한 총체적이고 종합적인 데이터를 실시간으로 분석하고, 그 속에서 의미와 규칙, 상호 작용, 상관관계를 정확하게 찾아내고, 더 나아가 앞으로 그 데이터들이 어떻게 변화할지 정확하게 예측까지도 할 수 있다면 우리가 궁극적으로 지향하는 4P 의료를 구현할 수 있을 것이다.
이를 위해서는 복잡한 데이터 속에서 통계적인 분석을 통해 숨겨진 의미를 찾아낼 수 있는 데이터 과학자(data scientists)의 역할이 중요하다. 필자는 이러한 의료 빅 데이터를 분석하기 위해 미래 의료에서 통계학자와 데이터 과학자의 역할이 매우 크다고 생각한다. 인공지능의 도입 등 디지털 기술 발전에 따라 의사의 역할도 지금과 크게 달라질 것이며, 미래에 의사가 새롭게 맡아야 할 중요한 역할 중 하나가 바로 임상 데이터 과학자(clinical data scientist)라고 생각한다.

데이터 과학이라고 하면 일반 대중에게 가장 친숙한 사례로 미국 야구 메이저리그의 ‘머니볼(money ball)’이 빠질 수 없다. 머니볼은 경제학 분야 저널리스트인 마이클 루이스가 미국 메이저리그의 야구단, 오클랜드 애슬레틱스(Oakland Athletics)의 실화를 다룬 야구에 관한 책이다. 책은 2003년에 출판되어 세계적인 베스트셀러가 되었고, 2011년에는 브래드 피트 주연의 동명의 영화로 만들어지기도 했다.
그런데 이 책은 단순히 야구 이야기가 아니라, 데이터와 통계를 바탕으로 야구라는 종목을 이해하는 방식을 혁신적으로 바꾸었던 이야기를 다루고 있다. 2000년대 초반 가난한 야구단인 오클랜드 어슬레틱스가 천문학적인 돈을 투자하는 뉴욕 양키즈 같은 구단을 이기고, 야구 역사에 남을 성적을 냈던 비결이 바로 데이터와 통계적 분석에 기반한 전략이었다.
사실 ‘기록의 스포츠’라고 불리는 야구만큼 경기의 모든 부분이 정량적인 데이터로 기록되는 종목도 없다. 선수들이 경기하는 일거수일투족이 숫자와 기록으로 남는다. 매 경기마다 쏟아져 나오는 이 데이터를 통해서 통계적인 분석이 가능해진다. 이렇게 머니볼의 핵심은 기존 야구계에 코치나 스카우터의 개인적 경험과 통찰에 의존하던 방식을 데이터와 통계적 분석을 통해 깨뜨리고, 더 나아가 선수의 역량 중 실제로 승리에 기여하는 숨겨진 요인을 파악했다는 것이다.
오클랜드 어슬레틱스에서 이 데이터 분석을 진행한 사람은 당시 하버드 경제학과를 갓 졸업한 폴 디포디스타(Paul DePodesta)라는 신참내기였다. 폴 디포디스타는 야구 선수로서 경험이 전혀 없었지만, 데이터 분석을 통해 당시 야구계에서는 무시되던 출루율, 장타율 등이 승리에 가장 영향을 크게 미친다는 것을 발견했다. 이는 처음에 야구 전문가들로부터 책상물림의 이론일 뿐이라고 비웃음을 샀지만, 결국 오클랜드의 정규리그 20연승 등의 대기록으로 이어졌다. 그리고 시간이 흐르면서 모든 메이저리그 구단들이 이러한 데이터 분석을 이용하게 되었다.
그러던 지난 2015년, 디지털 헬스케어의 구루 에릭 토폴(Eric Topol) 박사가 수장으로 있는 스크립스 중개과학연구소(Scripps Translational Science Institute)로부터 흥미로운 소식이 전해졌다. 바로 머니볼의 주역 폴 디포디스타를 생물정보학 분야의 교수로 전격 임용한다는 것이었다. 폴 디포디스타는 “야구, 금융, 운송 및 소매업 분야에서 사람들은 데이터의 힘을 이용해서 더 나은 의사결정을 내리고 있다. 의료는 이 기회를 탐색하기 시작한 시점이지만, 다른 분야에서도 존재했던 동일한 장벽에 직면하고 있다”라고 언급했다.
