

개인 유전 정보 분석
디지털 의료의 구현을 위한 데이터 중에서 빼놓을 수 없는 요소가 바로 개인 유전 정보이다. 앞서 인간 자체가 데이터에 관한 것이며, 생명을 유지하고 살아가는 것 자체가 끊임없이 데이터를 만들어내는 과정이라는 것을 강조한 바 있다. 더 나아가 인간은 태어날 때부터 부모에게서 물려받은 데이터를 가지고 태어난다. 바로 유전 정보이다.

디지털 기술의 발전에 따라서 유전 정보 분석을 위한 시간과 비용은 급격하게 줄어들어, 바야흐로 개인 유전 정보 분석의 시대가 도래하고 있다. 사실 필자는 외부 강의 등에서 개인 유전 정보의 중요성을 설명하기 전에 청중에게 항상 “혹시 자신의 유전 정보를 분석해보신 분이 계신가요?” 하고 질문을 던진다. 이 질문에 대해서는 국내에서는 아직 대학, 기업, 연구소, 병원, 의사 연수 강좌 할 것 없이 손을 드시는 분들이 거의 없는 실정이다.
이렇게 최근까지도 한국에서는 여러 이유 때문에 자신의 유전정보를 분석하고, 소유하며, 이를 활용하는 개인들이 극히 소수에 불과하다. 하지만 미국을 비롯한 해외에서는 이미 수백만 명의 개인들이 자신의 유전정보를 분석했으며, 그 수는 지금도 폭발적으로 증가하고 있다. 이런 유전 데이터를 분석하고, 저장하며, 활용하는 것 하나하나가 모두 새로운 사업과 서비스가 되어 우리의 일상 생활에서도 변화를 만들어 낼 것이다.
사실 유전 정보 분석은 그 자체로도 매우 방대한 분야이다. 분석 방법도 다양하며, 활용 범위도 비만 관리, 조상 계열 분석에서 질병 예측, 약물 민감도 예측, 유전 질병 진단이나, 암 맞춤 치료에 이르기까지 매우 넓다. 이 모든 분야를 모두 다루기는 어려우므로, 이번에는 디지털 의료의 구현을 위한 ‘데이터 측정’이라는 맥락 하에 개인 유전 정보 분석이라는 한정된 범위를 위주로 설명해보려 한다.
“디지털 의료는 어떻게 구현되는가” 시리즈 보기
- 변혁의 쓰나미 앞에서
- 누가 디지털 의료를 이끄는가
- 데이터, 데이터, 데이터!
- 4P 의료의 실현
- 스마트폰
- 이제 스마트폰이 당신을 진찰한다
- 웨어러블 디바이스
- 개인 유전 정보 분석의 모든 것!
- 환자 유래의 의료 데이터 (PGHD)
- 헬스케어 데이터의 통합
- 헬스케어 데이터 플랫폼: 애플 & 발리딕
- 빅 데이터 의료
- 원격 환자 모니터링
- 원격진료
- 인공지능
디지털 기술과 유전 정보
개인들의 유전정보를 분석해주는 기업들은 이미 세계적으로 여러 곳이 존재한다. 대표적인 개인 유전정보 분석 회사로는 실리콘밸리의 23andMe, 샌디에고의 패쓰웨이 지노믹스(Pathway Genomics) 등이나, 가족계획을 세울 때 유전 질환의 발병 가능성이 있는지를 알아보는 카운실(Counsyl) 등을 꼽을 수 있다. 한국에는 테라젠이텍스, DNA링크 등의 상장사 및 제노플랜, 3billion 등의 스타트업이 개인 유전 정보 분석에 기반한 서비스를 제공하고 있다.
‘유전정보 분석’ 이라고 하면 언뜻 순수한 생명과학 분야 기업일 것 같지만, 이런 기업들은 거대 IT 기업과의 활발한 협력을 통해 성장하고 있다. 특히 23andMe 는 아예 구글의 창업자 세르게이 브린의 아내 (지금은 이혼했다)인 앤 워짓스키가 설립하면서 시작했고, 세르게이 브린 개인과 알파벳(구글)의 벤처투자사인 구글 벤처스로부터 막대한 투자를 받았다. 패쓰웨이 지노믹스는 IBM 의 투자를 받고 인공지능 왓슨과 유전정보가 결합된 서비스를 개발하고 있으며, 제노플랜은 손정의 회장의 소프트뱅크벤처스로부터 투자를 유치한 바 있다.
사실 유전 정보는 디지털 기술과 밀접한 관련이 있다. 무엇보다 유전 정보, 즉 DNA 서열 자체가 결국 A, T, G, C 라는 네 가지의 문자로 표현할 수 있는 일종의 디지털 데이터이다. 특히 인간의 전체 DNA 서열은 총 30억 개에 달하는 A, T, G, C의 조합으로 이루어진다. 이 방대한 서열 데이터를 읽어내고, 활용하기 위해서는 막대한 계산과 통계적인 분석, 저장 공간이 필요하다.
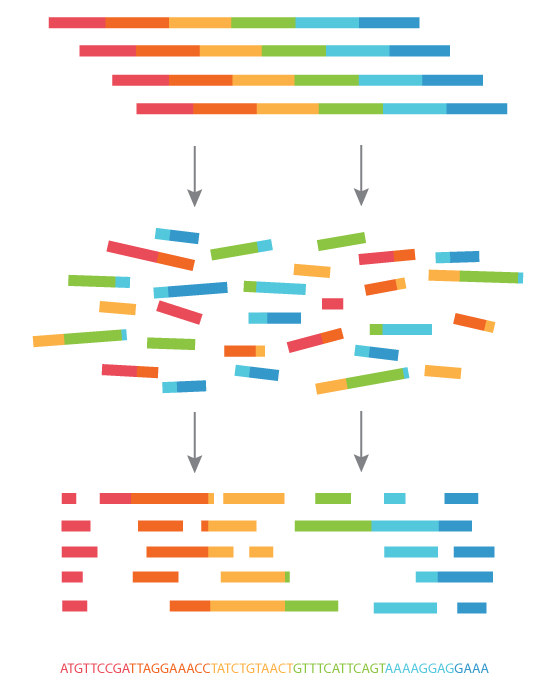 유전체 전체 서열을 한 번에 읽지는 못하고,
유전체 전체 서열을 한 번에 읽지는 못하고,
조각내어서 따로 읽은 다음 퍼즐 맞추듯 배열하여 전체 서열을 완성해나간다 (출처).
일단 30억 개에 달하는 긴 서열을 한 번에 읽지 못하므로, 일단 수많은 조각으로 만들어서 따로 서열을 분석한 다음, 그 조각들을 다시 퍼즐 맞추듯 앞 뒤를 정확하게 배열하여 전체 서열을 완성하는 과정이 필요하다. 퍼즐 맞추기를 할 때 밑그림이 있는 경우에는 계산이 그나마 수월하지만 (인간 등 많이 계산하는 종에 대해서는 미리 만들어 놓은 표준 밑그림이 있다), 밑그림이 없는 경우에는 퍼즐의 조합이 많아지므로 계산 수도 훨씬 많다.
또한 각 서열을 한 번씩만 읽어내는 것보다 정확도를 높이기 위해 다양한 조각으로 여러 번 반복해서 읽어낸다. 조각들이 각 서열에 반복해서 쌓여갈수록 서열을 더 정확하게 읽을 수 있을 것이다 (이렇게 얼마나 반복해서 서열을 분석했는지를 ‘커버리지’라고 해서 실제로 분석 퀄리티의 중요한 판단 기준이 된다). 이렇게 유전정보라는 전체 퍼즐을 완성하기 위한 조각의 종류와 갯수, 퍼즐의 맞추는 과정에서 많은 계산과 큰 저장 공간이 필요하다.
더 나아가 서열 데이터를 읽어낸 후 각 서열에 대한 통계적인 수치나, 분석 결과 등을 파일에 추가할 수도 있다. 이렇게 되면 한 사람의 유전체 정보를 저장한 파일의 크기는 분석 방법에 따라 수십 기가바이트에서 테라바이트 단위까지로도 커질 수 있다. 나중에 살펴보겠지만, 한 연구에 따르면 머지 않아 인류가 가지게 될 가장 큰 데이터는 트위터와 같은 SNS 데이터도, 유투브 영상도, 천문학 데이터도 아닌 바로 유전 정보가 될 것이라고 한다. 그야말로 빅 데이터인 것이다.
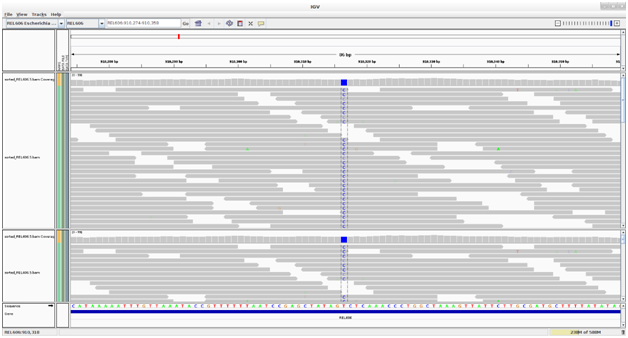 실제로 ‘퍼즐 맞추기’ 를 완성하면 이와 같이 나타난다.
실제로 ‘퍼즐 맞추기’ 를 완성하면 이와 같이 나타난다.
각각의 서열마다 ‘퍼즐’이 여러겹 겹쳐져서 읽은 것을 알 수 있다 (출처).
개인 유전정보 분석의 시대
IT 기술의 발전은 일반 개인들도 유전정보를 쉽게 분석해서 소유할 수 있는 시대를 앞당기고 있다. 휴먼 게놈 프로젝트가 이뤄지던 시기와 현재를 비교해보면 그 차이가 너무도 극명하다. 인류 최초로 한 사람의 모든 유전 정보의 서열을 분석했던 것이 바로 휴먼 게놈 프로젝트이다. 이 프로젝트는 2003년에 마무리되었는데, 이 한 사람의 유전 정보 분석을 위해서 27억 달러라는 막대한 비용과 13년이라는 긴 세월이 걸렸다. (사실 이마저도 예상보다 일찍 끝난 것이다)
하지만 지금 똑같은 일을 하기 위해서는 시간과 비용이 얼마나 필요할까? 단지 30시간과 1,000달러 정도만 필요할 뿐이다[1, 2, 3, 4]. 디지털 기술의 발전에 따라서 유전체 분석에 들어가는 시간과 비용이 문자 그대로 ‘기하급수적’으로 줄어든 것이다. 앞서 IT 기술이 기하급수적으로 발전한다는 무어의 법칙의 위력을 강조한 바 있다. 그런데 유전체 분석 비용의 감소 속도는 이 무어의 법칙을 능가하고 있다.
