

MedCityNews.com에 “Personalized Medicine Revolution을 위해 넘어야 할 4가지 장애물 (Four barriers that must fall before the personalized medicine revolution can start)” 이라는 제목의 글이 실렸습니다. 이 글의 요약과 함께 personalized medicine이 현실화되기 위해서는 어떠한 조건이 충족되어야 하는지, 현재 기술은 어디까지 와 있는지에 대해서 알아보도록 하겠습니다.
The urgent need for personalized medicine
- Personalized Medicine의 가장 큰 수혜자는 암환자와 신생아들(newborn screening) 이다. 현재 매년 580,000 명이 넘는 (하루 1,600명) 미국인들이 암으로 사망하고 있으며, 20명의 신생아 중 1명은 신생아 중환자실(neonatal intensive care unit, NICU)로 들어가야 하는 신세가 된다. 또한 신생아 사망의 20%가 선천적 염색체 이상 (congenital chromosomal defect) 때문이다.
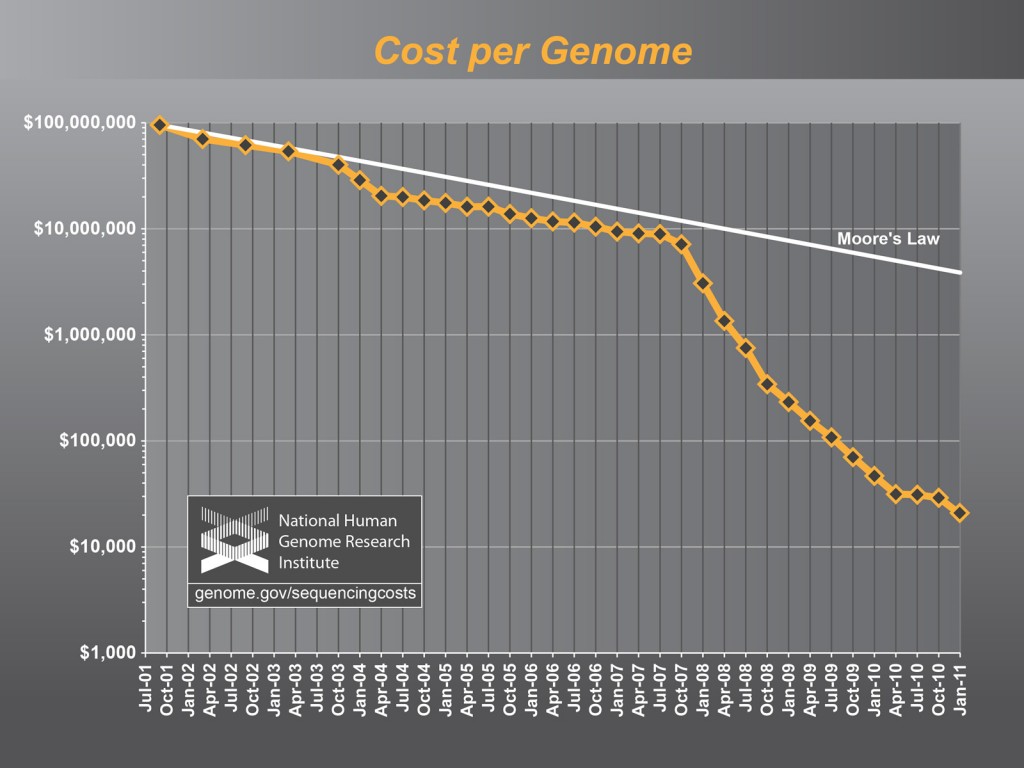
- 무어의 법칙으로 대변되는 반도체 기술의 발전에 힘입어 전산 비용(computing cost)이 대폭 줄어들었고, sequencing 기술의 발달에 따라 기술적으로 whole genome sequencing (전유전체 시퀀싱) 은 더 이상 장벽이 되지 못한다. 특히 sequencing 기술의 기술력(processing power)은 무려 6개월마다 두 배씩 늘어나고 있다.

1. Ultrafast, accurate and low-cost DNA sequencing
- 13년전 휴먼 게놈 프로젝트가 시작되던 때와는 달리 이제는 단 24시간 안에 whole genome sequencing이 가능한 시대가 되었다. 특히 오늘날의 sequencing 기기는 단순한 sequencing 뿐만이 아니라, 1차 분석(primary analysis) 까지 해주고 있다.
- 현재 whole genome sequencing은 $5,000 정도면 가능하며, 많은 미국인들은 자신의 genome sequencing을 위해 기꺼이 돈을 지불할 의사가 있다고 한다.