야구의 문외한이었던 폴 디포디스타는 데이터 분석에 기반한 새로운 통찰을 이끌어내어 야구의 역사를 바꿔놓았다. 그 방법론은 처음에 야구계에서 격렬한 반대와 조롱에 시달렸지만, 이제는 모든 구단이 채택하고 있는 너무도 일반화된 방법이 되어버렸다. 이제 의료라는 새로운 분야에서 이 데이터 과학자가 또 한번 돌풍을 일으키지는 지켜봐야 할 일이다. 하지만 이러한 사례는 방대한 데이터에 기반한 미래 의료에서 데이터 분석이 가지는 중요성을 상징적으로 보여주는 일화라고 해도 과언이 아닐 것이다.
- 관련 포스팅: 데이터 중심 의학과 ‘머니볼’
 에릭 토폴 박사님과 폴 디포디스타 (출처: Scripps Health)
에릭 토폴 박사님과 폴 디포디스타 (출처: Scripps Health)
대형 마트에서 엿보는 미래 의료
미래에 빅 데이터 의료가 어떻게 구현되며, 어떠한 방식으로 환자들에게 가치를 줄 수 있을지를 구체적으로 그려보기란 사실 쉽지 않다. 빅 데이터 의료가 구현될 전체 그림 중에 일부 요소와 관련해서는 지금도 선도적인 사례들이 제시되고 있으며 이 중 대표적인 것들은 앞으로 살펴보게 될 것이다. 하지만 아직까지 빅 데이터 의료를 구현하고 일선 의료 현장에서 환자에게 적용하고 있는 사례는 드물다.
그도 그럴 것이, 아직 디지털 의료의 1단계와 2단계가 완전하게 구현되지 않은 상황에서, 데이터의 분석과 예측 모델을 먼저 만들 수는 없는 일이다. 1층과 2층을 먼저 만들어야 3층도 지을 수 있으니까 말이다. 하지만 폴 디포디스타의 말처럼 의료 외에 야구, 금융, 운송, 소매업 등 다른 분야에서는 이미 데이터 분석을 기반으로 고객의 취향, 행동이나 미래의 트렌드 변화를 예측하고 있으며, 기업의 의사결정에 활용되고 있기도 하다.
만약 금융, 운송, 소매업 등의 분야에서 방대한 데이터를 기반으로 고객의 취향, 행동, 변화 등을 예측할 수 있다면, 이와 비슷한 원리로 환자의 질병이나 건강 변화를 예측하고 예방할 수 있지 않을까? 소매업 등의 분야에서 현재 빅 데이터가 어떻게 활용되는지를 본다면 미래 의료에 대한 힌트를 얻을 수 있을지도 모른다.
이를 위한 좋은 사례를 미국의 대형 마트 체인점인 타겟(Target)에서 찾아볼 수 있다. 타겟은 고객의 쇼핑 패턴을 기반으로 고객의 취향이나, 라이프스타일 및 결혼, 이사 등 삶의 중요한 변화를 겪고 있음을 파악하고, 심지어는 임신 여부와 출산 예정일까지도 성공적으로 예측하고 있기 때문이다.
타겟의 쇼핑 패턴 분석의 위력을 알려주는 단적인 사례가 있다. 어느 날 타겟의 미네소타 매장에 화가 머리 끝까지 난 남자 고객이 찾아와 지점장에게 항의를 했다. 고등학생인 자기 딸에게 임산부용 옷, 유아복, 유아용 침대를 사라는 할인 쿠폰을 보냈다는 이유에서였다. “이제 고등학생인 내 딸에게 이런 광고를 보내는 게 말이 됩니까? 고등학생한테 임신하라고 부추기는 겁니까?”