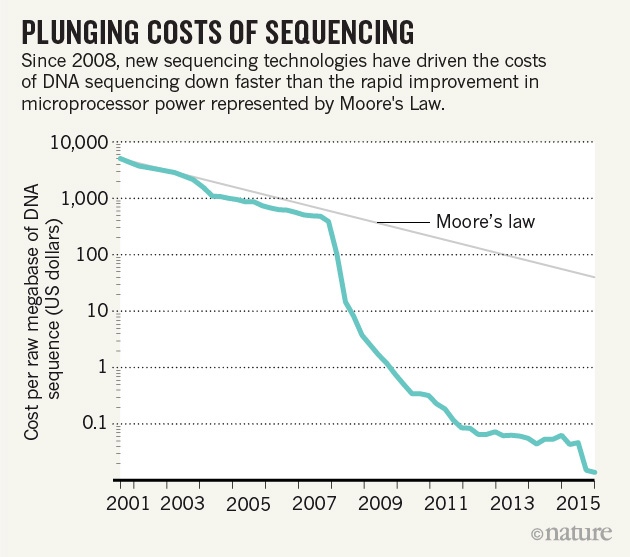
무어의 법칙보다 더 빠르게 줄어들고 있는 유전체 분석 비용 (출처: Nature)
필자가 흔히 드는 비유로, 가격이 4-5억 원하는 페라리의 슈퍼카가 동일한 비율로 가격이 내려간다면 200원 정도 하게 된다. 정말 페라리가 200원 하면 구매하지 않을 사람이 있을까? 이처럼 고가의 프리미엄 서비스라고 하더라도 가격이 어느 티핑 포인트 이하로 내려가면 일상적인 재화가 될 수 있다. 유전정보의 분석도 마찬가지일 것이다.
유전 정보 분석 분야에서는 이 티핑 포인트를 1,000 달러로 보았다. 한화로 100만원 정도에 유전 정보 분석을 할 수 있다면 개인들에게도 이런 분석이 확대될 것으로 본 것이다. 사실 ‘천달러 게놈’ 은 동명의 책이 있을 정도로 이 분야에서는 하나의 캐치프레이즈에 가깝다. 이러한 목표가 2014년 초, 일루미나(Illumina)라는 유전체 분석 기기 회사에서 하이시크엑스10 (HiSeq X Ten) 이라는 새로운 기계를 내어 놓으면서 비로소 달성되게 되었다. 이 기기는 한 해에 18,000명의 유전체 서열 분석을 할 수 있다.
더 나아가 2016년 6월의 보고에 따르면 세계 최대 유전 정보 분석 기업인 중국의 BGI 는 이 비용을 향후 200달러까지 낮추겠다고 공언했다. 이렇게 유전체 분석 기술의 혁신은 현재 진행형이다. 유전체 분석이 1,000달러, 즉 100만 원이 넘는 수준이라고 한다면 (27억 달러에 비하면 껌값이긴 하겠지만) 일반인들이 쉽게 접근하기에는 다소 부담스러울 수 있다. 하지만 BGI의 계획처럼, 가격이 20만 원까지 가격이 더 내려온다면 일반인이 체감 정도는 크게 달라질 것이다.
유전 정보 분석의 종류
앞서 유전체 분석에 대해서 설명했지만, 사실 유전 정보의 분석 방법에는 여러 가지가 있다. 한 명의 사람이 가지고 있는 유전 정보를 모두 분석할 수도 있고, 아니면 중요한 부분만, 혹은 필요한 부분만 일부분을 분석할 수도 있다. 각 방식의 분석법마다 장점과 단점이 있다.
전체 정보를 모두 분석하면 잃어버리는 정보가 적겠지만, 시간이 오래 걸리고 비용도 많이 들며, 불필요한 정보까지도 얻게 된다. 중요한 일부분만을 분석한다면 비용과 시간이 적게 소요되어 효율적이지만, 분석하지 않은 부분의 정보는 완전히 잃어버리게 된다.
한 사람이 가지고 있는 유전정보 전체를 하나의 책이라고 생각해보자. 사람마다 거의 같은 내용의 ‘책’을 가지고 있는데, 자세히 들여다보면 세부적으로는 조금씩 차이가 있다. 문장의 순서가 다르거나, 단어의 표현이 좀 다르게 씌여져 있기도 하다. 또한 단어나 문장의 순서가 서로 바뀌어 있거나, 다른 사람은 보통 없는 엉뚱한 글자가 들어가 있거나, 꼭 있어야 할 글자가 빠져 있기도 하다. 더 나아가서는 페이지가 통째로 없거나, 같은 페이지가 여러 개 있기도 하다. 가끔씩은 챕터 전체의 순서가 바뀌어 있거나, 사라져 버린 사람도 있다.
이렇게 우리가 가지고 있는 책의 다형성이 개별적인 사람을 모두 다르게 하는 근본적인 원인이다. 글자, 문장, 페이지, 챕터가 다른 것이 어떤 경우에는 겉으로 보기에 아무런 영향을 미치지 않기도 하고, 어떤 경우에는 심각한 질병을 일으키기도 한다. 유전체 분석은 이렇게 개별적인 사람이 어떠한 ‘책’을 가지고 있는지를 읽어내는 것이다. 세부적으로는 분석법을 매우 다양하게 나눌 수 있지만, 비전공자라면 아래와 같은 네 가지 정도의 분석법만 알아두면 충분할 것 같다.
- 전장 유전체 분석 (Whole Genome Sequencing, WGS): 해당 개인이 가지고 있는 유전 정보 전체를 서열분석하는 것이다. 책에 비유하자면, 1 페이지의 첫 번째 글자부터, 마지막 페이지의 마지막 글자까지 전체를 읽어낸다. 앞서 설명한, 분석에 30시간이 걸리고, 1,000달러가 든다는 것은 바로 이 WGS 에 대한 것이다. 모든 정보를 다 읽어낼 수 있지만, 다른 분석에 비해 시간과 비용 소모가 크다. 저장 공간도 많이 필요하다. 한국에서는 (분석에 필요한 시약 등을 포함하여) 150-200만원 정도에 서비스되고 있다.
- 전장 엑솜 분석 (Whole Exome Sequencing, WES): 전체 유전 정보가 아닌, 중요한 일부 부분만을 분석하는 방법이다. 이 중요한 부분이란, 단백질을 만들어내는 엑솜(Exome, 진 유전체)이라는 부분으로, 전체 유전체의 2-3% 에 해당한다. 책에 비유하자면 전체 책을 분석하는 것이 아니라, 핵심 문장만을 분석하는 것이다. 전체를 모두 분석하는 WGS에 비해서 가격도 저렴하고, 질병과 관련된 유전적 이상의 약 85%를 포괄할 수 있기 때문에 연구자들은 이 WES을 실제로 많이 사용하는 편이다. 한국에서는 80-100만원 정도에 서비스되고 있다.
- 유전자 패널 분석 (Gene Panel): 전장 엑솜 분석보다 좀 더 범위가 좁은 분석으로, 분석 목적에 맞게 미리 정해놓은 특정 유전자만 분석하는 방법이다. 주로 암 환자의 유전적 원인 규명과 치료 방법을 결정하기 위한 분석의 경우 이 방법을 많이 활용한다. (필자의 전작에서 깊이 설명한, 암 맞춤치료를 위해 유전 정보를 분석하는 미국의 파운데이션 메디슨과 같은 회사는 주로 이러한 방법을 활용한다) 책에 비유하자면 핵심 문장들 중에서, 분석 목적에 맞는 일부 문장만, 예를 들어 액션씬이나 러브씬을 표현한 문장만 추려서 읽는 것이다. 포함된 유전자의 갯수 등에 따라서 가격이 달라지지만, 보통 분석 비용은 100만 원 이하이다. (일반 환자에게 서비스 가능 여부는 관련 규제 상황에 따라 달라진다.)
- 단일 염기 다형성 분석 (Single Nucleotide Polymorphism (SNP) Genotyping): 이 분석법은 SNP (‘스닙’ 이라고 읽는다)이라는 극히 일부분의 유전 정보만을 분석한다. ‘단일 염기 다형성’ 이라는 표현처럼 DNA 서열의 1,000개 중 하나 꼴로 사람들 사이에서 서열이 다른 것이다. 예를 들어, 어떤 사람은 A 염기를 가지는데, 다른 사람은 같은 자리에 G 염기를 가질 수 있는 것이다. 모든 SNP 가 의미가 있지는 않지만 많은 경우, 질병 발병이나, 약물 민감도 등에 영향을 끼친다. 책에 비유하자면, 중요한 단어들만 분석하는 것이다. 전체 유전 정보 중에 극히 일부의 정보만 분석한다는 제약이 있지만, 분석 비용이 저렴해서 비용 대비 효용이 높은 편이다. SNP 칩을 활용하면 수십만 개의 SNP를 한 번에 검사할 수도 있다. 23andMe 등 많은 개인 유전 정보 분석 기업은 이 방법을 선호한다. 분석 비용은 대부분 20만 원 전후이다.
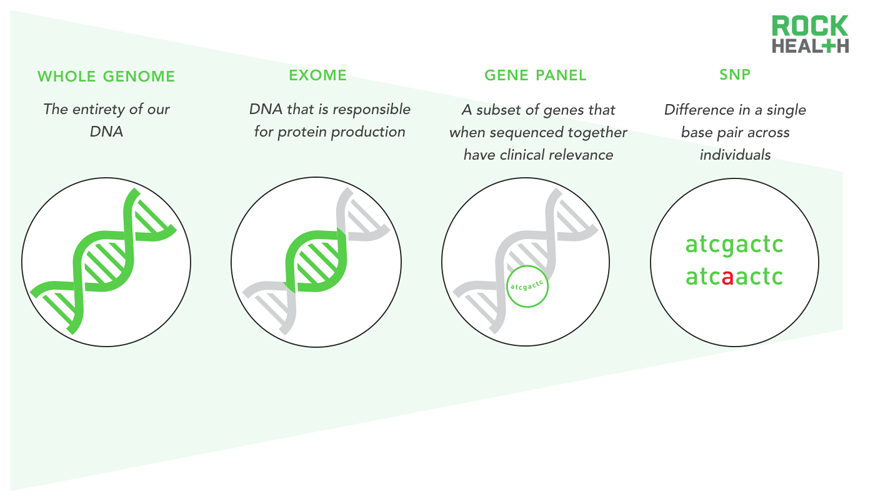 유전 정보의 다양한 분석 방법 (출처: Rock Health)
유전 정보의 다양한 분석 방법 (출처: Rock Health)
개인 유전 정보 분석의 개척자, 23andMe
개인 유전 정보 분석 서비스를 설명할 때 빼놓을 수 없는 기업이 앞서 몇번 언급한 적 있는 23andMe 라는 실리콘밸리의 스타트업이다. 당시 구글의 창업자 세르게이 브린의 아내이던 앤 워짓스키가 2006년 실리콘밸리에서 창업한 이 회사는 개인 유전 정보 분석 서비스 분야의 개척자이자 대표라고 할 수 있다.