- 따라서 가장 중요한 돌파구(key breakthrough)는 전체 genome sequencing을 얼마나 빠르게, 또한 얼마나 정확하게 할 수 있느냐 하는 것이다. 최소한의 요건은 다음과 같다: 24시간 안에 genome을 (정확도를 위하여) 40번 반복해서 sequencing할 수 있는가, 그리고 오류율(error rate)이 1 million 중의 하나 이하로 줄일 수 있는가 하는 것이다.
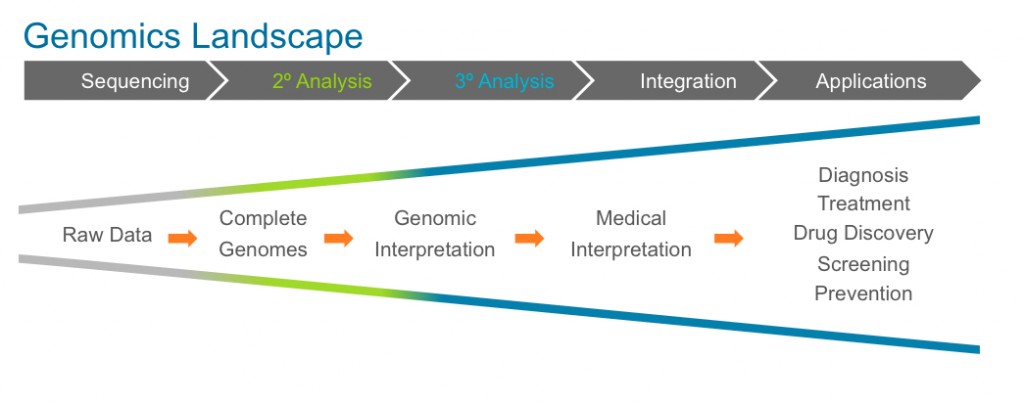
2. Rapid, low-cost, and accurate secondary analysis
- Genome들이 조각으로 sequencing 된 다음에는 수퍼컴퓨터를 이용해서 이러한 조각을 완전한 하나의 genome으로 조합(assemble) 하는 ‘2차 분석(secondary analysis)’ 이 필요하다. 이러한 과정에는 수퍼컴퓨터, 인프라, 숙련된 생물정보학자(bioinformatician) 들이 필요하다.
- 가장 중요한 돌파구(Key breakthrough)는 이러한 2차 분석을 얼마나 빠르고, 싸고, (가장 중요하게는) 정확하게 할 수 있느냐 하는 것이다.
- 그리고 1 TB에 이르는 genome 데이터를 어떻게 다룰 것인가 (2차분석으로 조합(assemble)과정 이후에는 GB 단위로 줄어든다) 도 중요한 문제이다. 이러한 분석은 결국 빅데이터 (Big Data) 및 수퍼컴퓨터에 관련한 이슈이며, 최근의 기술혁신은 이러한 분석을 4시간 이하로 줄일 수 있는 노력을 하고 있다.
- 또한 특정 돌연변이(mutation)와 질병을 어떻게 연관지을 것인가 (Connecting the dots between genetic mutations and disease) 가 중요하다.
- 완성된 (Completed) genome과 그들의 genotype이 어떠한 생물학적인 의미/연관성(biological relevance), 혹은 질병/physical trait (phenotype) 과 관련이 있느ㄴ지를 분석하는 것으로, 이것을 3차 분석(tertiary analysis) 라고 부른다. 이 역시 빅 데이터와 관련한 문제(Big Data Problem) 이다.
- 지금까지 대부분의 genomic variation 은 해석되지 않은 상태에 있고, genetic variation 을 actionable plan으로 연결시킬 수 있는 예는 매우 적은 상태이다. 이는 사실 ‘닭과 달걀의 문제’로 더 많은 genome data와 disease population을 연구해야만 그러한 관계를 더욱 명확히 밝힐 수 있을 것이다.
- 이를 위해 Million Veteran Program 과 영국의 100K Genome Project 를 포함한 대량의 게놈 데이터(genomics dataset)를 만들어 내기 위한 프로젝트 들이 시행되고 있다.
- 누구든지 이러한 3차 분석을 정확히 할 수 있는 능력을 지닌 사람은 personalized medicine 시장에서 multi-billion 달러 규모의 기회를 잡게 될 것이다. 결국 시장 표준에 관한 문제이기도 하다.