해당 관리자는 그 남자에게 연신 사과했으며, 며칠 뒤에도 고객의 집으로 사과 전화까지 걸었다. 그랬더니 그 고객은, “나도 모르는 사이에 집에 일이 좀 있더군요. 내 딸의 출산 예정일이 8월이랍니다. 정말 미안합니다.” 부모조차 몰랐던 딸의 임신을 대형 마트가 빅데이터 기반의 구매형태 분석을 통해 먼저 알았던 것이다.
 쇼핑 패턴을 보면 건강 상태를 알 수 있다? (출처)
쇼핑 패턴을 보면 건강 상태를 알 수 있다? (출처)
타겟은 어떻게 고객의 임신을 예측했나
대형 마트는 고객들이 더 편하게 쇼핑할 수 있도록 하기 위해, 혹은 지출을 장려하기 위해 많은 과학적, 심리학적 기법을 동원한다. 특히 고객의 구매 습관을 면밀하게 분석하면, 고객이 어떠한 취향을 가지고 있고, 어떠한 삶의 경험을 단계를 지나고 있으며, 이를 통해 어떻게 구매를 유도할 수 있을지에 대한 정보까지도 얻을 수 있다.
뉴욕 타임즈의 기자인 찰스 두히그(Charles Duhigg)의 기사와 저서 ‘습관의 힘’에는 이 대형 마트가 고객의 각종 구매 패턴 데이터를 활용해서 고객의 건강 상태에 대한 통찰까지도 이끌어낼 수 있음을 보여준다. 이는 마치 셜록 홈즈가 의뢰인의 구두에 묻은 흙, 모자에 묻은 머리카락, 한쪽 소매만 비에 젖은 것과 같은 사소한 정보들을 혼합하여 놀라운 추리를 해내는 것과 비슷하다.
몇 가지 구체적인 예를 들어보자. 어떤 고객이 타겟에서 수건, 시트, 은그릇과 냄비, 저녁 식사용 냉동 식품을 산다면, 새집을 장만했거나 이혼했을 가능성이 높다. 벌레 퇴치제, 아동용 속옷, 손전등과 배터리, 여성용 잡지, 와인을 샀다는 것은 아이들의 여름 캠프를 앞두고 엄마가 서둘러 준비했다는 뜻이 된다.
만약 당신이 신용카드로 일주일에 한 번, 주말 저녁 6시 30분쯤에 아이스바 한 박스를 구입하고, 7월과 10월에 대형 쓰레기 봉투를 구입한다면, 타겟은 당신에게 어린 자녀가 있어 퇴근길에 식료품을 사는 경향이 있으며, 여름에는 깎을 잔디밭과 가을이면 낙엽이 떨어지는 나무가 있다고 추정할 수 있다.
특히 타겟의 데이터 과학자들은 ‘삶에서 중요한 사건을 겪은 후에는 소비자의 구매 습관이 바뀔 가능성이 크다’는 사실을 파악했다. 예를 들어, 막 결혼한 사람은 새로운 유형의 커피를 구매할 가능성이 높으며, 새 집으로 이사한 사람은 다른 종류의 시리얼을 구매하는 경향이 있다. 중요한 사건을 겪으며 소비자는 자신도 모르는 사이에 구매 패턴이 바뀌는 것이다.
이러한 주요 사건 중, 특히 예측이 용이한 것이 바로 앞서 언급한 임신과 출산이다. 예컨대, 여성 고객은 임신 4개월에 들어서면 향이 없는 로션을 다량으로 구입하는 경향을 보인다. 또한 임신 후 20주가 되면 많은 임산부가 칼륨, 마그네슘, 아연 등의 영양제를 구입했다. 따라서 향이 없는 비누나 손세정제를 다량으로 구입한 고객은 몇 주 이후에 마그네슘과 아연이 함유된 영양제를 구입할 가능성이 높고, 몇 개월 후에는 출산을 해서 유아복, 유아용 침대가 필요하게 될 것이다.