 23andMe의 창업자, 앤 워짓스키
23andMe의 창업자, 앤 워짓스키
이 회사는 개인 고객들에게 유전 정보 분석 서비스를 제공한다. 회사명에 들어가는 숫자 23은 인간이 가지고 있는 염색체가 23쌍이라는 것에서 따온 것이다. 이 회사는 개인들에게 유전 정보의 분석을 선도적으로 서비스해왔기 때문에 많은 주목을 받았으며, 특히 규제적으로 많은 이슈들을 만들어내어 왔다.
가장 큰 특징이자 문제의 발단이 되었던 것은 23andMe가 의사나 의료기관을 거치지 않고 개인 고객에게 직접 유전 정보 분석을 제공하는 것을 고집하는 것이다. 이른바 DTC (Direct-To-Consumer) 로 불리는 고객에 대한 직접 판매 방식이다. 인터넷으로 (일반 온라인 쇼핑하듯이) 분석 키트를 주문하게 되면 택배로 집까지 배송되어 온다. 이 키트에 고객의 타액을 뱉아서 다시 우편으로 보내면 6-8주 이후에 유전정보를 분석해서 인터넷으로 확인 가능하다. 이 모든 과정에서 의사나 병원이 개입하지 않는 것이다.
이러한 DTC 방식으로 일반 사람들이 병원에 갈 필요 없이 인터넷 주문과 택배를 통해서 유전 정보 분석을 할 수 있다면, 서비스에 대한 접근성이 크게 좋아지게 된다. 하지만 질병 위험도나 약물에 관한 분석을 전문 의료인의 상담을 거치지 않고 비전문가인 고객들이 직접 받아볼 경우 부작용의 가능성도 무시할 수 없다. 예를 들어, 의료 전문 지식이 없는 일반인이 특정 질병에 대한 위험도가 높게 나왔다는 것을 과대 해석하여 극단적인 선택을 한다든지, 약물 민감도의 결과를 바탕으로 복용 중인 약의 용량을 임의로 변경할 가능성을 배제할 수 없기 때문이다.
 23andMe의 타액 수집 키트
23andMe의 타액 수집 키트
이렇게 유전정보 분석은 개인 고객에 대해서 가장 민감하며, 질병 및 건강과 직결되는 데이터이기 때문에 정확성이나 안전성 등에 대하여 규제와 밀접하게 관련이 있다. 아래에 자세히 설명하겠지만, 23andMe는 세상에 없던 서비스를 새로운 방식으로 제공한 만큼, 미국의 규제 기관인 FDA에 갑자기 서비스를 금지당하기도 하는 등 많은 우여곡절을 겪으며 사업을 진행해오고 있다. 규제에 따른 사업의 변화는 지금도 현재 진행형이라고 할 수 있다.
규제에 따른 23andMe의 사업 모델 변화 이야기는 나중에 하기로 하고, 2013년 11월 정도까지 23andMe가 제공하던 유전 정보 분석에는 어떤 것들이 있는지를 살펴보도록 하자. 23andMe가 제공했던 분석들을 설명하는 이유는 이 회사가 가장 광범위한 분석을 제공했기 때문이다. 지금도 다른 대부분의 개인 유전 정보 분석 기업들의 분석 항목은 이 23andMe 의 분석에 포함된다고 할 수 있다.
23andMe의 분석 항목
23andMe 는 아래와 같은 종류의 분석을 DTC로 소비자들에게 직접 제공했다. 2013년 11월 기준으로 이 모든 분석의 가격은 단돈 99불이었다. 가격이 저렴한 이유는 구글의 재정적인 후원이 있었기도 하지만, 분석 방법 자체가 위에서 살펴본 방법 중 가장 저렴한 SNP 분석이었기 때문이다.
아직 23andMe는 국내에 정식으로 진출한 바 없다. 하지만 필자는 2013년 하반기에 타액을 국제 운송을 통해 미국으로 보내어 23andMe의 분석을 받아본 바 있다. 당시에는 FDA에서 제재받기 이전이었기 때문에 운 좋게도 아래에 있는 모든 분석 항목에 대한 결과를 받아볼 수 있었다. (2016년 12월 현재 23andMe의 홈페이지에는 이 정보 중 극히 일부밖에 나오지 않는다) 아래와 같이 필자의 유전 정보를 함께 예시로 들어서 설명해보겠다.
- 질병 위험도 (Health Risk): 120여 가지의 다양한 질병에 대해서 발병 위험도를 계산하여 준다. 위험도가 높은 질병, 낮은 질병, 평균적인 질병으로 각각 분류하여, 병명과 나의 위험도를 평균적인 위험도와 비교하여 보여준다. 안젤리나 졸리가 BRCA 라는 유전자를 검사하여 유방암 위험도를 계산하였던 것을 떠올려보면 된다. 그녀가 23andMe의 분석을 이용하지는 않았지만, 비슷한 방식으로 질병 위험도를 계산하는 것이다. 예를 들어, 내게 위험도가 가장 높은 질병은 심장 질환인 심방세동(atrial fibrillation)이다. 위험도는 46.9%로 평균 위험도인 27.2% 에 비해서 1.73배 높다. 다음으로 위험도가 높은 질병은 제 2형 당뇨병으로 위험도는 36.5%이며 평균에 비해 1.31배 높다.
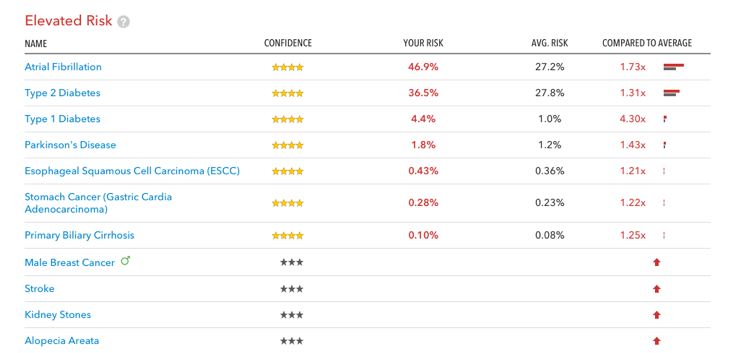 필자에게 위험도가 높은 질병 목록
필자에게 위험도가 높은 질병 목록
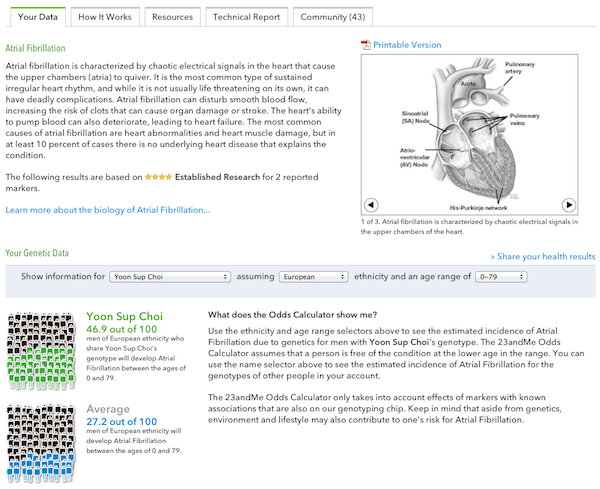 필자에게 위험도가 가장 높은 질병은 심방세동이다.
필자에게 위험도가 가장 높은 질병은 심방세동이다.
- 약물 민감도 (Drug Response): 여러 약물에 대한 민감도를 분석해준다. 커피나 술에 대해서 사람들마다 민감도가 다르듯이, 약에 대한 것 반응도 마찬가지로 개인차가 있다. 체내에서 약물을 얼마나 빨리 흡수하고, 분배하며, 대사하고, 배출하는지 등에 대한 반응이 사람마다 다르며, 많은 경우 유전적인 요인에 영향을 받는다. 즉, 같은 용량을 복용하더라도 해당 약에 민감한 사람에게는 과다복용으로 부작용이 심할 수도 있고, 반대로 덜 민감한 사람에게는 용량이 부족하여 약효가 부족할 수 있다. 예를 들어, 항응고제인 와파린(warfarin)과 같은 약의 경우 개인별로 민감도에 차이가 큰 것으로 알려져 있다. 필자는 와파린에 대한 민감도는 유전적으로 높은 편이다.
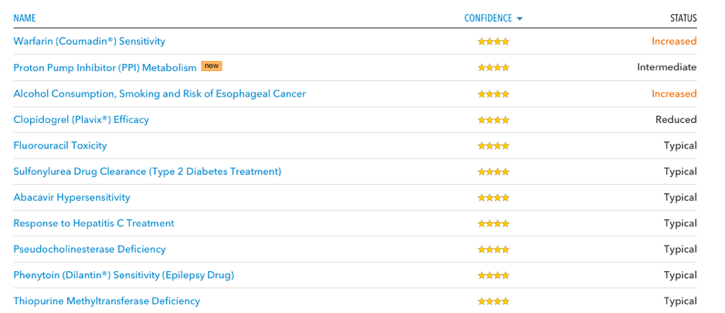
- 보인자 검사 (Inherited Conditions)
- 보인자(carrier)라고 하는 것은 유전적인 인자를 보유한 사람이라는 뜻이다. 많은 유전질환의 경우 열성 유전질환이므로, 보인자의 경우에는 겉으로 증상이 드러나지 않거나 발병하지는 않는다. 하지만 우연히도 같은 질병에 대한 보인자끼리 자녀를 가지게 되면, 자녀에게 유전 질병이 발병할 가능성이 생긴다.
- 중학교 때 완두콩을 이용해서 배웠던 ‘멘델의 유전 법칙’ 을 떠올려보자. 우성 인자를 A, 열성 인자를 a 라고 표현할 경우, 엄마와 아빠가 모두 보인자 Aa 유전형을 가지고 있다면, 자녀의 유전형은 AA, Aa, Aa, aa 의 네 가지 경우의 수가 생긴다. 이 중 25%의 확률인 열성 인자만 물려 받은 aa의 경우에는 유전 질병이 발병하게 된다. 즉, 정상인처럼 보이는 여자와 남자가 결혼하여 아이를 가졌는데, 우연히 두 사람 모두 같은 질병에 대한 보인자였다면 예기치 못하게 아기에게 유전질병이 발병하는 경우가 생기는 것이다. 이를 위해서 가족계획을 세울 때, 즉 임신 전에 이 검사를 해보면 미리 위험 여부를 알 수 있다.
- 필자의 경우, 23andMe의 분석 결과 안타깝게도(?) 혈색소증(hemochrombtosis)라는 음식을 통해 섭취한 철이 너무 많이 체내에 흡수되는 질병에 대한 보인자라는 것을 알 수 있었다. 필자는 문제가 없지만, 만약에 나중에 배우자가 우연히도 역시 혈색소증에 대한 보인자라면, 2세를 갖는 것에 대해서 고민이 필요할 것 같다.