3. Injecting genetic information into medical care
- 환자들의 genomic data, 돌연변이(mutation) 정보 들을 얻은 다음에 해야 할 일은 genomic data를 다른 의학적인 요소들 (환자의 병력, 환경, 가족력, 식습관 등등)과 결합하는 것이다. 또한 genomic data는 환자의 건강/진료 기록과 결합되어, 훈련 받은 전문의들이 여기에서 의학적인 통찰력을 얻을 수 있어야 한다. 여기에는 질병을 분자 수준 (molecular level)에서 재정의 하는 것이 포함된다. 이렇게 의학자들은 환자의 genome에 맞는 바이오마커, 약에 대한 반응 (drug response)을 이용할 수 있을 것이다.
- 하지만, 여기에 관한 다수의 장애물이 존재한다
- 먼저 이러한 분석을 위해 표준화된 프로토콜이 존재하지 않는다. 현재 너무 많은 데이터 베이스들이 따로 존재하고 있고, 서로 호환되지 않는다. 이러한 데이터들은 의과학자들이 쉽게 이용할 수 있도록 통합되어야 할 것이다.
- 더 중요한 장애물은, 현재의 전문의들은 genomic 정보를 분석/해석할 수 있도록 훈련되지 않았다는 것이다. 하지만 이 문제는 교육으로 해결할 수 있다.
- 비슷한 예로, 100년 전에 ‘파괴적 기술’ 이었던 방사선은 의학계에 새로운 분야를 열었다. 방사선과가 x-ray 필름을 읽는 것들 등에 표준을 마련하고, 의대에 이에 관한 전문의 교육과정이 생겼듯이 genomic data를 의학적으로 응용하는 것에도 이러한 변화가 일어날 것이다.
- 또한 genomic data를 통해서 새로운 진단법이나, 새로운 치료제를 개발하는 것에 대해서, 임상 승인 등의 문제가 있을 수 있다. 하지만 이런 문제들은 결국 해결할 수 있는 문제들 (ultimately surmountable hurdles) 이다.
4. Getting the big guys to pay for it
- Personalized Medicine을 현실화 하는 마지막 단계는 실행(implementation)하는 것이다. 헬스케어 분야의 관행들이나, 병원과 의사들의 역할, 치료제 등이 재정의 될 것이다. 여기서 중요한 장애물은 이러한 변화에 호의적인 경제 여건을 만드는 것이다. Whole genome sequencing (WGS) 을 표준적인 치료법(standard of care)으로 만들고, 의료 보험사들이 여기에 대해서 보험금을 지불해주는 것 등이 포함된다.
- 이미 WGS 이 공공의 건강(public health)에 도움이 되고, 헬스케어에 대한 사회적 비용을 낮출 수 있다는 것에 대한 다양한 연구들이 있다. 이러한 연구들이 지금은 소수일 수 있지만, 결국에는 수익과 비용절감이 실제로 가능하다는 것이 증명된다면 보험사들도 이에 수긍할 수 있을 것이다.
- 이에 관한 최근의 큰 진전은 미국의 주요 보험사인 Wellpoint 사나, Anthem Blue Cross 같은 보험사들이 유전자 검사(genetic test)에 대해서 보험금을 지급하기로 한 것이다.
- 블록버스터 신약도 재정의 될 것이다. 겉으로 보기에 다른 질병들(seemingly disparate disease) 이 실제로는 같은 돌연변이(molecular mutation)에 의해서 발병된다면, 공통의 분자 표적(common molecular target)에 작용하는 약을 처방할 수 있을 것이다.
결론: The revolution is coming!
- Sequencing의 발달에서 기인한 personalized medicine 혁명은 이미 일어나고 있다. 가격은 급격히 저렴해졌으며, 분석은 빨라졌다. 그 결과로 WGS은 결국 일용품(commodity)이 될 것이다. 하지만 그런만큼 우리 손에 주어지게 되는 genomic data 도 엄청나게 늘어날 것이다.
- 재능 있는 사람들과 투자들이 이미 이러한 혁신을 향하고 있다. 수퍼 컴퓨팅, 빅 데이터 그리고 Genomics의 교차점에 지금 거대한 기회가 있다.
- Personalized medicine은 당신이 생각하는 것보다 더욱 가까이 있다. 다만 학제간 접근법 (multidisciplinary approach)이 더욱 필요할 것이다.
Discover more from 최윤섭의 디지털 헬스케어
Subscribe to get the latest posts sent to your email.

![[칼럼] 국내 유전 정보 검사의 DTC 제한적 허용에 부쳐](https://www.yoonsupchoi.com/wp-content/uploads/2016/07/Screen-Shot-2016-07-16-at-12.00.19-PM-140x90.png)

















[…] 사람의 특정 유전자에 특허를 거는 것이 옳은 일일까요? 유전자 분석과 관련한 IT 기술의 급격한 발전에 따라, 개인의 유전체 분석에 필요한 시간과 비용이 급격히 줄어들어 […]