이러한 다양한 종류의 데이터를 조합하고 분석한 결과, 타겟은 ‘임신 예측 점수’라는 모델을 만들어, 임산부의 출산 예정일까지도 비교적 정확하게 예측할 수 있게 되었다.
- 애틀랜타에 사는 23세의 여성이 코코아 버터 로션, 기저귀 가방으로 사용될 수 있는 큰 가방, 아연과 마그네슘 영양제, 하늘색 깔개를 샀다면? 그녀는 임산부일 가능성이 87%이며 예정일은 8월 말이다.
- 브루클린에 사는 35세의 여성이 작은 수건 다섯 팩과 민감성 피부를 위한 세탁용 세제, 헐렁한 바지, DHA가 함유된 비타민, 수분 크림을 샀다면? 그녀는 임산부일 가능성이 96%이며 예정일은 5월 초이다.
- 샌프란시스코에 사는 39세의 여성이 250달러짜리 유모차만 샀다면? 그녀는 임산부일 확률이 낮으며, 아마도 친구에서 선물하기 위해서 유모차를 샀을 것이다.

타겟은 쇼핑 패턴을 분석하여 고객의 생활 습관, 건강 등을 파악한다 (출처: 뉴욕타임즈)
타겟 이외에도, 이렇게 구매 목록 등 사회경제적 데이터를 기반으로 질병이나 의료와 관련한 예측에 성공한 경우는 적지 않았다. 피츠버그 대학병원(UPMC)에서는 환자들의 쇼핑 특성 등 여러 데이터를 이용하여 응급실 시설 이용 가능성을 예측했다. 이 연구에서 밝혀진 바로는 통신 판매와 인터넷 쇼핑을 즐겨하는 사람들이 응급 서비스를 이용할 가능성도 높았다.
그런가 하면, 캐롤라이나스 헬스 시스템(Carolinas Health System)은 200만 명의 신용 카드 데이터를 기반으로 패스트푸드, 담배, 술, 의약품 리필 여부 등의 파악을 통해 과체중, 당뇨병, 천식, 우울증 등의 질병에 대한 고위험군을 분류하고 응급실 시설 이용 가능성을 예측하기도 했다.
이렇게 쇼핑 패턴, 구매 목록, 신용 카드 사용 패턴 등의 데이터를 조합하고 분석하여 고객의 특징을 유추해내는 과정은 미래 의료에 대해서도 상징하는 바가 적지 않다. 의료와 직접적인 관계가 없는 대형 마트 구매 목록만으로도 임신 여부를 예측하고 출산 예정일까지도 계산할 수 있다면, 의료 데이터들을 통합하여 분석한다면 질병이나 건강에 대해 더 결정적이고 중요한 통찰을 얻을 수 있지 않을까? 질병 증상이 나타나기도 전에 극초기 단계에서 질병을 진단하거나, 보다 나은 치료법을 찾고, 만성질환 환자의 동태가 급격히 나빠지는 것을 미연에 방지할 수도 있을 것이다.
한 가지를 더 첨언하자면, 이러한 사회경제적 데이터의 활용은 사생활 침해 소지가 있다. 개별적인 구매 상품의 목록이 사생활을 침해한다고는 보기 어려울 수 있다. 내가 마그네슘 영양제를 먹는다는 사실 자체가 프라이버시로 보기에는 애매하기 때문이다. 하지만 여러 평범한 데이터가 통합되어서, 임신 등 민감할 수도 있는 숨겨진 의미가 파악된다면 이는 문제가 달라진다. 그렇기 때문에 이 데이터를 누가 소유하며, 분석할 권한을 누구에게 부여할 것인지도 중요하다. 사생활 침해 및 데이터 보안은 별도로 큰 이슈이기 때문에 나중에 별도로 논의하기로 한다.