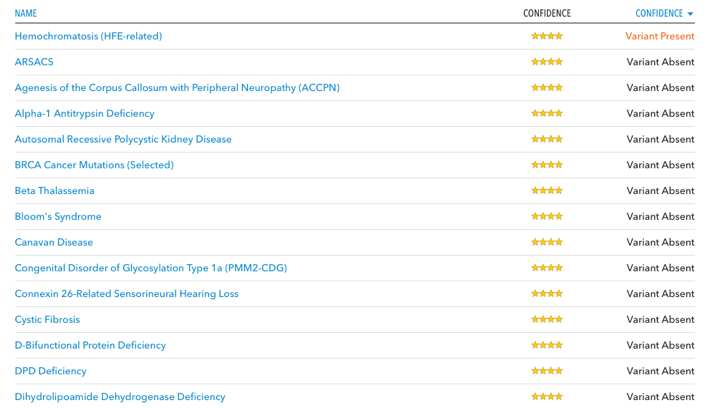
필자의 보인자 검사 결과 일부
- 웰니스 및 신체적인 특징들(Wellness): 질병이나 약물 민감도와 같은 의료적인 분석 이외에도 그리 심각하지 않은 항목들에 대한 분석도 볼 수 있다. 예를 들어, 술을 마시면 얼굴이 붉어지는지, 쓴 맛을 감지할 수 있는지, 귀지가 끈적끈적한 형태인지, 눈 색깔, 곱슬머리 여부, 대머리 가능성, 카페인에 대한 민감도, 흡연 중독 가능성 등에 대해서 분석하는 것이다. 필자의 경우, 술 마시면 얼굴이 붉어지고, 갈색 눈, 반곱슬 머리, 머리에 숱이 많은 것 등 대부분의 분석이 일치하는 것을 알 수 있었다.
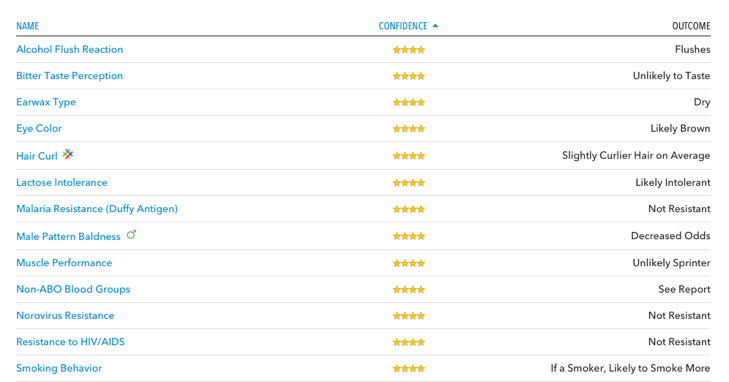
필자의 웰니스 검사 결과 일부
- 조상 계통 분석 (Ancestry Composition): 유전적인 정보를 통해서 자신의 조상들이 어느 대륙에서 온 사람들인지를 게통을 분석해주기도 한다. 한국과 달리 다인종 국가인 미국에서는 자기 조상의 뿌리가 어디인지에 대한 관심도 높다. 필자의 경우에는 100% 아시아 계열로 나오는데, 한국계, 일본계, 중국계의 뿌리를 56.2%, 33.9%, 3.3% 를 각각 가지고 있음을 알게 되었다. 또한 네안데르탈인의 DNA를 얼마나 가지고 있는지를 계산해주기도 한다. 필자의 경우에는 3.2%의 DNA가 네안데르탈인에게서 유래했는데, 이는 상위 95%에 포함될 정도로 네안데르탈인과 더 가까운 것을 의미한다.
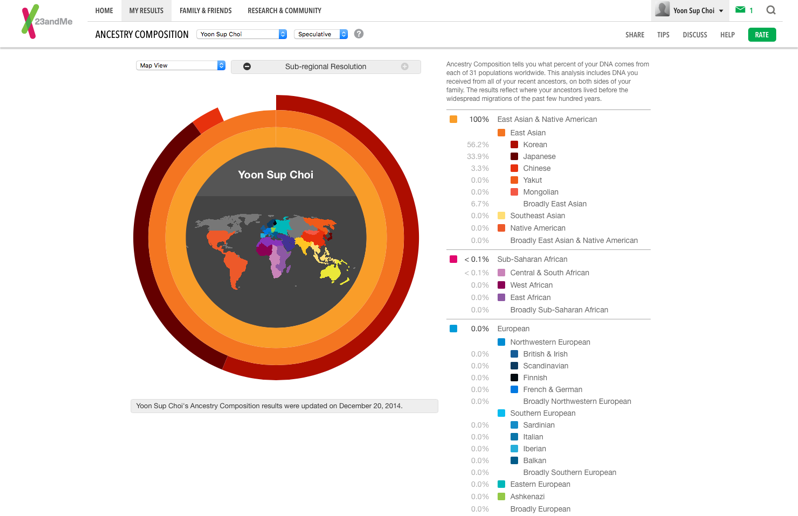
필자의 조상 계통 분석 결과 일부
패쓰웨이 지노믹스의 분석 항목
23andMe와 더불어 대표적인 개인 유전 정보 분석 서비스를 제공하는 미국 샌디에고의 패쓰웨이 지노믹스의 분석 항목도 간단하게 살펴보자. 패쓰웨이 지노믹스는 23andMe처럼 DTC를 고집하지는 않고, 병원을 통해서 판매하고 있다. 몇년 전 한국에도 진출하여 몇몇 국내 병원에서 이 분석을 일반인들도 받아볼 수 있다. 이 분석 역시 SNP 분석만을 기반으로 한 것이다. 이 회사가 제공하는 여러 분석 중에 패쓰웨이 핏 (Pathway Fit) 이라는 분석을 기준으로 설명해보겠다.
패쓰웨이 핏의 분석 항목은 23andMe의 분석 항목과는 추구하는 방향이 약간 다르다. 이 분석에서는 음식을 섭취하거나, 운동을 하고, 체중관리를 하기 위한 항목들이 다수 포함되어 있다. 이를 흔히 라이프 스타일 분석이라고 한다. 대표적인 것은 아래와 같다.
- 섭식 행동 분석: 음식물을 섭취하는 행동에 대한 유전적인 요인을 분석한다. 필자의 경우, 극단적으로 간식을 많이 먹지는 않으며, 공복감에 대한 민감성이 보통 수준이다. 또한 식사 후에 적절한 포만감을 느끼며, 무절제한 섭식에 대한 가능성이 낮다. 또한 단 음식에 대한 선호도 역시 보통 수준이다.
- 음식물 반응 분석: 음식물을 섭취했을 때 내 신체의 반응에 영향을 미치는 유전적인 요인을 알려준다. 필자의 경우, 카페인 대사가 빠를 가능성이 높으며, 쓴 맛에 매우 예민할 가능성이 있다. 단 맛에 대한 감수성은 보통이며, 유당 분해능력이 떨어질 수 있다.
- 비타민 관련 분석: 각종 비타민의 분해 및 흡수 능력에 따라 비타민 농도를 체내에서 적절하게 유지하기 위해서 어떤 비타민을 많이 먹어야 하는지를 알려준다. 필자의 경우 비타민 B2, B12, D, 엽산은 섭취를 늘리는 것이 좋고, 비타민 B6, C 의 경우에는 보통 수준으로 섭취하면 된다.
- 운동 관련 분석: 운동 능력에 영향을 미치는 유전형 및 운동에 따른 건강 관리가 효과적인지에 대한 분석을 해준다. 필자의 경우, 근력 운동은 효과가 적으며, 유산소 운동 능력은 보통이다. 아킬레스 건병증에 대한 부상이 취약하며, 운동에 따른 체중 감소 반응과 혈압 반응, HDL(좋은 콜레스테롤) 반응은 보통인 편이다.
- 체중 감량 관련 분석: 비만이나 체중 감량, 요요와 관련한 유전적 소인을 분석해준다. 필자의 경우, 비만에 대한 가능성은 보통이며, 감량 후에 체중의 재증가 가능성은 높다. 체내 에너지 대사는 보통 수준이며, 아디포넥틴 (지방 세포가 생성하는 호르몬) 수치도 보통인 편이다.
 필자의 ‘패쓰웨이 핏’ 분석 결과 요약 부분
필자의 ‘패쓰웨이 핏’ 분석 결과 요약 부분
개인 유전 정보 분석의 한계
이렇게 개인에 대해서 질병, 약물, 영양, 섭식 등의 다양한 측면에 대한 유전적인 분석이 지금도 가능하다. 이러한 분석은 모두 기존의 과학적인 연구 결과들을 바탕으로 한 것들이다. 하지만 이러한 개인 유전 정보의 분석에는 분명한 한계점도 있음을 짚고 넘어가야 할 것이다.
첫 번째로, 이러한 분석은 극히 제한적인 유전정보만을 바탕으로 한다는 것이다. 앞서 설명했듯, 유전 정보의 분석에는 전 유전체 분석, 엑솜 분석, 유전자 패널, 그리고 SNP 분석 등의 다양한 방법이 있다. 그 분석법들 중에서 23andMe, 패쓰웨이 지노믹스 등 대부분의 개인 유전정보 분석 회사들이 사용하는 방법은 SNP 분석이다. 유전 정보 전체를 책에 비유한다면, SNP 분석은 매 페이지의 한 두 단어 정도만 읽는 것이라고 할 수 있다. 즉, 전체 유전정보 중의 극히 일부분만 분석한다는 것이다.
또한 많은 논문이나 기사에서 지적되었듯이, 특정 항목의 분석을 위해서 어떤 SNP를, 혹은 SNP들의 조합을 바탕으로 할 것인지에 대한 업체 간 차이도 존재한다[1, 2, 3, 4, 5]. 예를 들어, 유방암의 위험도와 관련이 있다고 알려진 SNP은 다수가 있다. 이 중에서 어떤 SNP를 분석에 포함시켜서 유방암의 위험도를 도출할 것인지는 각 분석 기업별로 차이가 있을 수 있다. 따라서 동일한 환자의 동일한 검사 항목에 대한 결과가 정반대로 나오는 경우도 생기게 된다.
실제로 관련 연구들을 보면 동일한 샘플을 다른 회사에 의뢰하였을 때 상당수의 검사 항목에 대해서 결과가 반대로 나오는 것을 확인한 바 있다[1, 2, 3, 4, 5]. 만약 질병 예방을 위한 분석의 결과가 이렇게 상반될 경우 경우, 이를 기반으로 의료적 의사결정을 내리는 것에 문제가 있을 수 있다.
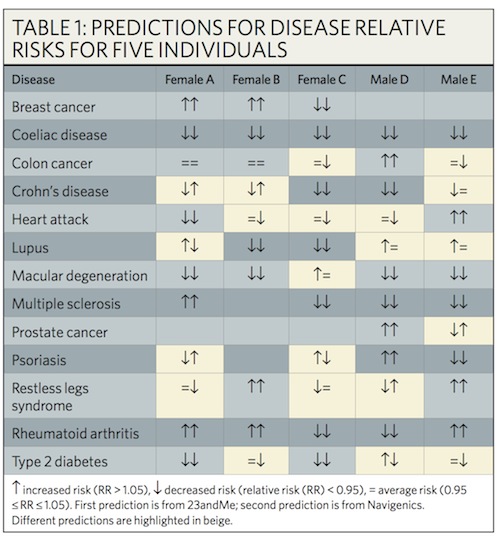 같은 환자에 대한 질병 위험도 분석에 대한 결과가 정반대로 나오기도 한다 (출처: 네이처)
같은 환자에 대한 질병 위험도 분석에 대한 결과가 정반대로 나오기도 한다 (출처: 네이처)
두 번째로 유전정보 분석은 환경적인 요인을 고려하지 못한다는 근본적인 한계가 있다. 많은 질병이나 건강 상태는 타고나는 유전적인 요인뿐만 아니라, 생활 습관이나 식습관, 주변 환경 등의 요인과 복합적으로 작용하게 된다. 유전 질병과 같이 오로지 유전적인 요인에서만 결정되는 경우를 제외한다면, 대부분의 질병과 건강에는 (정도의 차이는 있겠으나) 환경적인 요인도 역할을 하게 된다.
조금 더 전문적인 이야기를 하자면, DNA 에 저장되어 있는 유전정보라고 해서 모두가 발현되는 것은 아니다. DNA 자체도 다양한 메커니즘을 통한 조절을 받으며, DNA가 RNA로 전사되고, RNA가 단백질로 번역되는 과정에서도 복잡다단한 생물학적인 조절을 받게 된다. 유전 정보만 분석해서는, 이 유전 정보가 실질적으로 우리 신체나 질병에 영향을 주기까지 후성유전체(epigenome), 전사체(transcriptome), 단백체(proteome), 대사체(metabolome) 적으로 어떠한 과정을 거치는지는 알기 어렵다. 이러한 분야들에 대해서도 활발한 연구들이 진행되고 있으며, 추후 그 중요성은 더욱 강조될 것이다.
건강은 유전적 요인 이외에도 많은 요인의 영향을 받는다
세 번째로 유전적인 위험도를 정확하게 알 수 있다고 하더라도 이를 바탕으로 한 대비책이 마땅히 없거나 불투명한 경우가 많다. 소위 ‘그래서 어떡하라고? (So What?)’ 이라는 질문에 답하기 어렵다는 것이다. 예를 들어, 특정 질병에 대한 위험도가 높다는 결과를 받았다고 해보자. 대부분의 경우 해당 질병을 예방하기 위해서 우리가 선제적으로 취할 수 있는 선택지는 많지 않다.
안젤리나 졸리와 같이 유방이나 난소를 미리 예방적으로 절제할 수도 있겠다. 하지만 이러한 예방적 절제술이 지나치게 적극적인 치료가 아닌지에 대해서 여전히 많은 논의와 연구가 진행되고 있으며[1, 2, 3], 모든 질병에 일반적으로 적용할 수 있는 방법도 아니다.
사실 안젤리나 졸리와는 달리 특별한 대비책이 없는 경우가 더 많다. 만약 당뇨병이나 심장질환 등에 대한 위험도가 높다고 해보자. 이를 예방하기 위해서는 정기적으로 검진을 받고, 식습관을 조절하고, 음주나 흡연을 삼가고, 규칙적인 운동을 하라는 등의 일반적인 조언밖에 해줄 것이 없다. 필자의 23andMe 분석 결과 위험도가 높다던 심방세동이라는 질병을 예방하기 위해서 얻은 조언도 별반 다르지 않았다. 이런 일반적인 조언은 유전정보 분석을 하지 않아도 누구나 해줄 수 있는 조언일 것이다. 이 문제는 업계의 모든 사람들이 인식하고 있으며, 이를 해결하기 위해 여러 서비스를 연계시키는 등 다양한 방법들이 시도되고 있다.
유전 정보의 폭발적 증가
이러한 근본적인 한계에도 불구하고, 유전 정보가 가지는 가치는 갈수록 커진다고 할 수 있다. 이 부분에서 우리가 주목해야 할 또 하나의 이슈는 바로 유전 정보를 분석한 사람들의 수가 폭발적으로 증가하고 있다는 것이다. 국내에서는 자신의 유전 정보를 분석해본 사람들의 수가 그리 많지 않다고 앞서 언급한 바 있다. 하지만 이러한 상황은 외국에서는 완전히 다르다.
대표적인 개인 유전정보 분석회사 23andMe의 경우에는 2016년 2월 기준으로 이미 고객 수가 120만 명을 넘어섰다. 2016년 중반에는 150만 명을 넘었다는 이야기도 들린다. 이 하나의 회사를 통해서 분석한 사람들의 숫자만 그러한 것이다. 23andMe의 창업자이자 대표인 앤 워짓스키는 창업 초기부터 100만 명의 유전 정보를 분석하는 것이 목표라고 공공연하게 언급한 바 있다. FDA의 규제를 받는 등 여러 고초를 겪었지만, 100만 명이라는 목표를 2015년 6월에 마침내 달성하였고, 지금도 고객은 꾸준하게 증가하고 있다.
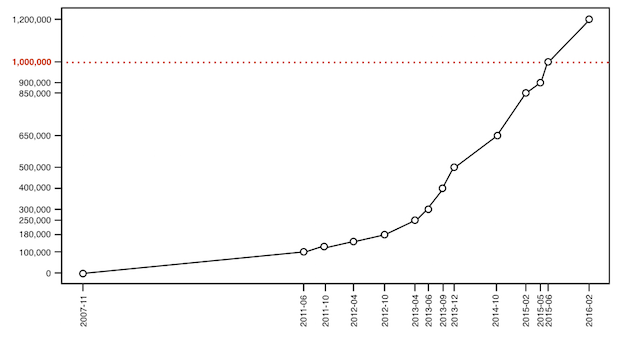 23andMe 고객의 폭발적인 증가 (출처: 3billion 금창원 대표님)
23andMe 고객의 폭발적인 증가 (출처: 3billion 금창원 대표님)
또한 패쓰웨이 지노믹스는 고객 수를 외부에 공개하지는 않았으나, 필자가 2015년 5월 샌디에고의 본사를 방문하여 관계자와 미팅을 하면서 물어보았을 때, 수십만 명 정도의 고객을 확보했다고 이야기한 바 있다.
굳이 이 두 기업의 사례를 들지 않더라도, 인류가 가진 DNA 데이터의 양은 그야말로 기하급수적으로 증가하고 있다. 2015년에 발표된 연구에 따르면, 지금까지 인류가 가진 유전 정보의 양은 7개월마다 두 배씩 증가해왔다. 이는 앞서 강조한, 무어의 법칙, 즉 집적회로의 성능이 18개월에 두 배씩 좋아진다는 것보다 훨씬 빠른 것이다. 현재의 유전 정보 증가 속도가 앞으로도 유지될지는 알기 어려우나, 일루미나의 경우 두 배씩 늘어나는 주기를 12개월 정도로 보고 있다. 어찌 되었건, 유전 정보의 양이 향후 크게 증가할 것이라는 것은 누구도 부인하기는 어려워보인다.
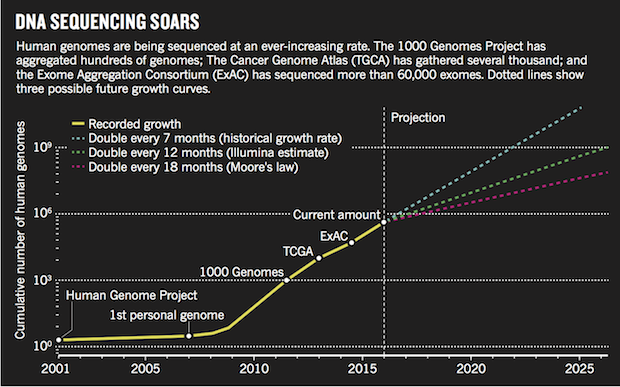
세계적으로 기업들도 유전체 분석에 앞다투어 나서고 있다. 중국의 BGI 가 100만 명의 유전체 분석을 목표로 진행하고 있으며, 다국적 제약사 아스트라제네카는 200만 게놈 프로젝트를 진행 중이다. 휴먼 게놈 프로젝트의 선구자 크레이그 벤터 박사의 휴먼 롱제비티(Human Longevity)는 이미 2만 개 이상의 유전체를 분석했고, 그중 만 명을 분석한 내용을 2016년 논문으로 출판하여 주목받기도 했다.
더 나아가 많은 기업뿐만 아니라, 정부나 자치단체가 이러한 유전체 분석 연구를 지원하면서 국가별로도 다양한 유전체 분석 프로젝트들이 시행되고 있다. 예를 들어, 미국 오바마 정부의 정밀 의료 이니셔티브에서 100만 명의 유전체를, 중국의 정밀 의료 이니셔티브는 2030년 경까지 무려 1억 명의 유전체 분석을 할 계획이다. 영국에는 지노믹스 잉글랜드라는 10만 명 규모의 프로젝트를 진행 중이며, 게놈 아시아에서도 10만 명 규모, 프랑스 게놈 프로젝트에는 235,000명을 목표로 프로젝트를 진행하고 있다. 한국도 다소 후발 주자이기는 하나 울산시와 울산과기원 등을 중심으로 2015년 11월 ‘울산 1만 명 게놈 프로젝트’의 출범을 선언했다. 이처럼 인류의 유전체 데이터는 지금 이 순간에도 폭발적으로 증가하고 있다.
한 연구에 따르면 2025년 경에는 인류가 가지게 될 여러 종류의 빅 데이터 중에서도 유전체는 단연 가장 큰 데이터가 될 것으로 전망된다. 천문학 데이터, 유튜브 영상 데이터, 트위터 데이터와 비교했을 때에도 더 큰 규모가 생산되고 저장되며 분석될 것으로 예상된다는 것이다.
특히 천문학과 유튜브는 연간 1 엑사바이트가 저장될 것으로 보이는 반면, 유전체 데이터는 2~40 엑사바이트가 연간 저장될 것으로 보았다. (엑사바이트는 1,000,000 테라바이트) 이 데이터에는 단순히 DNA 서열 뿐만 아니라, 유전체 속에 어떤 변이가 있는지 등의 추가적인 분석 정보가 모두 포함되므로 데이터의 양은 더욱 커진다. 이 연구에서는 방대한 유전체 데이터의 생산, 저장, 전송, 분석 등의 네 가지 부분이 모두 이슈가 될 것이라며, ‘머리가 네 개 달린 괴물’에 비유했다.