빅 데이터를 천식 예측에 응용한다면
빅 데이터 의료는 여러 질병 중에도 특히 만성 질환 환자들의 질병 관리에 효용이 클 것이다. 만성 질환 환자들은 질병을 완치한다는 개념보다는 평생 동안 그 질병을 관리하면서 살아가야 한다. 평소에 질병을 잘 관리하고 있다고 할지라도, 어떠한 요인으로 질병이 언제든 악화될 수도 있다는 걱정을 평생 안고 살아가야 한다. 그러한 질병이 악화되는 것이 급작스럽고, 그 영향이 이 클수록 두려움은 커진다. 당뇨병 환자에게 저혈당 쇼크가 오거나, 뇌전증(간질) 환자에게는 간질 발작이, 심장 질환 환자에게 심정지, 천식 환자에게는 천식 발작과 같은 경우가 그러하다.
하지만 만성질환 환자들이 끊임 없이 내어놓는 데이터와 더 나아가 주변 환경의 데이터를 통합하고 실시간으로 분석을 할 수 있다면 이러한 급성 발작까지도 미리 예측할 수 있지 않을까? 예를 들어, “1시간 뒤에 심장 마비가 올 가능성이 95%이니 주변 응급실로 찾아가세요”와 같은 방식으로 말이다. 이러한 예측이 어쩌면 쇼핑 데이터를 바탕으로 출산 예정일을 예측하는 것보다 더 쉬울지도 모른다.
좀 더 구체적으로 천식 환자에게 빅 데이터 분석을 적용하는 미래를 떠올려 보자. 천식(asthma)은 기도의 폐쇄, 기도 과민성 증가를 특징으로 하는 만성 호흡기 질환이다. 천식의 대표적인 증상은 기침, 천명(wheezing), 호흡 곤란 등이다. 천명은 쌕쌕거리는 숨소리를 의미하는데, 숨을 쉴 때 좁아진 기관지를 따라 통과할 때 드리는 호흡음이다.
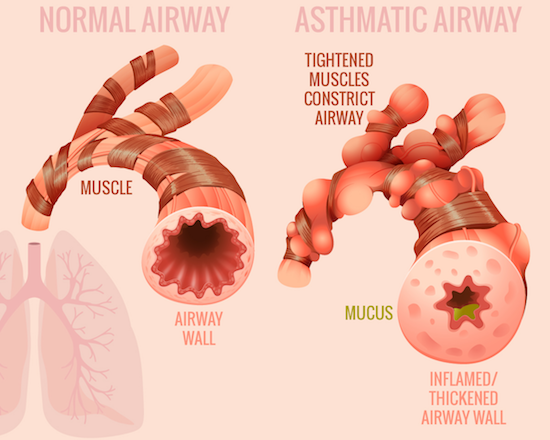 정상인과 천식 환자의 기도
정상인과 천식 환자의 기도
아직 정확한 발병 기전은 밝혀지지 않았으나, 유전적인 요인과 환경적인 요인이 모두 작용하여 나타난다. 특히 환경적인 원인은 워낙 다양해서 집먼지 진드기, 꽃가루, 동물 털, 비듬, 바퀴벌레와 같은 알레르기 유발 물질, 차가운 공기 노출, 음식, 운동 등 신체적 활동, 황사, 미세먼지와 같은 대기 오염, 스트레스 등이 포함된다. 특히, 알레르기 유발 항원에 노출되면 기관지 수축, 기관지 부종으로 호흡 곤란을 동반하는 천식 발작(asthma attacks)이 발생하며, 심할 경우에는 생명을 위협할 수 있다.
천식환자들은 증상을 완화시키기 위해서는 경구제나 L자 형태의 흡입기(inhaler)를 사용하기도 한다. 영화 등의 매체에서도 가끔 등장하기도 하는 흡입기는 기도를 확장시켜 호흡을 원활하게 해주는 역할을 한다. 영화에서 주인공이나 조연이 천식 환자인데, 급박한 상황에서 흡입기를 잊고 나와서 호흡에 곤란을 겪는 장면이 기억나기도 할 것이다.