 천문학, 트위터, 유튜브와 비교해서 2025년 인류가 가질 가장 큰 데이터는 유전체 데이터일 것이다 (출처)
천문학, 트위터, 유튜브와 비교해서 2025년 인류가 가질 가장 큰 데이터는 유전체 데이터일 것이다 (출처)
이 거대한 데이터의 저장, 전송, 분석 등을 위해서는 클라우드 컴퓨팅이 아마도 유일한 해법이 될 것이다. 미국의 DNA넥서스, 구글, 중국의 BGI 와 같은 기업들은 이렇게 유전체 데이터를 위한 클라우드 환경을 구축했다. 구글에 앞서 국내에서도 KT가 게놈클라우드(GenomeCloud) 서비스를 런칭한 바 있다.
23andMe의 연대기로 보는 DTC의 역사
개인 유전정보 분석을 이야기할 때 빼놓을 수 없는 것이 바로 DTC (Direct-to-Consumer) 서비스와 관련된 논란이다. DTC는 유전 정보 분석 서비스를 제공할 때 병원이나 의사를 거치지 않고, 개인 고객에게 직접 서비스하겠다는 것이다. 고객이 굳이 병원을 방문하지 않고, 집에서 우편과 간편하게 타액을 제공하고 인터넷으로 결과를 확인할 수 있으므로 서비스에 대한 접근성이 매우 높아진다. 따라서 유전 정보 분석을 서비스하는 기업의 입장에서는 고객 확보에 용이한 DTC를 선호하게 된다.
하지만 질병이나 약물과 관련된 민감하고 전문적인 분석까지도 의료 전문가의 개입 없이 직접 서비스를 해도 되는지에 대한 논란은 지금까지도 계속되고 있다. 특히 의료계 일부에서는 전문 의료 지식이 부족한 일반인들이 질병, 약물에 대한 유전 정보 분석 결과를 받아보고, 약물 남용 등 잘못된 선택을 할 수도 있다는 것을 근거로 DTC 서비스에 대해서 우려를 표명하고 있다. 그렇다면 음식물 섭취나 운동, 조상 분석과 관련된 항목까지도 DTC 서비스가 위험할까?
사실 어느 범위까지 DTC를 규제하고 허용할 것인가는 한국을 포함한 세계 여러 나라에서 현재까지도 논란이 되고 있는 현재 진행형 이슈이다. 이러한 논란을 공론화시키는 데는 다름 아닌 23andMe가 주도적인 역할을 했다. 23andMe의 연대기를 간략히 보면서 DTC를 둘러싼 논란에 관해서 짚어보자.
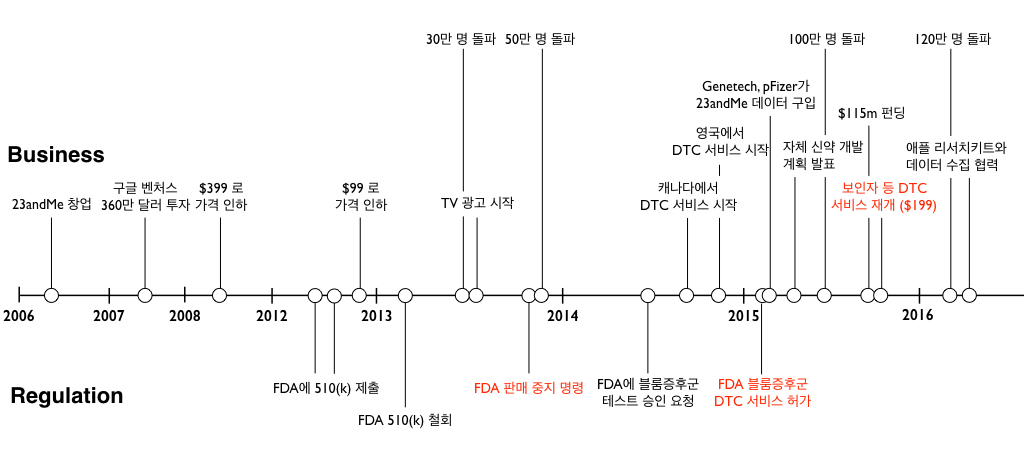
23andMe 연대기 (출처: 최윤섭 디지털헬스케어 연구소)
2006년 창업한 23andMe는 처음부터 지금까지도 DTC 방식의 고객 직접 판매 방식을 고수하고 있다. 초기에는 SNP 분석을 통한 서비스의 가격이 1,000달러에 가까웠으나, 2008년에 399달러, 그리고 2012년 말에 단돈 99달러로 인하하면서 시장의 폭발적인 반응을 얻게 된다. 당시 23andMe는 99달러에 120개 주요 질병에 대한 위험도, 50여 개 유전 질병에 대한 보인자 테스트, 20여 개 약물에 대한 민감도, 60여 개의 일반적인 특징들, 조상 분석 등을 제공했다.
더 나아가 2013년 중순에는 지상파 TV 광고도 했다. 한국은 물론 미국에서도 유전정보 검사의 광고를 TV에서 볼 수 있는 것은 지금도 매우 드문 사례인만큼 당시에도 매우 파격적인 행보였다. 이 광고에서, 23andMe는 “당신의 DNA에 대해서 더 많이 알수록, 당신 자신에 대해서 더 많이 아는 것이다” 는 것을 강조했다. 뿐만 아니라, 심장병, 관절염 등의 질병에 대한 위험도, 자신에게 맞는 음 식 등을 알게 됨으로써 더욱 건강한 삶을 영위할 수 있다는 메시지를 대중들에게 각인시켰다.
 23andMe의 텔레비젼 광고의 한 장면
23andMe의 텔레비젼 광고의 한 장면
이렇게 승승장구하던 23andMe는 별안간 FDA의 규제 철퇴를 맞게 된다. 2013년 11월 FDA는 23andMe의 CEO 앤 워짓스키에게 보낸 공개서한에서 DTC 판매를 중지할 것을 명령한 것이다. FDA는 오로지 약이나 의료기기와 같은 의료용 목적의 물질 혹은 기기만 관장하며, 단순한 건강관리 목적의 서비스에 대해서는 관리를 하지 않는다. 이런 FDA가 23andMe의 일반인 대상 DTC 서비스의 위해도가 높다는 것을 이유로 판매 금지 신청을 한 것이다.
아래와 같이 FDA는 서한에서 ‘안젤리나 졸리 유전자’로 유명해진 BRCA 유전자에 대한 결과나, 유전 형질에 따라 투여 농도가 달라질 수 있는 혈액 응고 억제제인 와파린을 예로 들어서, 분석 결과가 부정확할 경우 발생할 위험에 대해서 설명했다.
개인 유전정보 분석의 BRCA 관련 질병 리스크나 약물에 대한 반응 결과들은 특히 우려스럽다. 이러한 결과들이 부정확할 경우에 야기될 수 있는 잠재적인 위험 때문이다. 예를 들어, 만약 유방암이나 난소암에 대한 BRCA 분석 결과가 부정확한 경우, 이는 환자들이 불필요한 검사, 수술이나 약물요법 등을 받을 수도 있고, 또 반대로 정말 이러한 처치를 받아야 할 환자가 필수적인 처치를 받지 않게 될 수도 있다
즉, FDA는 질병 위험도 분석, 약물 민감도 분석을 의료기기로 간주하고, DTC 서비스를 지속하기 위해서는 추가적인 연구와 근거를 바탕으로 인허가를 받아야 한다는 것을 요구한 것이다. FDA의 공개 서한에서는 다른 여러 측면도 드러났다. 23andMe는 FDA의 허가를 받기 위해서 이미 2009년 7월부터 FDA와 활발하게 커뮤니케이션 해왔고, 그로부터 3년 뒤인 2012년에 두 차례에 걸쳐 510(k) 승인 요청을 했다는 것을 알 수 있다. 하지만 2013년 들어서 23andMe에서 FDA와 커뮤니케이션이 단절되었고, 테스트에 대한 근거도 제공하지 못했는데도 대규모 TV 광고를 진행하면서 FDA의 심기를 건드렸던 것으로 보인다.
사실 23andMe도 패쓰웨이 지노믹스 등 다른 경쟁자처럼 DTC 방식을 포기하고 의료기관을 통해서 서비스하면 사업을 지속할 수 있었다. 하지만, 23andMe는 FDA의 권고를 받아들여 질병과 약물에 대한 분석을 중단하게 된다. 다만, 서열 분석의 원본 데이터만 제공하는 것, 조상 분석 등은 계속 진행하였다[1, 2]. (이 과정에 대해서는 필자의 전작인 ‘헬스케어 이노베이션’에 별도의 챕터로 자세하게 설명한 바 있다)
절치부심한 23andMe는 이후 차근차근 재기의 기회를 노린다. FDA로부터 판매 금지 명령을 받은 지 7개월이 되던 2014년 6월 23andMe는 블룸 증후군이라는 ‘하나의’ 유전 질병의 보인자 검사에 대한 승인을 요청했다. 블룸 증후군은 희귀 유전질환으로 작은 키, 광민감도(photosensitivity)의 증가, 얼굴 모세 혈관 확장증, 각종 암 (특히 백혈병과 림프종)에 대한 위험도가 크게 증가하는 특징을 가지는 질병이다. 23andMe는 블룸 증후군의 보인자 여부를 정확하게 측정할 수 있다는 근거를 두 개의 독립적인 연구를 통해서 제시했다. 이 희귀 유전 질환은 유전적 용인과 발병 관계가 아주 명확하므로, 원래 분석하던 100개 이상의 질병 중에서 ‘가장 낮은 곳에 달린 사과’부터 하나씩 따겠다는 전략이었다.
뿐만 아니라, 미국 이외에 DTC가 허용되어 있는 국가로 서비스를 확대했다. 2014년 10월에는 캐나다, 11월에는 영국에 DTC 서비스를 제공하기로 한 것이다. 의료 사회주의 시스템을 채택하고 있는 영국은 당시 DTC에 대해서 업계의 자율적 규제를 허용하고 있었으며, 캐나다의 규제 기관인 헬스 캐나다(Health Canada) 역시 DTC에 대해 규제하지 않는다고 밝힌 바 있었기 때문이다.
그러던 2015년 2월 FDA는 23andMe의 DTC 방식의 블룸 증후군 보인자 테스트에 대해서 드디어 허가해주게 된다. 특히 FDA는 1-3등급 중 이 테스트를 2등급(Class II)의 의료기기로 판단했다. FDA에서 위해도가 가장 높은 의료기기는 3등급으로 판단되어 시장 출시 전에 반드시 승인(premarket approval)을 얻어야만 한다. 하지만 위해도가 상대적으로 낮은 기기에 부여되는 2등급은 시장 판매를 위해 별도의 허가 없이 단순히 등록 절차만 거치면 된다.