그렇다면 천식 환자들의 천식 발작을 사전에 미리 예측할 수는 없을까? 앞서 언급했듯이 천식에는 환자의 유전적 요인, 운동 등 후천적 요인, 알레르기 유발 물질이나 대기 오염 등 환경적 요인, 복약 상태 등의 다양한 인자가 관여하며, 환자들마다 개별 요인이 발병에 미치는 영향은 다를 수 있다. 만약 환자들마다 천식 발작의 발병과 관련된 다양한 요인들의 데이터를 지속적으로 측정, 통합, 분석할 수 있다면 천식 발작이 일어나기 이전에 그 가능성을 예측해볼 수도 있을 것이다.
실제로 천식 발작과 관련된 대부분의 데이터들은 이미 기술적으로 측정 가능하다.
- 유전적 요인: 개인 유전 정보 분석을 통해서 천식의 발병과 관련한 유전적 위험도를 분석할 수 있다.
- 환자의 신체 활동 및 상태: 웨어러블 기기나 스마트폰 앱, 센서를 활용하여 활력 징후(vital sign)와 활동량을 분석할 수 있고, 최근의 수면 상태, 알콜 섭취, 영양 상태, 복약 순응도, 스트레스 등을 측정할 수 있다.
- 환경적 요인: 사물인터넷 센서를 활용하여 집 안의 온도, 습도, 이산화탄소, 미세먼지, 오염물질 등의 공기의 질의 상태와 변화를 확인할 수 있다. 또한 스마트 흡입기(smart inhaler)의 사용은 GPS를 활용하여 개별 환자가 과거 언제, 어느 장소에서 천식 발작이 일어났는지, 혹은 인구 수준에서 현재 어느 지역에서 환자들이 흡입기를 많이 사용하는지의 데이터도 축적하여 환경적인 요인이 나쁜 위험 지역을 직간접적으로 파악할 수 있다.
이 모든 환자 유래의 의료 데이터들은 앞서 설명한 스마트폰 어플리케이션, 웨어러블 디바이스, 개인 유전 정보를 통해서 모두 측정 가능하다. 실내 공기의 질 역시 사물 인터넷 기기인 어웨어(Awair), 엘러센스(AlerSense) 등을 통해서 쉽게 측정 가능하다.
 비트파인더의 공기 질 측정기, 어웨어
비트파인더의 공기 질 측정기, 어웨어
단순히 약물을 주입하는 과거의 흡입기에, 흡입기를 사용한 시간, 빈도, 패턴, 장소 등의 데이터를 함께 측정할 수 있는 스마트 흡입기의 효용 역시 점차 증명되고 있다. 스마트 흡입기를 개발하는 미국의 프로펠러 헬스(Propeller Health)는 이러한 기기가 천식 환자의 질병 관리에 효과가 있음을 임상 연구를 통해 증명한 바 있다.
495명의 천식 환자를 대상으로 한 연구에서 실험군의 경우에는 이 흡입기를 언제 어떻게 사용하였는지에 대한 피드백을 제공하였고, 대조군의 경우에는 같은 기기를 사용하게 하였으나 아무런 피드백을 주지 않았다. 임상 연구를 1년 간 시행한 이후, 피드백을 받은 환자들의 경우에는 대조군에 비해 흡입기의 사용이 크게 감소했으며, 흡입기를 사용하지 않아도 되는 날짜의 비율이 더 높았다. 실험군 중의 59%의 환자가 이 스마트 흡입기를 활용해서 자신의 새로운 천식 발작 요인을 알게 되었다고 응답하기도 했다.
 프로펠러 헬스의 스마트 흡입기
프로펠러 헬스의 스마트 흡입기
이러한 연구에서 한 단계 더 나아가 스마트 흡입기뿐만 아니라 유전적 요인, 활력 징후, 활동량, 공기의 질 등의 요인이 측정되어 지속적으로 클라우드에 전송 및 저장되며, 이를 인공지능으로 실시간 분석을 통해 피드백을 제공하고, 천식 발작을 예측할 수 있다고 상상해보자. ‘모든 것이 연결되는’ 사물 인터넷 기기들을 통해 실내 공기의 온도, 습도 등을 자동으로 조절하고, 공기 청정기를 작동시키며, 천식 발작을 예측하여 환자와 보호자에게 미리 경고 및 대처법을 알려준다면 천식 환자 질병 관리에 더욱 큰 효용을 제공할 수 있을 것이다.