즉, 이는 23andMe의 블룸 증후군뿐만 아니라 다른 보인자 테스트도 DTC로 서비스할 수 있게 허용해주겠다는 FDA의 결정이었다. 이에 따라 23andMe는 2015년 10월부터 낭성 섬유증(cystic fibrosis), 겸상 적혈구 빈혈증(sickle cell anaemia), 테이-삭스 병(Tay-Sachs) 등 36가지의 유전 질병에 대한 보인자 테스트를 DTC 방식으로 재개하게 된다. 다만 이때부터 분석비는 199 달러로 인상했다. 이후 2016년 9월에는 조상 계통 분석만은 99 달러에 판매하기도 했다.
- 관련 포스팅:
DTC 유전 정보 검사는 정말 위험할까
이렇게 DTC 유전정보 검사를 허용할 것인지에 대해서는 국내뿐만 아니라, 이미 미국에서도 오랜 기간 논쟁 거리였으며, 지금도 진행 중인 이슈이다. 사실 2013년 FDA가 질병이나 약물 유전자에 대한 DTC 분석 서비스를 금지하자, 미국의 전문가들 사이에서도 이 규제가 꼭 필요하다는 쪽과 과도하다는 쪽으로 의견이 나뉘었다 [1, 2].
전자는 일반인이 유전자 분석 결과를 이해할 능력이 부족하며 정보에 기반한 불필요한 수술이나 약물 오남용 등의 부작용을 우려했다. 하지만 후자는 일반인도 해단 분석의 한계와 위험을 인지하고 있으므로, 일반인이 직접 유전정보 분석 결과를 받더라도 실제로 위험도는 높지 않다고 지적한다.
필자는 후자의 의견에 동의하는 편이다. 이는 사실 여러 연구 결과로도 뒷받침된다. 2009년 미국에서 DTC 분석을 받은 3천 명을 대상으로 스크립스 연구소에서 조사한 결과 테스트 결과를 받은 지 12개월 이후에도 불안감이나 심리적인 건강에 큰 영향이 없었다 [ref 1, 2].
2010년 존스홉킨스의 연구 결과도 크게 다르지 않다. DTC 검사 이후 상당수의 사람들이 식습관(72%)이나 운동 습관(61%)을 바꾼 것에 비해, 의사와 상의 없이 처방약을 바꾼 환자는 전체의 1% 도 되지 않았다 [ref 1, 2]. 더 나아가, 대장암 위험도가 높게 나온 사람의 경우, 질병에 대해 더 관심을 갖게 되었으며, 의사를 찾아가 상담을 더 하게 되었으며, 식습관을 바꾸고, 운동을 할 가능성이 높아졌다[ref].
또한 2013년 FDA의 금지를 받을 당시 23andMe에서 유전자를 분석한 50만 명에 달했으나 결과에 따라 극단적인 선택을 하는 등 부작용이 보고된 사례도 없었다. 뉴욕 대학교 법학과의 리처드 엡스타인(Richard Epstein) 교수는 “FDA는 그 회사의 고객들을 조사해서 FDA가 주장하는 것처럼 23andMe가 위험한 결과를 낳고 있다는 명백하고 설득력 있는 근거를 보여줬어야 했다” 라며 FDA의 규제에 설득력이 부족함을 지적했다.
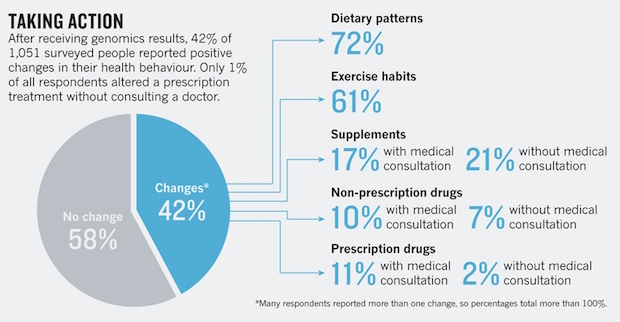
DTC 검사에 기반해 의사와 상담 없이 처방약을 바꾼 경우는 전체의 1% 미만이었다 (출처: 네이쳐)
국내 DTC 제한적 허용
그렇다면 국내에서는 개인 유전 정보 분석에 대한 DTC 가 얼마나 허용되어 있을까. 2016년 중순까지만 해도 국내에서 유전정보 검사를 하기 위해서는 분석 목적을 막론하고 반드시 의료 기관을 거쳐야만 했다. 암과 같은 질병의 예측이든, 대머리 유전자의 검사든, 카페인 민감도의 검사든 말이다.
사실 국내 관련 업계에서는 비의료기관, 즉 일반 기업도 소비자를 상대로 DTC로 유전 정보 분석 서비스를 제공하는 것이 오랜 숙원이었다. 개인 유전정보 분석 시장이 폭발적으로 성장하고 있는 미국에 비해 국내 시장의 성장은 미미한 것도 소비자 대상의 직접 서비스가 원천적으로 막혀 있기 때문이라는 지적이 많았다.
복지부는 이 문제에 대해서 고심해왔으며, 2015년 12월 ‘생명윤리 및 안전에 관한 법률’ 개정에 이어, 2016년 1월 업무보고에서 ‘질병 예방 목적의 일부 유전자 검사를 비의료기관에서 직접 실시’ 하는 것을 허용할 예정이라고 공식적으로 발표한 바 있다. 공청회도 여러 번 개최하면서 학계와 산업계의 여러 의견을 청취하는 과정도 거쳤다. 그 결과 ‘비의료기관 직접 유전자검사 실시 허용 관련 고시’가 제정되며 2016년 6월 30일부터 ‘제한적’으로 DTC 유전자 검사 서비스가 허용되기에 이르렀다.
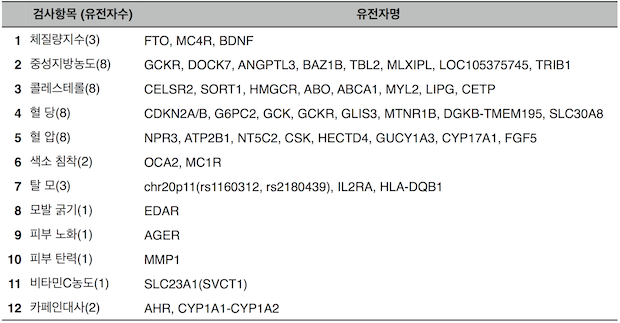
이 고시에 따르면 체질량지수, 중성지방농도, 콜레스테롤, 혈당, 혈압, 색소침착, 탈모, 모발 굵기, 피부 노화, 피부탄력, 비타민 C농도, 카페인 대사 등 12가지 검사 항목에 대한, 46개 유전자에 대해서 DTC 서비스가 가능하다. 포지티브 규제를 기조로 하는 국내 규제에서는 이처럼 ‘명시한 것만 허용하고, 나머지는 모두 금지한다’는 방식이다. 미국과 같이 ‘금지하는 것을 명시적으로 정해두고, 나머지는 일단 허용한다. 하지만 시행 후 잘못되면 크게 징계한다’는 네거티브 규제와는 반대 방식이다.
필자가 보기에는 규제를 개선시킨 범위와 방식이 매우 아쉽다. 학계와 산업계에서 의견을 청취한 것이 무색하게 너무도 제한적인 항목과, 제한적인 유전자에 대해서만 DTC가 허용된 것이다. 대한의사협회에서는 “민간 기업에서 불명확한 정보로 환자를 현혹하거나 극단적으로는 태아의 성별 감별 후 불법적인 낙태 등의 비윤리적 행위로 이어질 수 있다는 점도 문제”라고 우려를 제기하긴 했지만, 허용 범위가 너무 제한적이라 오히려 그런 우려가 다소 머쓱해질 정도다.
각 검사 항목뿐만 아니라, 항목별 검사할 수 있는 유전자까지도 제한해버린 것도 아쉽다. 연구가 계속될수록 유전형과 표현형 사이의 새로운 관계가 밝혀지면, 당연히 유전자의 목록도 변화한다. 하지만 이런 방식의 규제는 최신 연구 결과를 분석 결과에 반영하는 것을 원천적으로 막고 있다. 끊임 없이 새로운 유전자와 표현형의 관계가 밝혀지고, 연구 결과가 나오는 것을 고려하면, 이러한 분야에서는 미국과 같이 네거티브 규제 방식을 적용하는 것이 옳다고 생각한다.
더 큰 문제는 규제를 위해 들이댄 잣대 자체가 FDA 등 글로벌 규제 기조나 산업계에서 통용되는 기준과는 전혀 다르다는 것이다. 복지부의 고시에 나오는 유전자의 목록을 들여다보면, 앞서 23andMe를 예시로 설명한 질병/약물/보인자/웰니스/조상 분석 등의 업계에서 받아들여지는 분류와는 기준이 전혀 다르다.
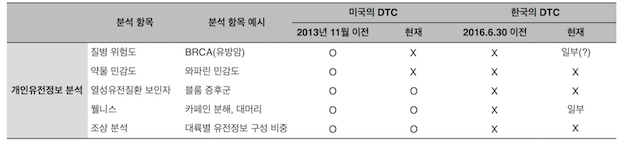
질병 분석을 예로 들어보자. 복지부 고시에 따르면 혈압, 혈당 등의 질병과 관련된 항목의 DTC 검사가 가능하다. 하지만 ‘혈압의 조절이 어려울 수 있다’ 정도는 서술 가능하지만 ‘고혈압의 위험도가 높다’ 는 분석은 허용되지 않는다고 알려져 있다. 즉, 한국에서는 질병 분석의 DTC가 허용된 것도 아니고, 완전히 허용되지 않은 것도 아닌 애매한 상황이다. 또한 미국에서는 DTC가 허용된 유전질병 보인자 검사는 여전히 한국에서 DTC는 불법이다. 반면 카페인 대사, 탈모 등의 웰니스 검사는 고시에 명시된 일부만 허용된다.
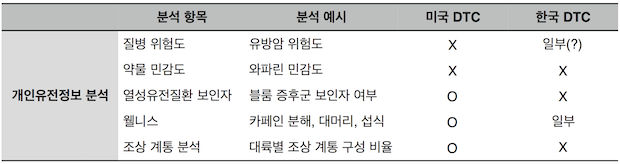
한국과 미국의 DTC 유전정보 서비스 허용 비교 (2016년 12월 현재)
이처럼 해외와 한국의 규제 기준에 차이가 크게 되면, 국내 관련 업계에서는 서비스를 제공하기에 또 다른 장애물이 생긴다. 미국에서 만든 규제를 한국에서 무작정 똑같이 따라 해서는 안 되겠지만, 최소한 그들이 먼저 정한 규제에 어떤 논리와 근거가 있는지 따져보는 것은 합리적일 것이다.