2016년 IBM 왓슨과 다국적 제약사 테바(Teva Pharmaceuticals)의 만성질환 관리를 위한 파트너십 체결은 이러한 구도의 초기 모습을 보여주기도 한다. 테바는 전통적으로 호흡기 질환 관련 신약을 개발해온 제약회사이며, 2015년에는 천식 및 만성 폐쇄성 폐질환(COPD) 환자용 스마트 흡입기와 데이터를 분석하는 플랫폼을 보유한 겍코 헬스 이노베이션(Gecko Health Innovation)이라는 회사를 인수하기도 했다. 이러한 인수 및 파트너십은 스마트 흡입기의 사용에서 나온 환자의 데이터를 IBM 왓슨 헬스 클라우드에 저장하고, 인공지능으로 분석하려는 모델이 만들어지고 있음을 보여주고 있다.
두 가지 데이터 분석법: 사람, 그리고 인공지능
이번에는 의료를 포함한 많은 분야들의 데이터가 폭발적으로 증가하고 있으며, 그러한 빅 데이터를 분석하고 숨은 의미를 찾기 위해서는 데이터 과학이 필요함을 알아보았다. 소위 ‘빅 데이터 의료’를 구현하기 위한 제반 여건들이 아직은 모두 갖추어지지는 않았기 때문에 미래 의료에 데이터가 어떠한 방식으로 활용될지 예측하기란 쉽지 않다. 하지만 타겟과 같은 대형 마트가 고객의 구매 데이터의 패턴을 분석하여 고객의 상황을 예상하고, 건강 상태까지 예측하는 사례에서 미래 의료의 방향 대한 힌트를 얻을 수 있었다.
이제부터는 이 의료 데이터를 분석하는 방식에 대해서 좀 더 자세하게 알아보려고 한다. 데이터를 분석하는 방법에는 분석의 주체에 따라서 크게 두 가지로 나눌 수 있을 것이다. 첫 번째는 사람이 분석하는 것이다. 그리고 두 번째는 바로 기계의 두뇌, 즉 인공지능의 힘을 빌리는 것이다.
머니볼과 타겟의 사례에서는 데이터 과학자들이 야구 선수들의 데이터와 구매 패턴을 분석했다. 디지털 기술이 발전하면서 이렇게 사람이 분석하는 경우에도 더욱 다양한 방식과 새로운 기법을 활용할 수 있게 되었다. 데이터 과학자들이 갖출 수 있는 무기들은 앞으로 더욱 늘어날 것이다.
하지만 우리는 결국 인공지능과 손을 잡지 않을 수 없을 것이다. 끝없이 쏟아지는 방대한 분량의 데이터를 실시간으로 분석하는 것은 인간의 힘만으로는 이미 불가능한 상황으로 진입하고 있다. 데이터를 기반으로 예측, 예방, 정밀 의료를 구현하기 위해서 결국 의료는 기계학습과 인공지능을 더욱 적극적으로 받아들이는 것 외에 대안을 떠올리기 어렵다. 인공지능의 의료 분야 적용은 큰 관심사가 되었으며, 다양한 분야에서 이미 그 활용이 시작되고 있다.
중요한 것은 사람과 인공지능, 이 두 가지의 방식이 서로 대결 구도에 있는 것은 아니라는 점이다. 앞으로 강조하겠지만, 우리에게는 이 두 가지 방식이 모두 필요하며, 서로 공존과 협력을 통해 시너지 효과를 발생시킬 수 있다고 나는 믿는다. 그러한 미래를 만들어가는 것 자체가 우리의 책임이기도 하다.
사람의 분석과 인공지능의 분석. 이 두 가지 방법은 이미 많은 의료 분야에서 실제 사례들을 만들어내고 있다. 이제부터는 이 두 가지 방식이 현재 어떻게 구현되고 있으며, 앞으로 어떻게 발전할 것인지에 관해 차례로 설명해보도록 하겠다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.