필자는 2016년 6월 30일에 발표된 DTC의 허용은 기준도 애매모호하며, 범위는 너무 제한적이라 실효성이 없으며, 의료적으로나 산업적으로도 미치는 영향은 극히 미미하리라고 생각한다. 고시가 제정된 이후 관련 업계의 기업들에서는 분석이 허용된 피부, 뷰티 등의 항목을 중심으로 DTC 서비스를 런칭했지만, 아직까지 시장에서의 반응은 크지 않은 편이다.
이러한 규제 하에서는 한국에서 유전 정보를 가진 개인들이 앞으로 빠르게 증가할 것을 기대하기는 어려울 것 같다. 데이터를 가진 개인이 많지 않으면, 그러한 데이터를 저장, 분석, 활용하는 연관 산업도 성장할 수 없다. 해외에서는 수백만 명의 개인들이 이러한 정보를 이미 가지고 있으며 그 숫자가 계속 기하급수적으로 증가하는 것을 생각해보면, 지금 이 순간에도 한국과 글로벌의 격차는 빠르게 커지고 있는 셈이다.
나의 데이터는 누구의 소유인가
사실 DTC 허용에 관해서는 보다 근본적이고도 중요한 문제가 있다. 바로 유전 정보가 누구의 소유이냐 하는 문제이다. 앞서 필자는 디지털 의료에서 데이터가 가장 중요하며, 데이터를 소유하는 기업이 최후의 승자가 될 것이라고 언급한 바 있다. 데이터의 종류가 다양해지고 양적, 질적으로도 향상되어 그 가치를 깨닫게 되면서 이제 그 데이터가 과연 누구에게 소유권이 있으며, 누가 어디까지 활용할 수 있을지에 대한 많은 논란이 있다.
그 중에 유전정보는 개별 사용자, 개별 환자에 대한 근본적인 데이터를 담고 있으므로, 매우 귀중하고도 민감한 정보가 된다. 만약 질병, 약물 등에 대한 정보가 유출되거나 남용되었을 경우 프라이버시 침해나 사회적 파장은 매우 클 수 있다. 만약 나의 DNA 정보가 정부나, 보험사, 고용주에게 나의 동의 없이 넘어가게 되는 경우를 상상해보면 그 중요성을 알 수 있을 것이다. 내 DNA 속에 들어 있는 정보 때문에 내가 나도 모르는 사이에 취업에서 차별을 받거나, 보험 가입을 거절당할 수도 있을 것이다.
더구나 다른 개인정보와는 달리 유전 정보의 유출은 나만 피해를 보는 것이 아니라, 가족까지도 피해가 갈 수 있다. 내 부모님과 자녀들의 유전정보의 일부까지도 파악당할 수 있기 때문이다. 예를 들어, 안젤리나 졸리의 자녀들은 본인의 의사와 상관 없이 BRCA 유전자의 특정 유전형이 유전될 가능성이 높다는 것이 전세계에 공표되어 버렸다.
그렇다면 나의 유전 정보는 누구의 것일까? 당연히 나 자신의 소유이다. 하지만 내 유전자를 내가 마음대로 검사하고, 그 결과를 내가 온전히 소유할 수 있을까? 이 질문에 대한 답은 결국 DTC가 허용되는지의 여부와 직결되게 된다. 만약 의료기관을 통해서 유전 정보를 검사해야 한다면, 그 데이터는 해당 병원의 데이터베이스에 남게 되고, 온전히 나 자신만이 그 데이터를 소유하고 접근권을 가진다고 보기 어려워질 수 있다.
23andMe가 FDA의 사업 중지 명령을 받고 (의료 기관을 통하면 서비스를 계속 제공할 수 있음에도 불구하고) DTC 방식을 고집하며 사업을 축소한 이유도 바로 이것이다. 개인 고객들에게 자신의 유전 정보에 대한 온전한 소유권을 주겠다는 철학 때문이다. 건강 및 의료 데이터의 소유권 문제는 법적으로도 복잡하며, 전문가들 사이에서 의견도 갈린다. 미국에서도 개인에게 의료 데이터의 온전한 소유권을 부여해야 한다는 목소리도 커지고 있으나, 아직 완전히 해결된 문제는 아니다[1, 2, 3].
유전자 분석: 태어나기 전부터 사망 이후까지
사람의 인생 전체를 지칭하기 위해 흔히 ‘요람에서 무덤까지’ 라는 표현을 쓴다. 이 표현이 유래된 영어의 원래 표현은 라임까지 맞춘 ‘womb to tomb’, 즉 자궁에서 무덤까지이다. 어머니의 뱃속에 있을 때부터, 무덤 속으로 들어갈 때까지. 인간의 전체 생애에서 유전 정보의 분석이 가능한 범위를 설명하자면, 여기에서 한 단계를 더 나아가야 한다. 에릭 토폴 박사의 표현을 빌리자면, ‘pre womb to tomb‘, 즉 태어나기 전부터 무덤 까지라는 것이다.
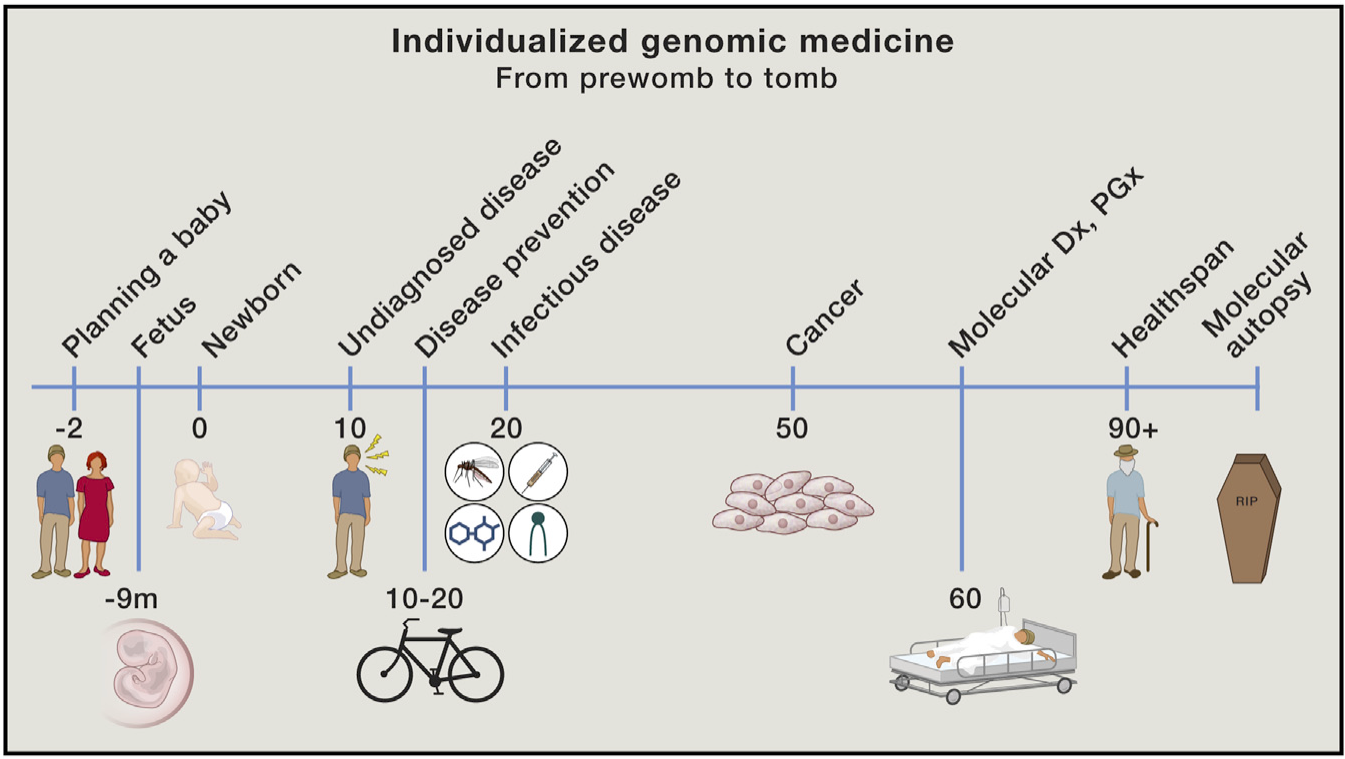 ‘태어나기 전부터 무덤까지’ (출처: Cell)
‘태어나기 전부터 무덤까지’ (출처: Cell)
유전 정보 분석 기술의 발전은 이미 임신 전부터, 사망한 이후에 이르기까지, 문자 그대로 생애 전 주기에 걸쳐서 활용될 수 있다. 앞서 설명한 유전 질병 보인자 분석을 떠올려 보자. 아이를 갖기 전 가족계획을 세울 때부터 예비 부모의 타액을 바탕으로 2세의 유전 질병의 발병 확률을 알아볼 수 있다.
또한 이번 챕터에 모두 설명하지는 못했지만, 태아 단계일 때 비침습 산전 검사(NIPT, Non-invasive prenatal test)를 통해서 산모의 혈액만으로 태아의 기형아 검사 등을 해볼 수 있고, 암과 같은 심각한 질병에 걸렸을 때 유전자 검사를 통해서 치료법 결정에 도움이 될 수 있다[1, 2]. 또한, 큰 질병 없이 장수한 사람들의 유전정보를 분석하여 나온 결과를 토대로, 자신이 얼마나 건강하게 오래 살 수 있을지를 예측하기 위해서 활용될 수도 있을 것이다. 미국 샌디에고의 스크립스 연구소 등에서는 이러한 수명 예측을 위한 연구가 진행되고 있다.
뿐만 아니라, 유전정보 분석을 통해 사망하고 난 이후에도 사망 원인을 밝히기 위한 분자 부검 (molecular autopsy)도 시도되고 있다. 특히 젊은 나이에 별다른 질병 없이 갑자기 사망한 경우, 그 원인을 밝히기 위해 유전정보 분석의 활용이 이용되고 있다. 심장 질환에 의한 돌연사의 원인을 밝히기 위한 연구가 대표적으로, 유족의 슬픔을 위로하거나, 혹은 가족에게도 비슷한 위험이 있는지를 알기 위해서 이러한 분석은 가치가 있다고 하겠다.
이렇게 생애 전 주기에 걸친 유전 정보의 분석 및 활용 하나하나가 새로운 서비스와 사업이 될 것이며, 이러한 분석 결과는 앞으로 우리의 삶에 많은 영향을 끼치게 될 것이다. 이렇게 우리는 지금 개인 유전 정보 분석은 분야는 폭발적으로 성장하기 직전의 변곡점에 도달해 있다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.


















{kind=link}